
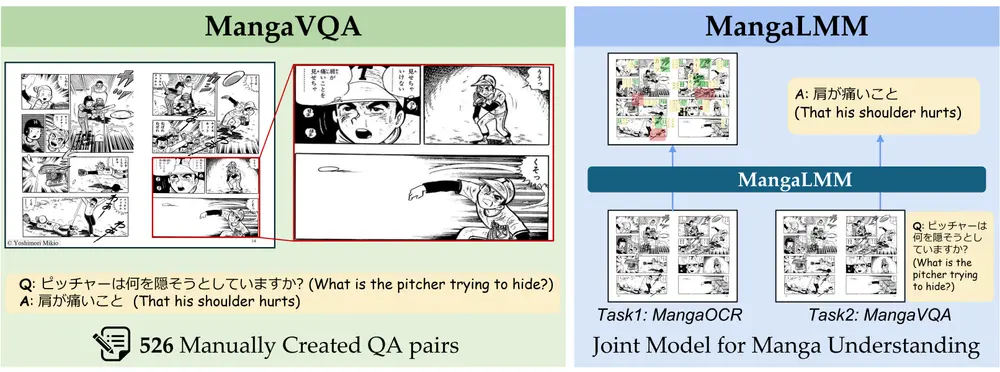
东京大学的研究人员推出一个名为 MangaVQA 的基准测试和一个名为 MangaLMM 的专门模型,用于多模态漫画理解。漫画(Manga)是一种将图像和文本以复杂方式结合的叙事形式,理解漫画需要同时处理视觉和文本信息。MangaVQA 包含 526 个高质量的手工构建的问题-答案对,用于评估模型在多样化叙事和视觉场景中的上下文理解能力。
- GitHub:https://github.com/manga109/MangaLMM
- 模型:https://huggingface.co/hal-utokyo/MangaLMM
- Demo:https://huggingface.co/spaces/alfredplpl/MangaLMM-Demo
MangaLMM 是基于开源多模态模型 Qwen2.5-VL 微调而成的,专门用于处理漫画中的光学字符识别(OCR)和视觉问答(VQA)任务。通过广泛的实验,论文展示了 MangaLMM 在这两个任务上的表现,并与现有的专有模型(如 GPT-4o 和 Gemini 2.5)进行了比较。
主要功能
- 多模态漫画理解:通过 OCR 和 VQA 任务,评估模型对漫画的理解能力。
- 基准测试:提供 MangaOCR 和 MangaVQA 两个基准测试,分别用于评估漫画中的文本识别和上下文理解。
- 专门模型:开发 MangaLMM,一个专门用于漫画理解的模型,能够同时处理 OCR 和 VQA 任务。
- 合成数据生成:使用 GPT-4o 生成合成 VQA 数据,用于模型训练。
主要特点
- 多模态理解:MangaVQA 评估模型对漫画中视觉和文本信息的综合理解能力。
- 高质量基准:MangaVQA 包含 526 个手工构建的问题-答案对,覆盖多样化场景。
- 开源模型:MangaLMM 基于开源模型 Qwen2.5-VL 微调而成,易于复现和扩展。
- 合成数据:通过 GPT-4o 生成合成 VQA 数据,提高模型训练的多样性和质量。
工作原理
- MangaOCR:通过检测和识别漫画中的文本内容(如对话和拟声词),评估模型的 OCR 能力。
- MangaVQA:通过提出与漫画内容相关的问题,评估模型对漫画的上下文理解能力。
- MangaLMM:基于 Qwen2.5-VL 微调,联合处理 OCR 和 VQA 任务。使用 MangaOCR 数据集进行 OCR 训练,使用合成 VQA 数据进行 VQA 训练。
- 合成数据生成:使用 GPT-4o 根据漫画图像和 OCR 注释生成合成 VQA 数据,提高训练数据的多样性和质量。
测试结果
- OCR 性能:MangaLMM 在 MangaOCR 基准测试中达到了 71.5% 的 Hmean(和谐平均值),显著优于其他模型。
- VQA 性能:MangaLMM 在 MangaVQA 基准测试中达到了 6.57 的 LLM 评分(满分 10),优于 GPT-4o 的 5.76。
- 模型比较:与 GPT-4o 和 Gemini 2.5 等专有模型相比,MangaLMM 在 OCR 和 VQA 任务上均表现出色。
- 数据集大小影响:随着训练数据集大小的增加,模型性能逐渐提高。
- 模型大小影响:7B 模型在 OCR 和 VQA 任务上的表现优于 3B 模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











