面壁智能正式推出其最新视觉语言模型 MiniCPM-V 4.5,这是 MiniCPM-V 系列中性能最强、功能最全面的版本。该模型在保持 80 亿参数规模的前提下,实现了在视觉理解、视频处理、文档解析和多语言支持等方面的显著提升,成为当前开源社区中极具竞争力的端侧多模态解决方案。
- GitHub:https://github.com/OpenBMB/MiniCPM-o/blob/main/README_zh.md
- 模型:https://huggingface.co/collections/openbmb/minicpm-o-and-minicpm-v-65d48fa84e358ce02a92d004
更强性能:以小搏大,超越主流大模型
MiniCPM-V 4.5 基于 Qwen3-8B 和 SigLIP2-400M 架构构建,在 OpenCompass 综合评测中取得了 77.2 的平均分(基于 8 个主流基准),在视觉-语言任务上的表现不仅超越了 GPT-4o-latest、Gemini-2.0 Pro 等闭源模型,也优于 Qwen2.5-VL 72B 这类超大规模开源模型。

这一成绩使其成为 300 亿参数以下最强大的开源多模态模型之一,为资源受限环境下的高性能部署提供了新的可能性。
视频理解升级:高帧率与长视频支持更高效
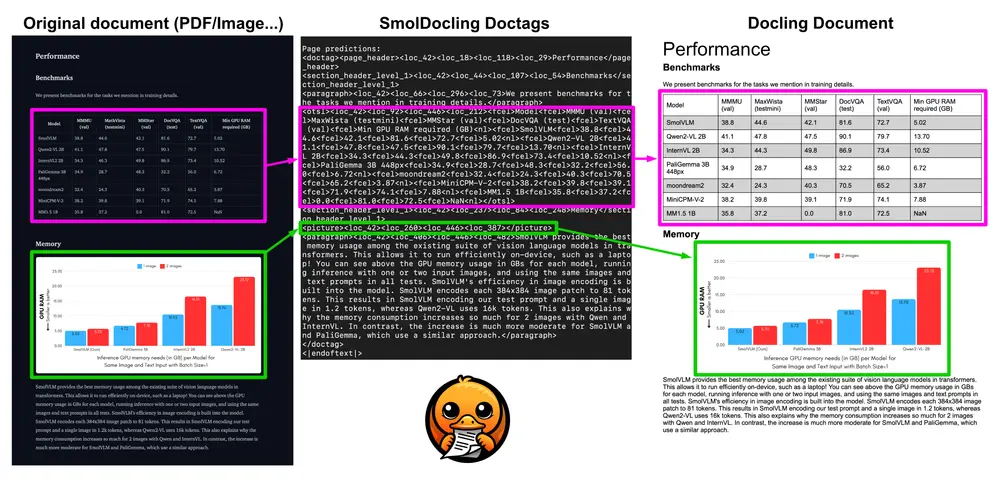
传统多模态模型在处理视频时面临计算开销大、帧率低的问题。MiniCPM-V 4.5 引入了全新的 统一 3D-Resampler 模块,实现了对图像与视频的统一处理。
关键改进包括:
- 视频 token 压缩率最高可达 96 倍
- 6 个 448×448 的视频帧仅需生成 64 个视觉 token(常规模型需约 1,536 个)
- 支持高达 10FPS 的高刷新率视频理解
- 显著提升长视频建模能力
在 Video-MME、LVBench、MLVU、MotionBench 和 FavorBench 等多个视频理解基准上,MiniCPM-V 4.5 均达到当前开源模型中的领先水平,且推理成本更低。
智能思考模式:快与深的自由切换
为适应不同使用场景,MiniCPM-V 4.5 支持两种推理模式:
- 快速思考模式:适用于高频、轻量级任务,响应迅速,性能稳定;
- 深度思考模式:针对复杂推理、细节分析等任务,提供更强的理解与生成能力。
两种模式可在应用层面灵活切换,帮助开发者在效率与精度之间实现精准平衡。
文档与 OCR 能力全面增强
MiniCPM-V 4.5 继承并优化了 LLaVA-UHD 架构,具备以下优势:
- 支持任意宽高比的高分辨率图像输入,最高可达 1344×1344(约 180 万像素)
- 所需视觉 token 数量仅为同类模型的 1/4
- 在 OCRBench 上表现优于 GPT-4o-latest 与 Gemini 2.5,尤其在手写体识别方面表现突出
- 在 OmniDocBench 上实现当前开源模型中最优的 PDF 文档结构解析能力
此外,模型通过 RLAIF-V 与 VisCPM 技术训练,具备更高的输出可信度,在 MMHal-Bench 上同样超越 GPT-4o-latest。

多语言支持与端侧部署友好
MiniCPM-V 4.5 支持 超过 30 种语言,覆盖中文、英文及多种主流语种,适合国际化应用场景。
更重要的是,它延续了 MiniCPM 系列一贯的“端侧友好”设计原则:
- 可在手机、平板、笔记本等本地设备运行
- 提供 int4、GGUF、AWQ 等多种量化格式(共 16 种模型大小)
- 支持 llama.cpp、Ollama 实现 CPU 高效推理
- 兼容 SGLang、vLLM 实现服务端高吞吐部署
- 支持 Transformers 与 LLaMA-Factory 微调,便于领域定制
开箱即用:多种使用方式任选
为降低使用门槛,MiniCPM-V 4.5 提供了丰富的接入方式:
- 本地运行:通过 llama.cpp 或 Ollama 在 PC/Mac 上直接部署
- 移动端体验:专为 iPhone/iPad 优化的本地应用,保障隐私与响应速度
- 服务端部署:支持 vLLM/SGLang 高并发推理
- 模型微调:兼容主流框架,支持领域适配训练
- 快速体验:提供本地 WebUI 演示与在线 Web 版本
- 完整文档:配套 Cookbook 提供详细使用指南
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











