在多模态大模型不断追求更高参数量和更强性能的当下,效率与部署可行性正成为实际应用的关键瓶颈。许多视觉-语言模型(VLM)虽在基准测试中表现优异,但其高计算成本和长推理延迟,使其难以在手机、可穿戴设备或边缘硬件上运行。
为此,Liquid AI 推出 LFM2-VL ——其首个面向视觉-语言任务的高效基础模型系列。该模型并非一味堆叠参数,而是从架构设计出发,专为低延迟、低资源消耗和多平台边缘部署而优化。
LFM2-VL 在保持竞争力准确率的同时,将 GPU 推理速度提升至现有模型的 2 倍,并支持灵活的速度-质量权衡,适用于从嵌入式设备到单 GPU 实例的多种场景。
为什么需要高效的视觉-语言模型?
当前主流多模态模型通常面临三大现实挑战:
- 推理慢:图像编码和 token 处理开销大,响应延迟高;
- 显存占用高:难以在消费级设备上本地运行;
- 分辨率固定:依赖上采样或裁剪,导致细节失真或语义丢失。
LFM2-VL 的目标正是解决这些问题,提供一种实用、可控、可部署的替代方案,适用于以下场景:
- 手机端图像理解与问答;
- AR/VR 设备中的实时视觉交互;
- 工业边缘设备上的自动化视觉分析;
- 隐私敏感场景下的本地化多模态推理。
LFM2-VL 的两大型号
LFM2-VL 提供两个版本,覆盖不同资源需求:
| 型号 | 参数量 | 适用场景 |
|---|---|---|
| LFM2-VL-450M | ~4.5 亿 | 高度资源受限环境(如移动设备、嵌入式系统) |
| LFM2-VL-1.6B | ~16 亿 | 性能优先但仍需轻量化的场景(如笔记本、单 GPU 服务器) |
两者均基于 Liquid AI 开源的 LFM2 系列语言模型构建,继承其高效推理特性,并通过模块化设计实现跨平台兼容。
核心架构:三组件协同设计
LFM2-VL 采用经典的“双塔+投影器”结构,包含三个关键组件:
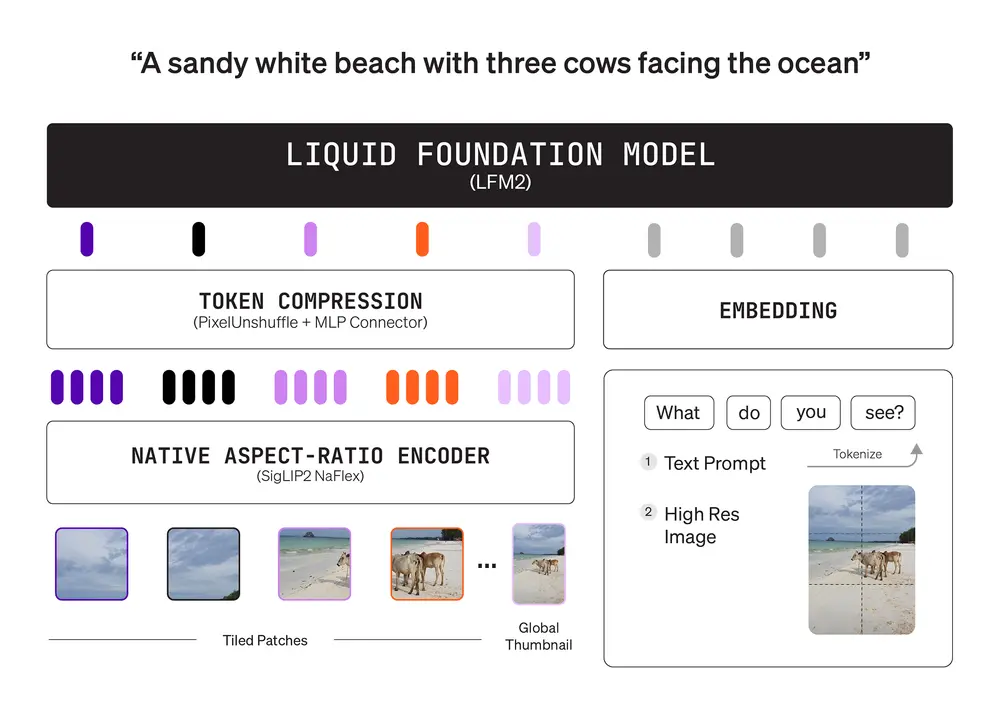
1. 语言模型塔:基于 LFM2 骨干
- LFM2-VL-1.6B 使用 LFM2-1.2B 作为语言骨干;
- LFM2-VL-450M 使用更小的 LFM2-350M;
