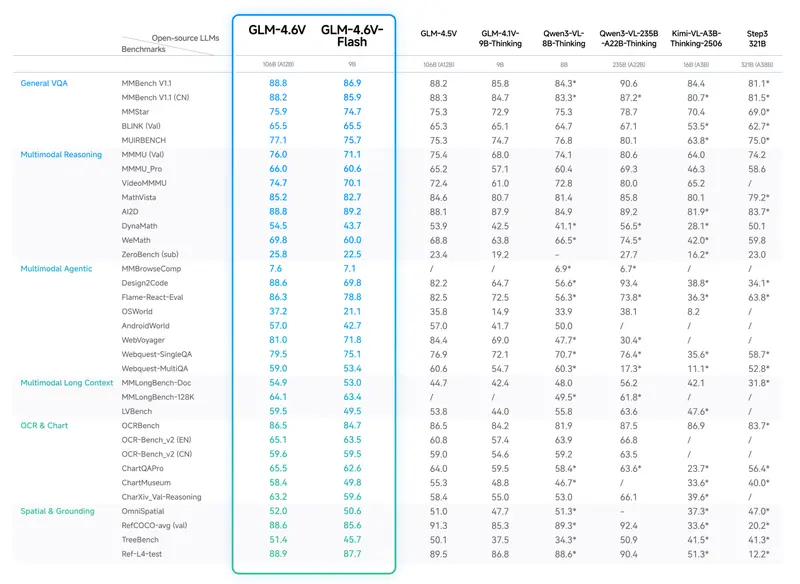
在人工智能领域,模型往往面临“专才”与“全才”的抉择:有的擅长理解图片内容,有的精于生成精美画作,但鲜有模型能同时精通“看、想、画、改”四项技能。

上海人工智能实验室正式推出 InternVL-U,一款仅有 40 亿参数 的轻量级统一多模态模型。它成功将多模态理解、逻辑推理、图像生成、图像编辑整合进单一框架,不仅打破了理解与生成之间的能力壁垒,更以惊人的效率在多项基准测试中超越了参数量是其三倍以上的竞品,为通用人工智能(AGI)的普及树立了新的基线。
- GitHub:https://github.com/OpenGVLab/InternVL-U
- HuggingFace:https://huggingface.co/InternVL-U/InternVL-U
- GenEditEvalKit:https://github.com/open-compass/GenEditEvalKit
- TextEdit Benchmark:https://github.com/open-compass/TextEdit
🚀 核心突破:四位一体的全能智能
InternVL-U 不再是需要多个模型拼接的“缝合怪”,而是一个真正的统一体。其核心能力涵盖:
1. 深度视觉理解 (Understanding)
不仅能识别物体,更能理解场景语义。
- 示例:面对一张餐厅照片,它不仅认出“这是餐厅”,还能描述“桌上有三盘菜,窗外夜景灯光温馨,氛围放松”。
2. 高质量图像生成 (Generation)
支持中英文双语提示词,精准还原用户意图。
- 示例:输入“一只穿着宇航服的柴犬在月球插旗”,即可生成符合描述的创意图像。
3. 精细化图像编辑 (Editing)
这是其最实用的亮点。支持局部修改、物体替换、背景更换等复杂指令,且能保持原图结构不变。
- 示例:“把合影背景换成海边”、“将广告牌文字从‘促销’改为‘新品上市’”。
4. 逻辑推理创作 (Reasoning)
具备“思维链”能力,能将抽象概念转化为具体画面。
- 示例:输入“表现‘努力终有回报’”,模型能先拆解概念,再创作出寓意深刻的图像,而非机械堆砌元素。

💡 四大独特优势:为何选择 InternVL-U?
