面壁智能正式推出MiniCPM-o系列最新旗舰模型——MiniCPM-o 4.5。这款总参数量仅9B的端侧多模态大模型(MLLM),基于SigLip2、Whisper-medium、CosyVoice2与Qwen3-8B端到端联合构建,在视觉、语音能力上实现大幅跃升,更首次原生支持全双工多模态实时流,可在手机等终端设备上实现“边看、边听、边说”的实时交互,综合能力达到Gemini 2.5 Flash级别,为端侧AI交互树立全新标杆。
- GitHub:https://github.com/OpenBMB/MiniCPM-o
- Hugging Face:https://huggingface.co/collections/openbmb/minicpm-o-and-minicpm-v
- 魔塔:https://modelscope.cn/collections/OpenBMB/MiniCPM-o-4-5
核心定位:端侧轻量化全模态旗舰,对标国际顶级闭源模型
MiniCPM-o 4.5是面壁智能在多模态大模型领域的最新突破,定位为手机端可运行、全双工实时交互、多模态能力均衡的轻量化旗舰模型。其核心优势在于以9B的小参数规模,实现了接近Gemini 2.5 Flash的综合性能,同时打破传统多模态模型“先输入后输出”的串行限制,原生支持视频、音频、文本的实时流处理与并行输出,彻底重构端侧AI交互体验。
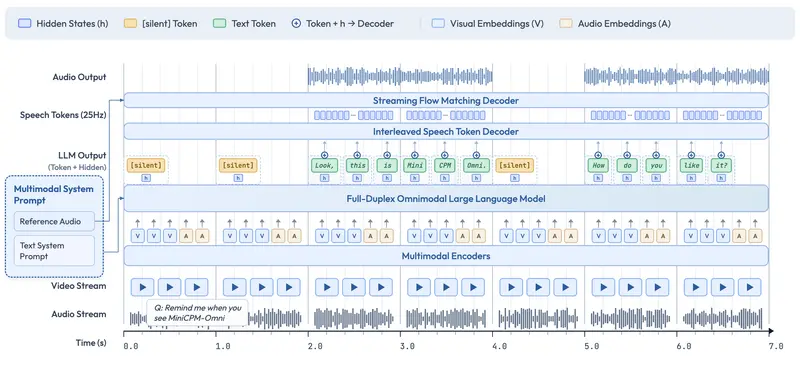
作为MiniCPM-o系列能力最强的迭代版本,该模型延续了面壁智能“小参数、高性能、端侧优先”的技术路线,不仅在视觉、语音、OCR等核心能力上超越多款主流闭源模型,更通过全双工实时流与主动交互机制,让端侧AI从“被动响应工具”升级为“实时感知、主动交互”的智能体,适配AI手机、智能座舱、便携设备等多元端侧场景。
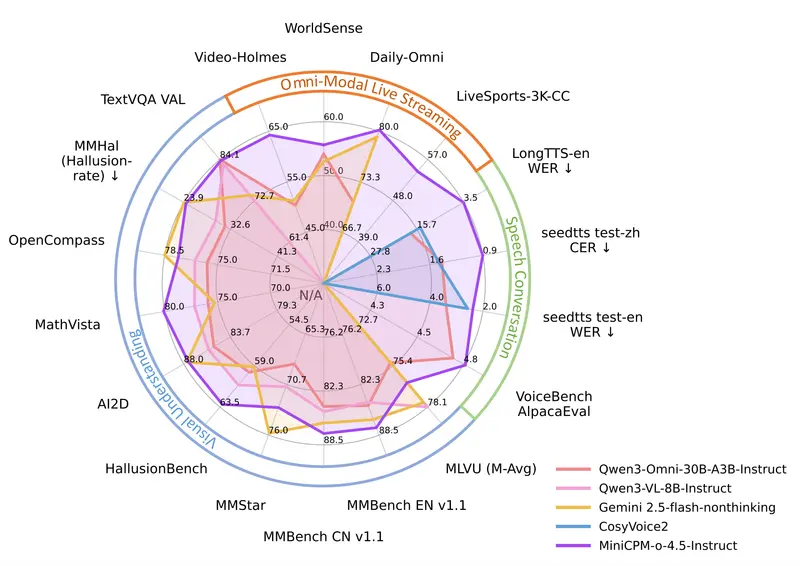
四大核心能力:视觉、语音、全双工、OCR全面突破
1. 视觉能力:9B参数对标顶级闭源模型,双模式兼顾效率与性能
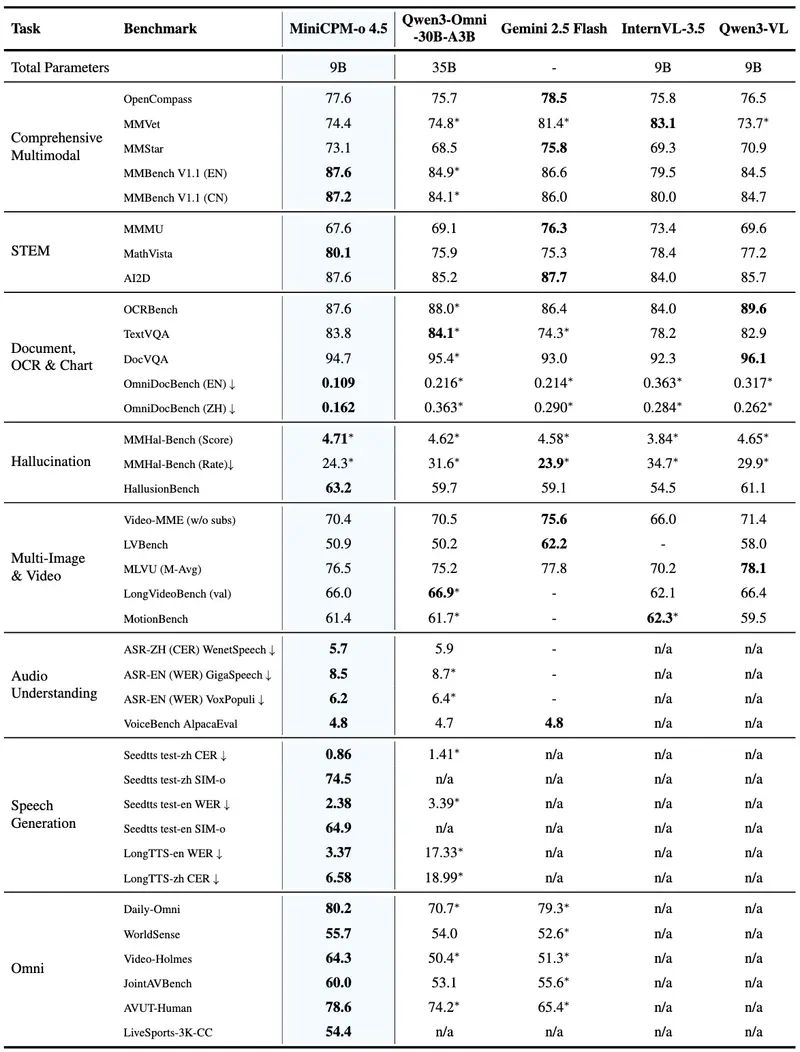
MiniCPM-o 4.5的视觉-语言能力实现跨越式提升,在覆盖8个主流基准的OpenCompass综合评测中,斩获平均77.6分的成绩。仅凭借9B参数,其视觉理解与图文交互能力便超越GPT-4o、Gemini 2.0 Pro等广泛使用的闭源模型,性能表现无限接近Gemini 2.5 Flash,成为小参数多模态模型的标杆之作。
在功能设计上,模型在单一架构中同时支持指令模式与思维模式:指令模式侧重快速响应,适配日常高频交互场景;思维模式支持深度推理,满足复杂图文分析、逻辑拆解需求,完美平衡不同用户场景下对效率与性能的双重诉求。同时,模型延续MiniCPM-V系列的高分辨率处理优势,可高效处理最高180万像素图像、最高10fps高帧率视频,支持任意宽高比,适配各类视觉输入场景。