- 继承 LFM2 的高效注意力机制,在生成阶段显著降低解码开销。
2. 视觉编码器:SigLIP2 NaFlex,支持原生分辨率处理
视觉塔采用 SigLIP2 架构,并引入 NaFlex 变体以适应不同规模:
| 型号 | 编码器版本 | 参数量 | 特点 |
|---|---|---|---|
| LFM2-VL-1.6B | 形状优化版 | ~400M | 更细粒度特征提取,适合高精度任务 |
| LFM2-VL-450M | 基础版 | ~86M | 快速编码,适合低延迟场景 |
关键能力:
- 支持高达 512×512 的原生分辨率输入,避免低分辨率图像因上采样导致的伪影;
- 对非标准宽高比图像无失真处理;
- 超大图像(如 1000×3000)被自动分割为 512×512 非重叠补丁,保留细节;
- 在 LFM2-VL-1.6B 中,额外引入一个缩略图分支,提供全局上下文,增强整体语义对齐。
每个图像补丁由特殊 token 标记位置,确保模型理解空间布局。
3. 多模态投影器:带像素解混的 MLP 连接器
为减少图像 token 数量、提升吞吐量,LFM2-VL 采用一个 2 层 MLP 投影器,结合“像素解混”策略:
- 将视觉编码器输出的 token 映射到语言模型的隐空间;
- 动态控制图像 token 数量,例如:
- 256×384 图像 → 96 个 token
- 384×680 图像 → 240 个 token
- 1000×3000 图像 → 1020 个 token
这种设计在不显著损失质量的前提下,大幅降低计算负担。
训练策略:渐进式融合 + 强化视觉理解
LFM2-VL 的训练分为两个阶段:
1. 联合中期训练(Interleaved Pretraining)
- 初始阶段以文本数据为主(文本:图像 = 95:5);
- 逐步过渡到多模态平衡状态(30% 图像数据);
- 总训练数据约 1000 亿多模态 token,来源包括开源数据集与内部合成数据,覆盖图像描述、视觉问答、OCR 等任务。
2. 监督微调(SFT)
- 重点强化图像理解能力;
- 使用高质量指令数据进行对齐训练;
- 强调细节描述、空间关系推理和复杂场景理解。
