
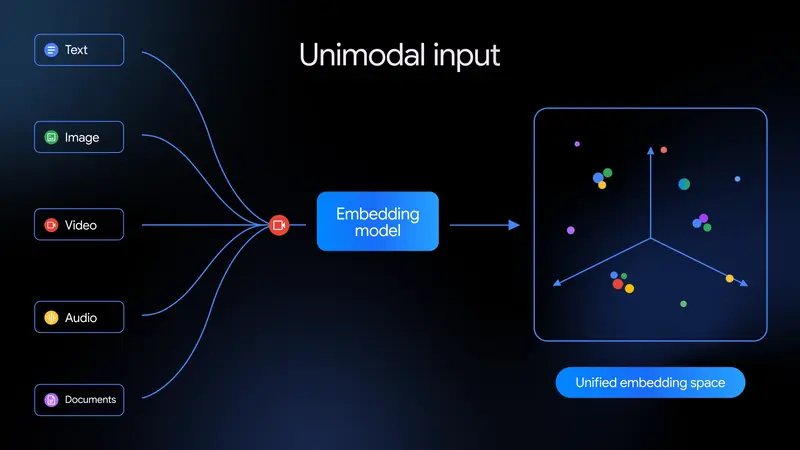
谷歌今日通过 Gemini API 和 Vertex AI 正式开放 Gemini Embedding 2 的公开预览。这是谷歌首个基于 Gemini 架构构建的原生多模态嵌入模型,能够将文本、图像、视频、音频和文档映射到同一个统一的向量空间,实现跨媒体类型的语义检索与分类。
- Gemini API:https://ai.google.dev/gemini-api/docs/embeddings
- Vertex AI:https://docs.cloud.google.com/vertex-ai/generative-ai/docs/embeddings/get-multimodal-embeddings
对于开发者而言,这意味着无需再为不同模态的数据维护多套嵌入流程,一套模型即可处理多源异构数据,显著简化工程链路。

- 官方介绍:https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2
核心能力:五种模态,一个向量空间
Gemini Embedding 2 在原有纯文本嵌入模型基础上进行了架构级扩展,支持以下输入类型:
| 模态 | 支持规格 | 关键说明 |
|---|---|---|
| 文本 | 最长 8192 词元 | 支持 100+ 语言,覆盖长文档语义理解 |
| 图像 | 单次请求最多 6 张 | 支持 PNG/JPEG 格式,可直接编码视觉特征 |
| 视频 | 最长 120 秒 | 支持 MP4/MOV 格式,自动提取时序语义 |
| 音频 | 原生音频输入 | 无需先转录为文本,直接编码声学特征 |
| 文档 | 最多 6 页 PDF | 直接解析文档结构与内容,保留排版语义 |
更重要的是,模型原生支持交错输入(Interleaved Input):你可以在单个请求中混合传递多种模态,例如"一张产品图 + 一段用户评论 + 一段开箱视频",模型能够理解不同媒体之间的关联关系,生成更具上下文感的嵌入向量。
技术亮点:灵活维度与高效表示
1. Matryoshka 表示学习
Gemini Embedding 2 延续了谷歌在嵌入模型上的技术积累,采用 Matryoshka 表示学习(嵌套表示):模型生成的向量支持动态降维,开发者可根据实际需求在 3072、1536、768 等维度间灵活选择。
- 高维(3072):保留最细粒度语义,适合高精度检索任务;
- 中维(1536/768):在性能与存储成本间取得平衡,适合大规模向量索引;
- 低维:适用于资源受限的边缘部署场景。
这种设计让开发者无需重新训练模型,即可根据业务阶段调整向量维度,兼顾效果与成本。
2. 统一嵌入空间的价值
传统多模态方案通常需要为文本、图像、音频分别训练独立的编码器,再通过后期对齐实现跨模态检索。而 Gemini Embedding 2 从架构层面将多模态输入映射到同一个向量空间,带来两个直接优势:
- 跨模态检索更自然:用一段文字搜索相关视频片段,或用一张图片查找相似音频,无需额外的映射层;
- 多模态聚类更准确:将图文混排的用户反馈、多模态产品资料等混合数据直接聚类,发现潜在的语义分组。
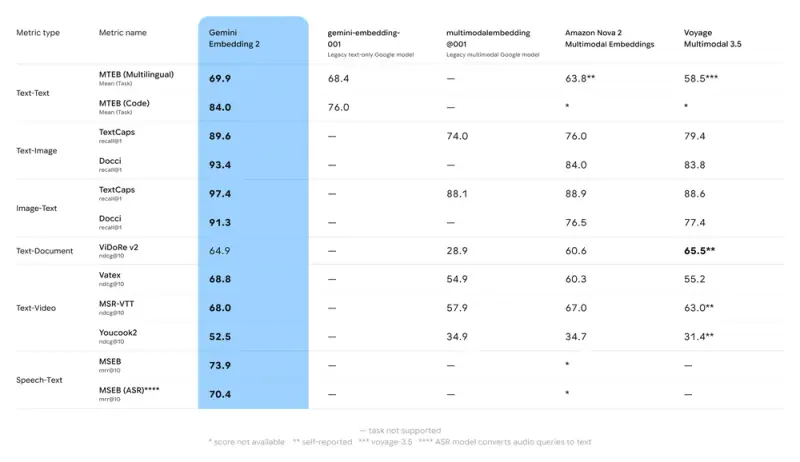
性能表现:多任务基准领先
在内部评估中,Gemini Embedding 2 在以下任务中展现出优于前代模型及行业基线的表现:
- 文本检索:在长上下文理解与多语言语义匹配任务中提升显著;
- 图像 - 文本对齐:在细粒度视觉问答与跨模态检索基准中达到新高度;
- 音频理解:原生音频嵌入能力在语音指令分类、声学事件检索等任务中表现突出;
- 视频语义:对短时视频的内容摘要与相似片段检索准确率明显提升。
