
在OCR领域常陷入“大参数换高性能”的内卷时,腾讯混元于11月25日开源的HunyuanOCR,以1B的轻量化参数实现了颠覆性突破。这款依托混元原生多模态架构打造的端到端OCR专家模型,不仅在多项权威测评和赛事中斩获SOTA成绩,还凭借全场景适配、极致易用等优势,大幅降低了高精度OCR技术的部署与使用成本,为个人开发者、中小企业乃至行业级应用提供了高性价比的解决方案。目前用户可通过Hugging Face空间直接体验该模型的各项功能。
- 项目主页:https://hunyuan.tencent.com/vision/zh?tabIndex=0
- GitHub:https://github.com/Tencent-Hunyuan/HunyuanOCR
- 模型:https://huggingface.co/tencent/HunyuanOCR

硬核成绩:轻量化参数创下多项行业顶尖水平
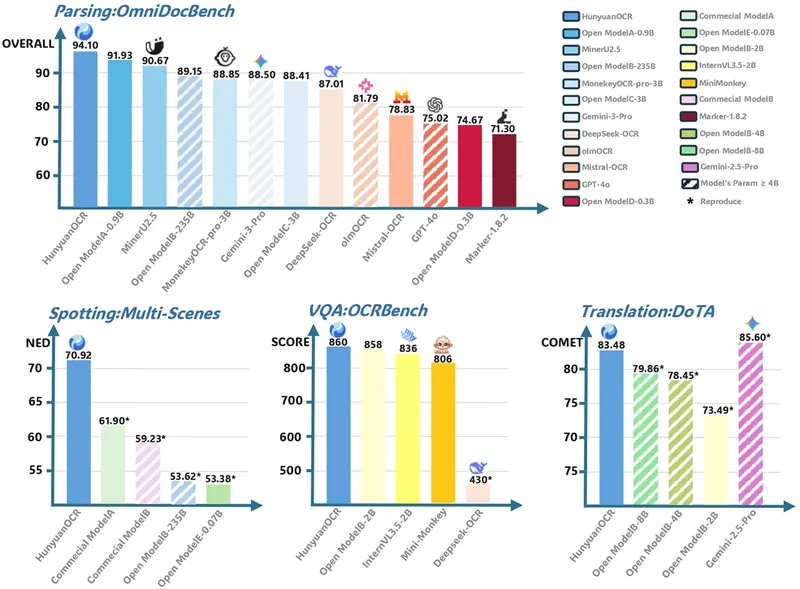
HunyuanOCR最亮眼的地方,在于以远低于行业同类模型的参数规模,实现了碾压级的性能表现,在权威测评和赛事中屡屡突围:
- 复杂文档解析登顶:在复杂文档解析领域的OmniDocBench测评中,它拿下94.1分的最高分,这一成绩直接超越了谷歌Gemini3 - pro等一众行业领先模型。其解析能力十分全面,能将多语种文档扫描件或拍摄图电子化,文本按阅读顺序梳理,公式转为Latex格式,复杂表格生成HTML格式,适配专业学术与商务文档处理场景。
- 综合能力领跑小参数阵营:在OCRBench榜单上,HunyuanOCR以860分的总成绩,成为总参数3B以下(含通用视觉理解模型)的SOTA持有者。要知道其参数仅1B,这种“小身材爆发出大能量”的表现,打破了参数体量与性能强绑定的固有认知。
- 小语种翻译夺冠:在ICDAR2025端到端文档翻译比赛的小模型赛道中成功夺冠,它能支持14种高频小语种与中文、英文的互译,精准解决跨境文档沟通中的语言障碍。
- 全场景检测识别领先:在腾讯自建的覆盖文档、艺术字、街景、手写、广告等9大主流应用场景的基准测试中,其文字检测和识别能力大幅超越同类开源模型及商业OCR模型,轻松应对日常与专业场景中的复杂文字形态。
技术内核:三大组件+端到端范式筑牢优势
HunyuanOCR的高性能并非偶然,其核心得益于独特的架构设计与训练范式,既保证了性能,又控制了模型体量:
- 三大核心组件构建基础:模型由原生分辨率视频编码器、自适应视觉适配器和轻量化混元语言模型三部分组成。这种架构既能精准捕捉图像中的文字细节与时空信息,又能通过语言模型强化对多语种文字的理解,适配从图片到视频的多类文本载体。
- 端到端范式提升效率:区别于业界常见的级联方案,HunyuanOCR的训练和推理全程采用全端到端范式。加上规模化高质量应用导向数据的喂养和在线强化学习的加持,模型仅需单次前向推理,就能完成从文字检测到信息输出的全流程,不仅减少了中间环节的误差,还大幅提升了处理效率。
- 轻量化设计降低门槛:通过混元原生多模态架构与专属训练策略,在将参数控制在1B的同时,没有牺牲核心性能。这种轻量化特性让模型部署成本大幅降低,无论是个人开发者的电脑,还是中小企业的轻量化服务器,都能顺畅运行。
全场景适配:覆盖从日常到专业的多元需求
凭借强大的综合能力,HunyuanOCR打破了单一OCR模型的场景局限,能从容应对多类实用需求,适配不同行业与人群:
| 应用场景 | 具体作用 | 适用人群/行业 |
|---|---|---|
| 多语种文档处理 | 解析百余种语言的文档,完成文本、公式、表格的规范化电子化 | 外贸企业、学术科研人员、跨国办公群体 |
| 卡证票据处理 | 精准抽取票据、证件中的关键字段,减少人工录入工作量 | 财务会计、行政办公、金融机构柜员 |
| 视频相关处理 | 高效识别视频、游戏画面中的字幕与文字,适配二次创作与内容审核 | 自媒体创作者、游戏运营、视频平台审核员 |
| 日常文字识别 | 搞定手写、街景、广告、截屏等场景的文字提取,解决生活与工作中的文字采集需求 | 普通职场人、学生、线下商户 |
| 端到端翻译 | 实现小语种与中英文的文档级翻译,无需额外搭配翻译工具 | 跨境电商从业者、外语学习者、外事工作人员 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











