
在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是“看到”画面,是当前多模态智能的一大挑战。
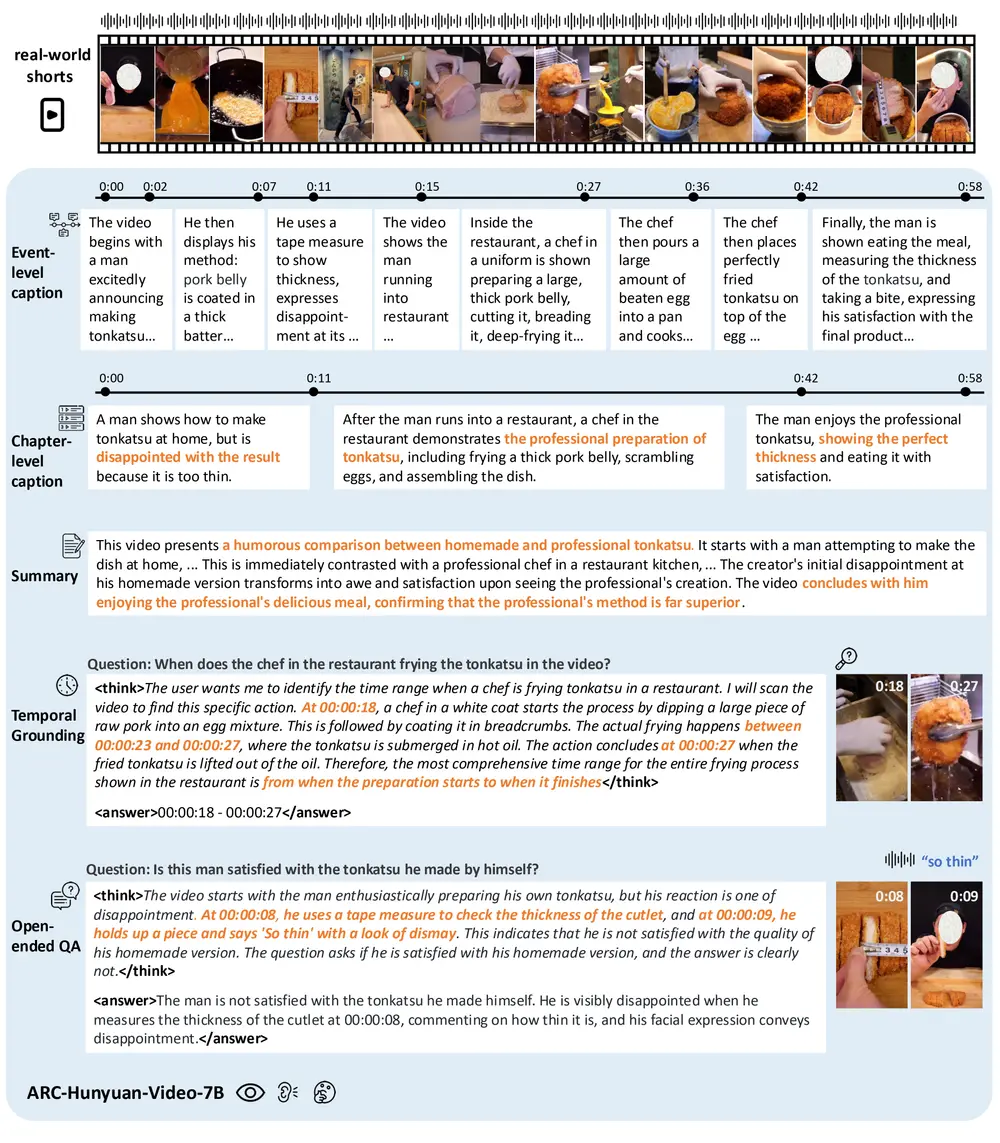
为此,腾讯ARC实验室推出 ARC-Hunyuan-Video-7B —— 一个专为现实世界短视频理解设计的端到端多模态大模型。它不仅能描述画面,更能理解创作者的意图、情感表达和事件脉络,甚至能精准回答“某句话出现在第几秒”这类时间敏感问题。
- GitHub:https://github.com/TencentARC/ARC-Hunyuan-Video-7B
- 模型:https://huggingface.co/TencentARC/ARC-Hunyuan-Video-7B
- API:https://arc.tencent.com/zh/document/ARC-Hunyuan-Video-7B
该模型现已开源,包含模型检查点、推理代码与API接口,支持中英文视频理解,尤其中文表现突出。
为什么需要专门的短视频理解模型?
