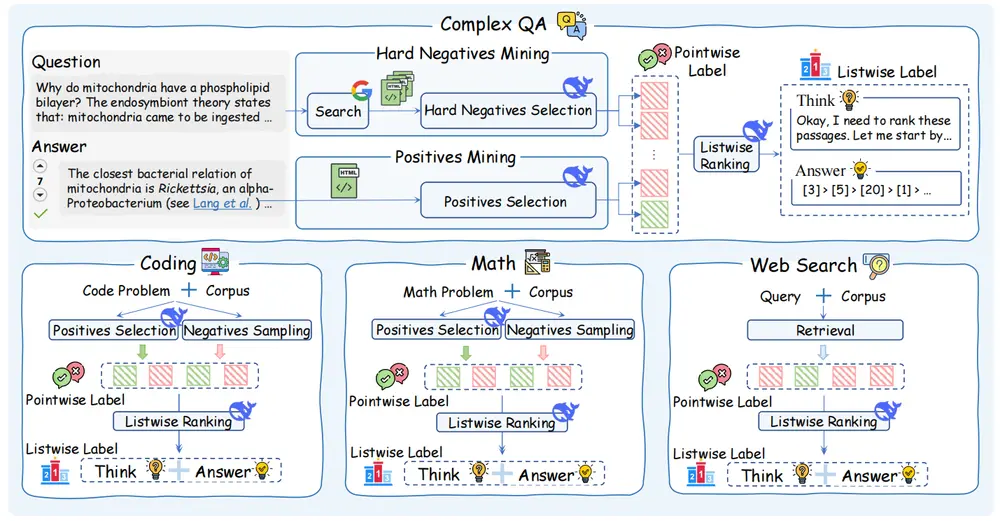
在 AI 自主代理(Agent)迈向“深度研究”的征途中,数据一直是最大的拦路虎。训练一个能像人类专家一样进行多步推理、交叉验证的 AI,需要海量的长周期研究轨迹数据。然而,现有的数据合成方案严重依赖实时网络 API,不仅成本高昂、结果不可复现,更难以生成超过几十步的“超长链路”数据。
由德克萨斯农工大学、滑铁卢大学、UCSD、Verdent AI、NetMind AI 及 Lambda 联合推出的 OpenResearcher 正式问世。这是一个完全开源的智能体大语言模型及训练框架。它创新性地构建了离线浏览器环境,成功合成了 97,000+ 条高质量长周期研究轨迹(部分包含超 100 次工具调用)。
- GitHub:https://github.com/TIGER-AI-Lab/OpenResearcher
- 模型:https://huggingface.co/collections/TIGER-Lab/openresearcher
- Demo:https://huggingface.co/spaces/OpenResearcher/OpenResearcher
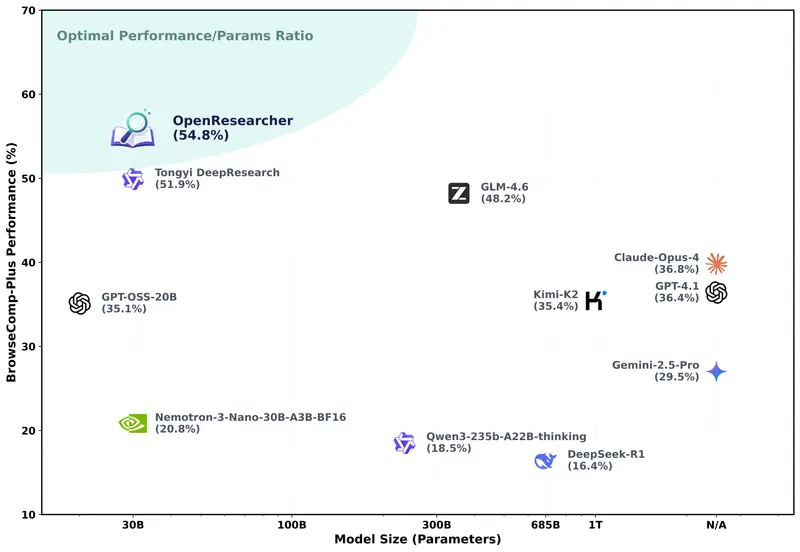
实测数据显示,基于该数据训练的 30B 参数模型在 BrowseComp-Plus 基准测试中取得了 54.8% 的准确率,一举超越了 GPT-4.1、Claude-Opus-4、Gemini-2.5-Pro 以及 DeepSeek-R1 等顶尖闭源模型,标志着开源深度研究智能体迎来了新的里程碑。
核心突破:离线合成,打破数据孤岛
OpenResearcher 的最大贡献在于提出了一套可复现、低成本、离线化的数据合成流水线(Pipeline),彻底解决了深度研究数据获取的三大痛点:
1. 离线环境,零成本复现
- 传统痛点:依赖实时搜索 API(如 Google Search),每次生成都要花钱,且网络内容随时变化,导致实验无法复现。
- OpenResearcher 方案:构建了一个包含 1500 万文档 的静态离线语料库。一旦构建完成,所有的搜索、浏览、证据提取均在本地离线环境中进行。
- 成本趋零:无需支付任何 API 调用费用。
- 绝对复现:无论何时何地运行,输入相同的问题,得到的文档和结果完全一致。
2. 超长轨迹,模拟深度思考
- 传统痛点:现有数据集多为 3-5 步的短任务,无法训练 AI 处理需要数十步推理的复杂课题。
- OpenResearcher 方案:利用强大的教师模型(GPT-OSS-120B),在离线库中模拟人类研究过程,生成了大量包含 100+ 次工具调用 的超长轨迹。这些轨迹完整记录了从“提出问题”到“搜索线索”、“打开文档”、“查找证据”、“交叉验证”直至“得出结论”的全思维链。