整个训练过程充分利用 LFM2 的预训练先验,实现快速收敛与稳定性能。
性能表现:效率与质量兼顾
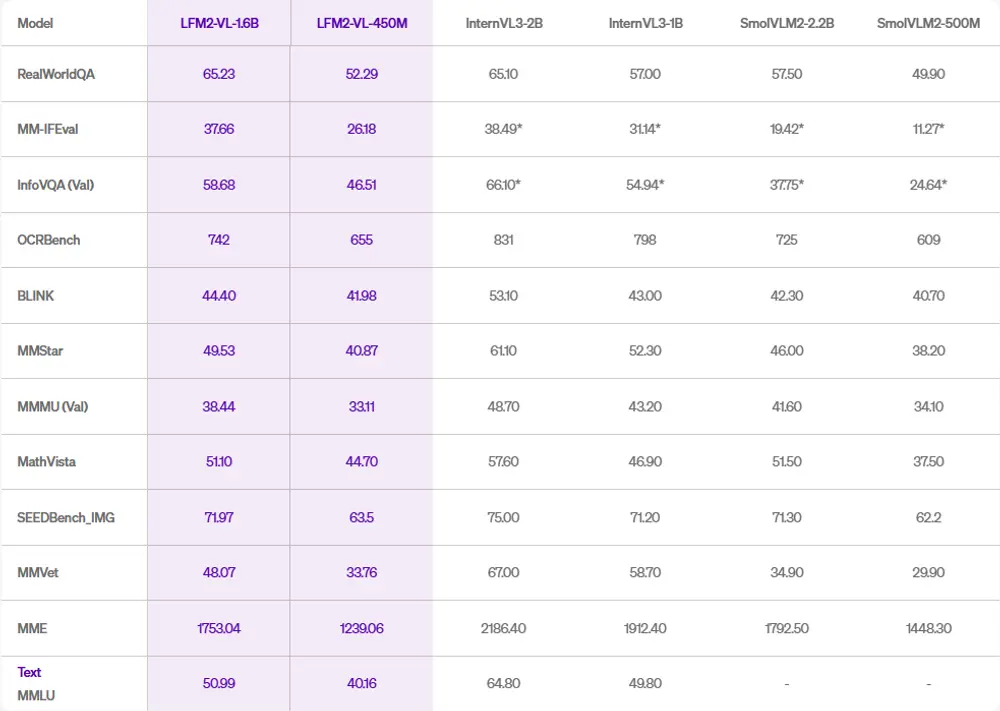
1. 基准测试:多任务表现均衡
LFM2-VL 在多个公开视觉-语言基准上表现良好,尤其在高分辨率图像理解和多模态指令跟随任务中优势明显,同时在传统 VQA、图像描述等任务上保持竞争力。
2. 推理速度:GPU 上快达 2 倍
测试配置:输入一张 1024×1024 图像 + 简短提示(如“详细描述此图像”),生成 100 个 token。
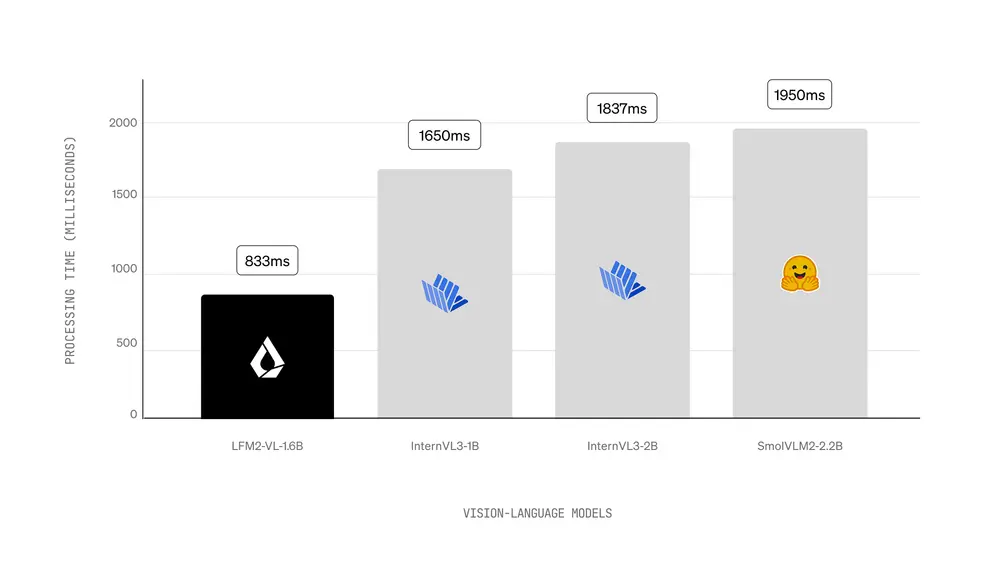
结果表明:
- LFM2-VL 在相同准确率水平下,推理速度达到当前最快同类模型的 2 倍;
- 更少的图像 token 和高效的语言骨干共同贡献了这一优势;
- 支持批处理和动态 batching,进一步提升吞吐量。
灵活性:用户可控的速度-质量权衡
LFM2-VL 的一大亮点是无需重新训练即可调整推理行为。用户可在推理时动态控制:
- 最大图像 token 数量:限制输入分辨率,降低延迟;
- 图像补丁数量:决定是否对大图进行分块处理;
- 缩略图使用开关:在速度与全局理解间权衡。
这一设计使得开发者可根据具体应用场景(如实时交互 vs. 离线分析)灵活优化性能。
开源与部署支持
LFM2-VL 模型已发布于 Hugging Face,并附带 Colab 示例代码,支持快速微调与部署。
开源许可(Apache 2.0)
- 允许学术与研究用途;
- 年收入 < 1000 万美元的企业可免费用于商业场景;
- 更大规模企业需联系 Liquid AI 获取商业授权。
部署友好性
- 兼容 Hugging Face
transformers和TRL框架; - 支持本地运行,保障数据隐私;
- 正在集成至主流推理引擎(如 ONNX、TensorRT),便于边缘部署;
- 支持 LEAP 工具链,实现跨平台优化(移动端、Web、嵌入式)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