2. 语音能力:双语实时对话,声音克隆与长语音生成更稳定
语音交互是MiniCPM-o 4.5的核心升级点之一,模型支持中英双语实时语音对话,可灵活配置不同音色,对话表现更自然、富有表现力且稳定性大幅提升。针对传统语音模型长语音生成易出错、不连贯的问题,该模型通过优化语音解码器设计,实现超过1分钟长语音的稳定、流畅生成,有效降低错字率,提升语音交互的连贯性与真实感。
此外,模型具备强大的趣味语音能力,仅需一段简短参考音频,即可完成声音克隆与角色扮演,克隆效果优于CosyVoice2等专业TTS工具。结合可配置语音建模设计,用户可通过音频系统提示词指定音色,推理阶段无需复杂配置,即可实现个性化语音交互,拓展了语音能力的应用边界。
3. 全双工多模态实时流:端侧原生“边看边听边说”,支持主动交互
作为本次发布的最大技术亮点,MiniCPM-o 4.5首次原生实现全双工多模态实时流能力,彻底打破传统多模态模型“输入-处理-输出”的串行流程。模型可端到端同时处理实时连续的视频、音频输入流,并并行生成文本、语音输出流,各模态流之间互不阻塞,真正实现“边看、边听、边说”的实时全模态交互,交互延迟与流畅度接近人类自然对话。
除被动响应指令外,模型还具备主动交互机制:语言模型模块以1Hz频率持续监控输入的音视频流,自动决策是否主动发言,可基于对直播、实时场景的持续理解,主动发起提醒、评论或信息反馈。例如在实时导航中主动提示路况变化、在视频观看中主动解读关键内容,让端侧AI从“被动工具”转变为“主动智能伙伴”。
4. OCR与多语言能力:文档解析业界领先,覆盖30+语种
依托强大的视觉基础,MiniCPM-o 4.5的OCR能力进一步强化,在OmniDocBench端到端英文文档解析评测中,表现超越Gemini-3 Flash、GPT-5等闭源模型,以及DeepSeek-OCR 2等专用OCR工具,达到业界领先水平,可高效完成复杂文档、表格、手写文字的精准识别与解析。
同时,模型具备可靠的行为一致性,在MMHal-Bench评测中与Gemini 2.5 Flash持平,有效降低幻觉输出;并支持30余种语言的多语言交互,覆盖全球主流语种,适配跨境、多语言场景的使用需求。
易用性与部署:端侧优先,多框架兼容,本地部署零门槛
MiniCPM-o 4.5深度聚焦端侧部署需求,通过多维度优化实现“轻量化、易部署、高兼容”,无论是个人用户本地运行,还是企业级规模化部署,均能高效适配:
- 本地推理高效:支持通过llama.cpp、Ollama在手机、PC、Mac等本地设备实现高效CPU推理,无需高端显卡即可流畅运行;
- 量化模型丰富:提供16种不同大小的int4、GGUF格式量化模型,进一步压缩体积,适配不同性能终端;
- 高吞吐部署:兼容vLLM、SGLang推理框架,实现高吞吐、内存高效的云端/服务器部署;
- 多芯片兼容:支持FlagOS统一多芯片后端插件,适配主流芯片架构,降低硬件适配成本;
