
Meta 近日推出 Segment Anything 系列新一代模型——SAM 3,首次实现文本、图像示例双提示驱动的开放式概念分割,可精准识别并分割“带红色条纹的雨伞”等细粒度概念,在图像与视频分割任务上性能较现有系统提升 2 倍。此次发布同步开源模型权重、评估数据集与微调代码,推出零门槛交互式平台,并落地于 Meta 多款产品及科学研究场景,进一步巩固其在计算机视觉分割领域的领先地位。
- 项目主页:https://ai.meta.com/sam3
- GitHub:https://github.com/facebookresearch/sam3
- 模型:https://huggingface.co/facebook/sam3
- Demo:https://segment-anything.com
SAM 3.1
SAM 3 是 Meta 推出的一个统一基础模型,用于图像和视频中的可提示分割。它使用文本或视觉提示来检测、分割和跟踪对象。SAM 3 引入了能够全面分割由短文本短语指定的开放词汇概念的所有实例的能力,处理的独特概念数量是现有基准测试的 50 倍以上。SAM 3.1 在此基础上引入了 Object Multiplex,这是一种用于联合多对象跟踪的共享内存方法,在单张 H100 GPU 上处理 128 个对象时,推理速度提升约 7 倍,且不牺牲准确性,同时在 7 个基准测试中的 6 个上改进了视频对象分割性能。
- 模型:https://huggingface.co/facebook/sam3.1
核心亮点:不止于分割,多模态+低门槛+广落地
- 多模态提示能力:支持文本提示(开放词汇短名词短语)、图像示例提示,结合 SAM 1/2 已有的掩码、框、点等视觉提示,突破固定标签集限制,实现“万物可分割”;
- 性能阶跃式提升:在自研 SA-Co 基准测试中,图像与视频的概念分割性能较现有系统翻倍,30 毫秒内可处理含 100+ 对象的单图像,视频跟踪支持近实时性能;
- 全链路开源生态:开源模型检查点、SA-Co 评估基准、微调代码,与 Roboflow 合作简化数据标注、微调与部署流程;
- 零门槛交互体验:推出 Segment Anything 交互式平台,支持上传图像/视频或使用模板,一键实现创意编辑与数据标注;
- 多场景产品落地:赋能 Facebook Marketplace“室内实景查看”、Meta AI 应用 Vibes 功能、Edits 视频特效工具,同时应用于野生动物监测、海洋探索等科学领域。

技术突破:解决开放式概念分割核心痛点
1. 提示式概念分割:打破固定标签限制
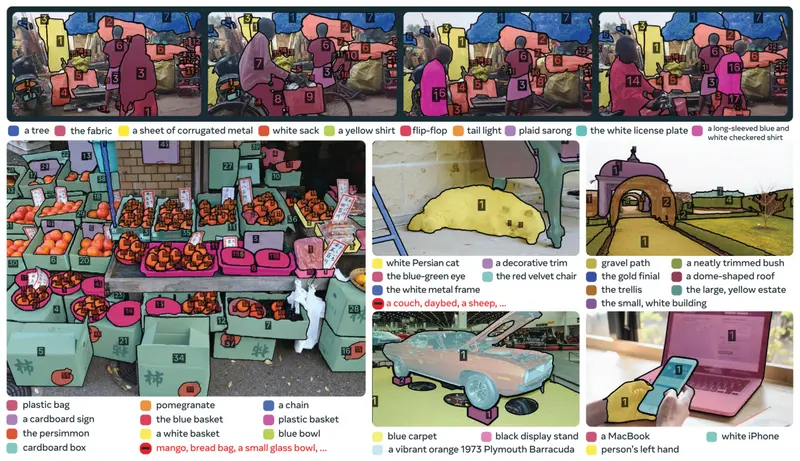
传统分割模型仅能识别预设标签(如“人”“车”),无法处理细粒度、个性化需求(如“坐着的人但手里没拿礼品盒”)。SAM 3 通过“提示式概念分割”技术,实现:
- 文本提示:支持开放词汇短名词短语(如“带红色条纹的雨伞”“精装书”),直接分割用户描述的概念;
- 图像示例提示:通过上传示例图像,分割场景中所有同类物体,适配难以用文本描述的罕见概念;
- 多模态组合:可作为大语言模型的感知工具,处理复杂推理类提示,例如“图片中用于控制和引导马的物体”。
2. 数据引擎创新:AI+人类协同,效率提升 2 倍+
为解决高质量标注数据稀缺的行业痛点,Meta 构建了“AI+人类”闭环数据引擎:
- 自动化预处理:通过 SAM 3 与 Llama 3.2V 模型流水线,自动挖掘图像/视频、生成标题、解析标签、创建初始分割掩码;
- AI 标注员校验:由 Llama 3.2V 训练的 AI 标注员验证掩码质量、过滤简单样本,匹配人类准确性;
- 人类聚焦难点:仅将复杂、模型失败的案例交给人类标注,负提示标注速度比人类快 5 倍,正提示快 36%;
- 概念本体扩展:基于 Wikipedia 构建概念关系字典,覆盖 400 万+ 独特概念,提升罕见概念的覆盖度。
通过这一模式,数据标注吞吐量较纯人工提升 2 倍,同时保证数据多样性与高质量,为模型泛化能力奠定基础。
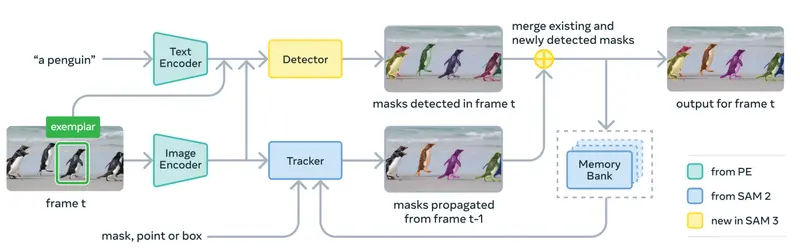
3. 模型架构:多模态融合+高效推理