3. 精准模拟人类浏览行为
不同于简单的“搜索 - 回答”模式,OpenResearcher 强制模型使用三种显式浏览器原语,完美复刻人类研究员的操作逻辑:
- Search (搜索):输入关键词,获取相关文档列表。
- Open (打开):点击进入具体文档,查看全文。
- Find (查找):在长文档中定位特定关键信息(如人名、日期、数据)。
架构与训练:从合成到超越
数据合成流程
- 问题筛选:从复杂数据集中挑选需要多步推理的“硬骨头”问题。
- 语料构建:为每个问题预先收集“黄金文档”,并混入海量通用文档,构建离线库。
- 轨迹生成:教师模型在离线库中自主探索,记录每一步的思考与操作。
- 质量过滤:剔除无效探索,保留 97,000+ 条高质量轨迹(成功率 56.7%)。
模型训练与性能
研究团队使用上述数据对 Nemotron-3-Nano-30B-A3B(30B 参数)进行了监督微调(SFT)。结果令人震惊:
- BrowseComp-Plus (离线):54.8% 准确率(比基线提升 34%),SOTA。
- BrowseComp (实时网):26.3% 准确率。
- GAIA (实时网):64.1% 准确率。
- xbench-DeepSearch (实时网):65.0% 准确率。
即便是在需要实时联网的测试中,这个仅在离线数据上训练的模型,其表现也足以抗衡甚至超越众多千亿参数的闭源巨头。
关键洞察:失败也是老师
通过对离线环境的可控分析,研究团队发现了两个反直觉但极具价值的结论:
- “查找”工具至关重要:引入
Find操作后,模型定位关键证据的效率显著提升,准确率大幅优于仅使用 Search/Open 的模型。 - 失败轨迹同样有价值:传统的做法是只保留成功的轨迹。但 OpenResearcher 发现,失败的轨迹(即模型努力探索但最终未解出答案的过程)包含了丰富的“负样本”信号(如错误的搜索词、无效的推理路径)。将失败轨迹纳入训练,效果与成功轨迹相当,这极大地扩充了可用数据量。
全栈开源:赋能社区
OpenResearcher 真正践行了开源精神,向社区开放了全套资源:
- 📂 数据集:96K+ 条高质量深度研究轨迹(含长短期、成功与失败样本)。
- 🤖 模型权重:训练完成的 30B-A3B 模型 Checkpoint。
- ⚙️ 训练代码:完整的 SFT 及蒸馏方案。
- 🧪 评估框架:轻量级的离线/在线深度研究评估工具。
- 🌍 离线环境:可复用的离线浏览器模拟器及文档库构建脚本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