这些改进并非孤立优化,而是源于统一多模态架构带来的协同增益——模型在学习一种模态的语义时,能够借助其他模态的监督信号进行互补增强。
应用场景:从检索增强生成到多模态分析
嵌入向量是构建高级 AI 应用的基础组件。Gemini Embedding 2 的多模态能力可直接赋能以下典型场景:
- 检索增强生成(RAG):为知识库同时索引文档、截图、操作视频,让 AI 助手在回答时能综合多源信息;
- 多模态语义搜索:用户输入"找一段带有猫叫声的户外视频",系统可直接理解并返回匹配结果;
- 内容聚类与去重:对海量用户生成内容(图文、短视频、语音评论)进行统一聚类,识别重复或相似内容;
- 情感与意图分析:结合用户上传的图片、语音和文字,更精准判断反馈情绪与核心诉求;
- 跨模态推荐:根据用户浏览的图文内容,推荐风格相似的视频或音频资源。
部分早期访问合作伙伴已将 Gemini Embedding 2 应用于高价值场景,包括多模态客服知识库、跨媒体内容管理平台、智能多媒体检索系统等。
快速上手:代码示例与生态集成
Python 调用示例
from google import genai
from google.genai import types
# 初始化客户端(本地 API 或 Vertex AI)
client = genai.Client()
# 读取多模态输入文件
with open("example.png", "rb") as f:
image_bytes = f.read()
with open("sample.mp3", "rb") as f:
audio_bytes = f.read()
# 生成嵌入向量
result = client.models.embed_content(
model="gemini-embedding-2-preview",
contents=[
"What is the meaning of life?",
types.Part.from_bytes(data=image_bytes, mime_type="image/png"),
types.Part.from_bytes(data=audio_bytes, mime_type="audio/mpeg"),
],
)
print(result.embeddings) # 输出统一向量空间中的嵌入表示
生态工具链支持
Gemini Embedding 2 已与主流开发框架和向量数据库完成集成:
- 开发框架:LangChain、LlamaIndex、Haystack
- 向量数据库:Weaviate、Qdrant、ChromaDB、Vertex AI Vector Search
开发者可直接使用 hf:// 风格的路径或标准 API 调用,将多模态嵌入能力嵌入现有工作流,无需重构数据管道。
交互式学习资源
工作流建议:何时使用嵌入模型
为帮助开发者合理规划技术选型,以下是嵌入模型的典型使用时机:
✅ 适合使用嵌入模型:
- 需要语义相似性匹配(而非关键词匹配);
- 数据包含多种媒体类型,希望统一处理;
- 构建检索系统、推荐系统或聚类分析管道;
- 作为 RAG 系统的知识库索引层。
❌ 不建议直接使用嵌入模型:
- 需要精确的关键词匹配或正则表达式检索;
- 对延迟极度敏感且无法接受向量检索的额外开销;
- 数据模态单一且已有成熟的专用嵌入方案。
目前,Gemini Embedding 2 已通过 Gemini API 和 Vertex AI 开放公开预览。开发者可直接调用体验,或结合现有框架快速集成。随着多模态数据在业务中的占比持续提升,统一嵌入表示的价值将进一步凸显。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