1. “小而强”的极致效率
- 参数规模:仅 4B (40 亿) 参数,属于轻量级模型。
- 性能表现:在 GenEval、DPG-Bench 等权威测试中,其表现 consistently 优于参数量超 12B 的统一基线模型(如 BAGEL)。
- 部署友好:低资源需求使其能在消费级显卡甚至边缘设备上运行,极大降低了使用门槛。
2. 突破性的文字渲染能力
解决了 AI 绘图“文字乱码”的顽疾。
- 中英双优:在 LongText-Bench 测试中,中文得分 0.860,英文得分 0.738,远超同类开源模型。
- 应用场景:完美胜任海报设计、名片制作、UI 界面生成等需要清晰文字的任务。
3. “思维链”驱动的精准执行
引入 Chain-of-Thought (CoT) 机制,让模型学会“三思而后行”。
- 工作流程:面对复杂指令(如“把左边的红球移到右边并加上阴影”),模型会先在内部拆解步骤,规划路径,再执行生成。
- 效果:在逻辑密集型任务中,启用思维链后得分提升显著(如编辑任务从 3.6 分跃升至 9.4 分)。
4. 高保真编辑,拒绝“牵一发而动全身”
- 结构保持:采用解耦视觉表示,确保修改指定区域时,原图的其他部分(如前景物体、光影关系)不受干扰。
- TextEdit 基准:在专门评估文字编辑的新基准中,F1 分数达 0.71,媲美商业闭源模型 Nano Banana Pro。
🏗️ 技术架构:统一大脑 + 专家分工
InternVL-U 的成功源于其巧妙的架构设计:
- 统一大脑 (Unified Brain):基于 InternVL 3.5 多模态大语言模型,负责统一处理文本和图像的语义理解。
- 专用生成头 (Specialized Head):集成基于 MMDiT 架构的视觉生成模块,专门负责高质量像素合成。
- 解耦表示策略:
- 理解阶段:使用压缩特征(缩略图级),保证速度。
- 生成阶段:使用高清特征,保证细节。
- 输出分流:文本走“下一个词预测”通道,图像走“流匹配 (Flow Matching)”通道,各司其职又协同工作。
📊 数据与训练:不仅仅是“看图说话”
为了弥合审美生成与高级智能的差距,团队构建了全面的数据合成流程:
- 文字渲染数据集:专项训练各种字体、背景下的文字清晰度。
- 科学图表数据集:学习电路图、分子式、几何图形等严谨结构。
- 空间推理数据集:强化三维旋转、对称、投影等空间逻辑。
- 思维链数据集:教会模型如何将抽象指令拆解为可执行的视觉步骤。
🏆 实测表现:全能冠军
| 测试维度 | 基准测试 | InternVL-U 表现 | 对比结论 |
|---|---|---|---|
| 图像生成 | GenEval | 0.85 | 超越所有同级统一模型,包括 3 倍参数的 BAGEL |
| 复杂场景 | DPG-Bench | 85.18 | 领先同类,证明对长难句的理解力 |
| 文字渲染 | LongText-Bench (CN) | 0.860 | 远超此前最佳开源模型 (0.561),达到商用级别 |
| 图像编辑 | TextEdit (F1) | 0.71 | 持平商业闭源模型,大幅领先开源竞品 |
| 推理增强 | 知识密集型生成 | 0.58 (↑0.12) | 开启思维链后,逻辑准确性显著提升 |
迈向通用多模态智能的新基线
InternVL-U 的发布证明,统一多模态模型不必以牺牲效率或特定能力为代价。通过精巧的架构设计和高质量的数据合成,40 亿参数的模型也能展现出超越百亿级模型的智慧。
对于开发者而言,这意味着更低成本的部署方案;对于普通用户,这意味着一个真正能“看懂、想通、画好、改准”的全能 AI 助手触手可及。InternVL-U 不仅是一个强大的基线模型,更是通往全面、通用人工智能的重要一步。
未来,随着更多类似模型的涌现,AI 将不再是冷冰冰的工具,而是真正能理解我们意图、协助我们创作的智能伙伴。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