- 灵活微调与演示:支持通过LLaMA-Factory在新领域、新任务上快速微调;同步提供在线网页演示server,降低试用门槛。
此外,面壁智能同步推出高性能llama.cpp-omni推理框架及配套WebRTC Demo,进一步优化端侧实时流推理效率,让手机、Mac等普通设备也能流畅运行全双工多模态交互,真正实现“AI能力普惠端侧”。
核心技术架构:端到端全模态设计,三大机制支撑实时交互
MiniCPM-o 4.5的强大能力,源于其创新的端到端全模态架构与三大核心技术机制,从底层重构多模态处理逻辑:
1. 端到端全模态架构
模型将视觉、语音、文本的编码器/解码器,与大语言模型通过稠密特征端到端紧密连接,各模态信息无需经过中间转换层,可直接在统一框架内流转与融合。这种设计最大化保留多模态信息的完整性,实现更高效的信息交互与控制,在训练过程中充分挖掘视觉、语音、文本的协同知识,提升模型综合理解能力。
2. 全双工多模态实时流机制
- 在线编码器转化:将传统离线模态编码器/解码器改造为支持流式输入/输出的在线全双工版本,语音解码器采用文本与语音token交错建模,实现全双工语音生成,与新输入实时同步;
- 毫秒级时分复用:在毫秒级时间线上同步所有输入、输出流,通过时分复用机制将并行全模态流划分为微小周期性时间片内的顺序信息组,在语言模型主干中统一建模,实现高效、低延迟的全模态流式处理,确保各流互不阻塞。
3. 主动交互与可配置语音机制
- 主动决策发言:语言模型以1Hz高频持续监控音视频流,自主判断发言时机,实现主动提醒、主动评论等主动交互能力,区别于传统模型的被动响应;
- 双系统提示词:延续文本系统提示词设计,新增音频系统提示词(指定音色),推理阶段仅需参考音频即可完成声音克隆、角色扮演,简化个性化语音配置流程。
行业价值:端侧全双工AI,开启实时交互新纪元
MiniCPM-o 4.5的发布,不仅是面壁智能在多模态大模型领域的技术突破,更标志着端侧AI交互从“静态、串行、被动”向“实时、并行、主动”的范式升级。其核心行业价值体现在三方面:
- 端侧能力天花板提升:以9B小参数实现Gemini 2.5 Flash级性能,打破“大参数=高性能”的固有认知,让手机、便携设备等轻量化终端具备顶级多模态能力;
- 交互体验革命:全双工实时流与主动交互,让AI交互接近人类自然对话,适配智能座舱、AI手机、实时翻译、无障碍辅助等场景,提升用户体验;
- 隐私与效率平衡:端侧本地运行避免敏感数据上传云端,兼顾实时交互效率与数据隐私安全,符合端侧AI发展的核心趋势。
未来,随着MiniCPM-o 4.5的开源与落地,端侧全双工多模态AI将快速渗透消费电子、车载、智能家居等领域,推动AI从“云端集中式”向“端云协同、端侧优先”演进,为用户带来更自然、更智能、更隐私的AI交互体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











