在“越大越强”的大模型军备竞赛中,英伟达走出了一条截然不同的路:追求极致的“智能密度”。
英伟达正式开源 Nemotron-Cascade 2,一款总参数量 30B、激活参数仅 3B 的混合专家模型(MoE)。尽管体量轻巧,它却在硬核推理领域展现了惊人的爆发力——成为继前作之后,第二个在 2025 年国际数学奥林匹克 (IMO)、国际信息学奥林匹克 (IOI) 及 ICPC 世界总决赛 中达到金牌水平的开源模型。
- 模型:https://huggingface.co/collections/nvidia/nemotron-cascade-2
🎯 核心定位:术业有专攻,推理即正义
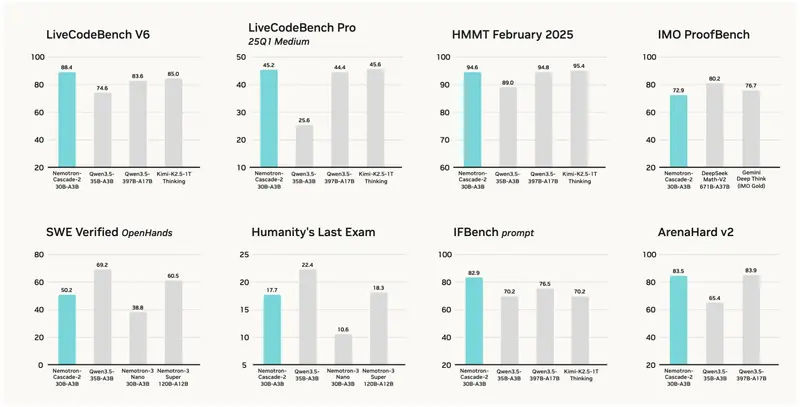
Nemotron-Cascade 2 并非追求“全能冠军”,而是专注于推理密集型任务的单项王者。在与 Qwen3.5-35B-A3B 及自家超大模型 Nemotron-3-Super 的对比中,它在关键领域表现卓越:
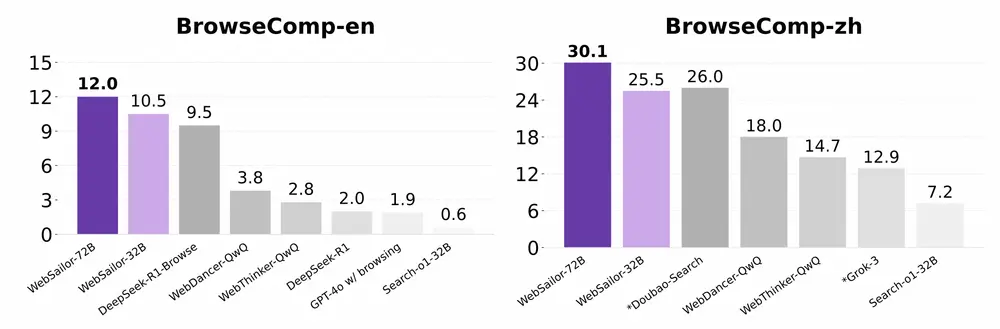
- 🧮 数学推理:在 AIME 2025 和 HMMT Feb25 基准测试中,成绩优于 Qwen3.5-35B-A3B。
- 💻 代码能力:在 LiveCodeBench v6 和 IOI 2025 中处于领先地位,展现强大的算法解题能力。
- 🤖 对齐与指令:在 ArenaHard v2 和 IFBench 上得分显著更高,更懂人类意图,更适合智能体交互。
战略意义:这证明了通过特定领域的强化学习,30B 规模的模型也能具备曾经只有千亿级模型才拥有的顶级推理能力。
⚙️ 技术揭秘:如何炼成“金牌选手”?
Nemotron-Cascade 2 的强大源于其独特的后训练流程,基于 Nemotron-3-Nano-30B-A3B-Base 底座精心打磨:
1. 高质量监督微调 (SFT)
团队使用了精心策划的长序列数据集(最长 256K token):
- 编程:190 万条 Python 推理轨迹 + 130 万条工具调用样本。
- 数学:81.6 万条自然语言证明样本。
- 软件工程:12.5 万个智能体样本 + 38.9 万个非智能体样本。
2. 级联强化学习 (Cascade RL) 🌟
这是防止“灾难性遗忘”的关键。模型经历了顺序的、领域特定的训练阶段:
- 指令遵循 RL → 多领域 RL → RLHF → 长上下文 RL → 代码/软件工程专项 RL。
- 每个阶段独立调整超参数,确保在增强新能力的同时不丢失旧知识。
3. 多领域同策略蒸馏 (MOPD)
引入创新的 MOPD 技术,利用性能最佳的中间“教师”模型提供密集的 Token 级蒸馏。相比传统的序列级奖励,MOPD 的样本效率大幅提升,加速了模型收敛。
🛠️ 功能特性:双模式切换与智能体原生支持
🔄 双模式推理
用户可通过提示词灵活切换模型行为:
- 🧠 思考模式 (Thinking Mode):
- 触发:输入单个
<think>token 并换行。 - 效果:激活深度推理链,适用于复杂数学证明、高难算法题。
- 触发:输入单个
- ⚡ 非思考模式 (Non-Thinking Mode):
- 触发:预置空的
<think></think>块。 - 效果:跳过深思熟虑,提供高效、直接的响应,适用于简单问答或实时对话。
- 触发:预置空的
🤖 智能体原生交互
模型内置结构化协议,完美适配 Agent 工作流:
- 工具定义:在
<tools>标签内声明可用工具。 - 工具调用:模型自动在
<tool_call>标签内生成可验证的执行代码。 - 反馈闭环:支持接收执行结果并据此调整后续步骤。
📊 性能对比一览
| 基准测试 | 领域 | Nemotron-Cascade 2 表现 | 对比 Qwen3.5-35B |
|---|---|---|---|
| AIME 2025 | 数学 | 🥇 金牌水平 | ✅ 胜出 |
| IOI 2025 | 编程 | 🥇 金牌水平 | ✅ 领先 |
| LiveCodeBench v6 | 代码 | 🏆 SOTA | ✅ 领先 |
| ArenaHard v2 | 对齐 | 📈 高分 | ✅ 显著更高 |
| 激活参数 | 效率 | 3B (极速推理) | 3B (相当) |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...