现有的多模态模型多聚焦于图像描述或长视频摘要,但在面对真实用户生成内容(UGC)时存在明显短板:
- 信息高度浓缩:15秒内可能包含多个情节转折、观点表达或产品演示;
- 依赖音频线索:许多视频无字幕,关键信息通过口语传递;
- 情感与主观性强:创作者意图常隐含在语气、节奏和剪辑中;
- 时间敏感任务需求多:如精彩片段提取、时间定位、结构化标注等。
传统方法往往将视频切帧后单独处理,丢失了时间连续性与音画协同信息。而 ARC-Hunyuan-Video-7B 的目标,正是解决这些问题。
核心能力:从“看到”到“理解”
1. 联合视音频推理,突破单模态局限
ARC-Hunyuan-Video-7B 配备独立音频编码器,实现精细的视音频同步融合。模型在同一时间窗口内对齐视觉帧与音频信号,从而理解仅靠画面无法捕捉的信息。这种能力使其在短剧理解、评论分析、反讽识别等任务上表现优异。
2. 精准时间感知,实现结构化理解
时间是视频的核心维度。ARC-Hunyuan-Video-7B 引入时间戳覆盖机制:在输入阶段,直接将格式化时间(HH:MM:SS)叠加在每一帧上,作为显式时间信号。
由此,模型具备以下能力:
- 多粒度时间戳标注(如“00:01:23 - 开始介绍产品功能”)
- 时间视频定位(回答“他说‘买它’是在什么时候?”)
- 分段摘要生成(按事件划分并标注起止时间)
这一设计为视频搜索、精彩片段提取、内容审核等应用提供了结构化输出基础。
3. 深层主题与创意分析
除了事实性描述,ARC-Hunyuan-Video-7B 还能进行高级语义推理:
- 识别视频主题(如“职场焦虑”、“亲子关系”)
- 分析情感基调(积极、讽刺、怀旧)
- 解读叙事结构(起承转合、悬念设置)
- 评论创作手法(对比剪辑、象征意象)
4. 长视频结构化处理,效率惊人
尽管主要面向短视频(<5分钟),ARC-Hunyuan-Video-7B 也可处理长达40分钟的视频。其策略为:
- 将长视频按5分钟分段;
- 并行调用模型进行逐段推理;
- 使用大语言模型(LLM)整合各段结果,生成全局摘要。
得益于 vLLM 加速推理,整个流程在 H20 GPU 上仅需 不到3分钟,平均生成约500个token。这一效率使其具备实际部署潜力。

技术实现:四大关键设计
ARC-Hunyuan-Video-7B 基于 Hunyuan-7B 视觉语言模型构建,通过以下四项关键技术支撑其能力:
1. 精细视音频同步
- 引入独立音频编码器(如 Whisper 风格结构)
- 在时间粒度上对齐视觉帧与音频片段
- 融合生成统一的多模态表示
确保语音内容不因低帧率采样而丢失。
2. 显式时间感知机制
- 在视觉输入前,将时间戳(如
12:34:56)作为文本前缀叠加至对应帧 - 模型在训练中学习将事件与时间绑定
- 支持毫秒级精度的时间定位任务
简单有效,无需复杂位置编码。
3. 自动化引导式标注流程
- 收集数百万真实短视频(来自微信视频号等平台)
- 构建全自动标注 pipeline:利用模型自身初步输出生成候选标签
- 通过过滤、对齐、增强形成高质量训练数据
实现低成本、大规模、领域对齐的数据构建。
4. 全面多阶段训练机制
采用包含监督微调(SFT)与强化学习(RL) 的混合训练策略:
- SFT 阶段:学习基本描述与时间标注能力
- RL 阶段:以任务目标(如问答准确率、摘要相关性)为奖励信号,优化主观理解质量
实验证明,RL 训练显著提升模型在创意分析与意图识别任务上的表现。
开放能力与API服务
腾讯已开源 ARC-Hunyuan-Video-7B,提供:
- 模型检查点(Hugging Face)
- 推理代码(GitHub)
- API 接口(支持 vLLM 加速)
同时发布两个版本:
| 版本 | 功能 | 适用场景 |
|---|---|---|
| ARC-Hunyuan-Video-7B | 支持中英文,具备时间标注、问答、推理等完整能力 | 多语言、高阶任务 |
| ARC-Hunyuan-Video-7B-V0 | 仅支持中文视频描述与摘要 | 轻量级中文应用 |
⚠️ 注意:
由于API存在文件大小限制,线上演示对视频进行了分辨率压缩,性能可能略低于论文报告值。如需复现原始效果,建议本地部署。
未来方向:专注现实世界数据
研究团队发现,引入通用视频数据集(如WebVid)可能反而损害模型对真实UGC的理解能力,原因可能是:
- 领域偏移(影视剪辑 vs 用户实拍)
- 噪声干扰(非自然场景、脚本化表达)
因此,未来工作将聚焦于:
- 构建严格筛选的现实世界视频数据集
- 训练更专一、更鲁棒的垂直模型
- 提升在低质量、弱信号场景下的稳定性
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