SAM 3 整合 Meta 多项前沿技术,实现性能与效率的平衡:
- 编码器基础:采用 Meta Perception Encoder(开源多模态编码器),提升语言与视觉的对齐能力;
- 检测器组件:基于 DETR 模型,优化目标检测与分割的端到端流程;
- 跟踪器模块:复用 SAM 2 的记忆库与记忆编码器,支持视频中对象的连续跟踪;
- 推理优化:单图像处理仅需 30 毫秒(H200 GPU),视频跟踪随对象数量线性缩放,5 个并发对象可保持近实时。
性能表现:多项指标刷新行业基准
| 测试场景 | 核心表现 | 优势亮点 |
|---|---|---|
| SA-Co 图像/视频分割 | 较现有系统性能提升 2 倍(cgF1 分数) | 超越 Gemini 2.5 Pro、OWLv2 等主流模型 |
| 用户偏好测试 | 对最强基线 OWLv2 的偏好度达 3:1 | 分割效果更贴合人类直觉 |
| 交互式视觉分割 | 匹配/超越 SAM 2 最先进性能 | 兼容原有视觉提示(点、框、掩码) |
| 复杂推理分割(ReasonSeg) | 未专门训练却超越先前工作 | 与大语言模型联动,支持推理类需求 |
| 推理速度 | 单图像 30 毫秒(100+ 对象),视频近实时 | 适配高并发、低延迟场景 |

开源与生态:降低开发门槛,支持个性化适配
1. 开源资源清单
- 模型资产:SAM 3 模型检查点(支持文本/图像提示);
- 评估基准:SA-Co 数据集(图像/视频提示式概念分割,词汇量更大、难度更高);
- 开发工具:微调代码、部署教程,支持快速适配新场景;
- 合作生态:与 Roboflow 合作,提供数据标注、微调、部署一站式服务。
2. 个性化适配方案
针对细粒度、专业领域(如医学影像“血小板”识别),SAM 3 支持少量标注数据微调,快速适应新领域;同时提供完整的微调指南,帮助社区拓展模型能力边界。
应用场景:从创意工具到科学研究
1. 消费级产品落地
- Facebook Marketplace“室内实景查看”:结合 SAM 3D 技术,可视化家居用品在真实空间的摆放效果;
- Edits 视频特效:一键对视频中特定人物/物体应用动态特效,简化复杂编辑流程;
- Meta AI 应用 Vibes:支持 AI 视觉创作与视频混音,提升创意表达效率;
- 可穿戴设备适配:在 Aria Gen 2 研究眼镜的第一人称镜头中,实现动态场景的鲁棒分割与跟踪。
2. 科学与公益领域
- 野生动物监测:与 Conservation X Labs 合作推出 SA-FARI 数据集,含 10,000+ 相机陷阱视频,100+ 物种的分割标注;
- 海洋探索:为 FathomNet 数据库提供水下影像分割掩码与实例分割基准,助力海洋研究;
- 机器人与情境 AI:从人类视角理解世界,为机器感知、机器人交互提供技术支撑。
交互式平台:零门槛体验尖端分割技术
Segment Anything 交互式平台是 SAM 3 的核心体验入口,无需技术背景即可上手:
- 核心功能:上传图像/视频,通过文本/示例提示实现分割、添加特效(聚光灯、运动轨迹)、数据标注(像素化面部/车牌);
- 模板支持:提供实用编辑模板与创意特效模板,同时支持压力测试模型性能;
- 特色展示:集成 Aria Gen 2 试点数据集的第一人称镜头,展示 SAM 3 在动态场景中的表现。
现有局限与未来方向
已知限制
- 零样本泛化能力:对医学、科学等专业领域的细粒度概念(如“血小板”)泛化不足,需微调适配;
- 复杂提示支持:暂不直接支持长文本、空间描述类提示(如“顶层书架从右数第二本书”),需与大语言模型联动;
- 视频跟踪效率:跟踪成本随对象数量线性缩放,缺乏对象间上下文通信,复杂场景中性能待优化。
未来探索
- 扩展复杂提示理解:增强长文本、推理类提示的直接处理能力;
- 优化视频跟踪架构:引入对象级共享上下文,提升多相似对象场景的效率与精度;
- 深化跨领域适配:推动模型在更多专业领域的落地,拓展科学研究与工业应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











