
在国庆节假期前夕,DeepSeek 正式推出 DeepSeek-V3.2-Exp ——一个面向未来架构演进的实验性(Experimental)版本。该模型并非最终发布版,而是通向新一代高效架构的关键中间步骤。
- GitHub:https://github.com/deepseek-ai/DeepSeek-V3.2-Exp
- HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
- 魔塔:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Exp
目前,官方 App、网页端及小程序均已同步更新至 V3.2-Exp 版本。与此同时,API 调用成本大幅下调,开发者使用 DeepSeek API 的支出将降低 50% 以上。

这一系列变化的核心,源于一项关键技术突破:DeepSeek 稀疏注意力机制(DeepSeek Sparse Attention, DSA)。
新机制上线:细粒度稀疏注意力首次落地
V3.2-Exp 基于前代稳定模型 V3.1-Terminus 构建,在保持整体训练配置严格对齐的前提下,首次引入了 DSA 技术。
传统 Transformer 模型采用密集注意力机制,其计算复杂度随文本长度呈平方级增长(O(L²)),在处理长上下文时资源消耗巨大。而 DSA 则通过细粒度词元选择机制,仅保留最关键的信息交互路径,显著降低计算负担。
其核心优势在于:
- 计算复杂度从 O(L²) 下降至 O(Lk),其中 k 远小于 L;
- 在长文本场景下,推理速度明显提升;
- 训练与推理效率提高的同时,输出质量几乎不受影响。
这是业内首次实现真正意义上的细粒度动态稀疏注意力,标志着 DeepSeek 在高效 Transformer 架构探索上的重要进展。
工作原理简析
DSA 的实现包含两个关键组件:
- 闪电索引器(Lightning Indexer):用于快速评估当前查询词元与历史词元之间的关联强度,生成“索引分数”。该过程基于轻量级公式计算,不增加额外训练开销。
- 细粒度词元选择机制:根据索引分数,为每个查询词元动态选取前 k 个最相关的键值对参与注意力计算。这意味着模型只聚焦于语义上真正重要的上下文片段。
此外,DSA 基于多查询注意力(MQA)模式下的 MLA(Multi-head Latent Attention)架构进行集成,使得潜在向量在多个查询头之间共享,进一步提升了计算效率。
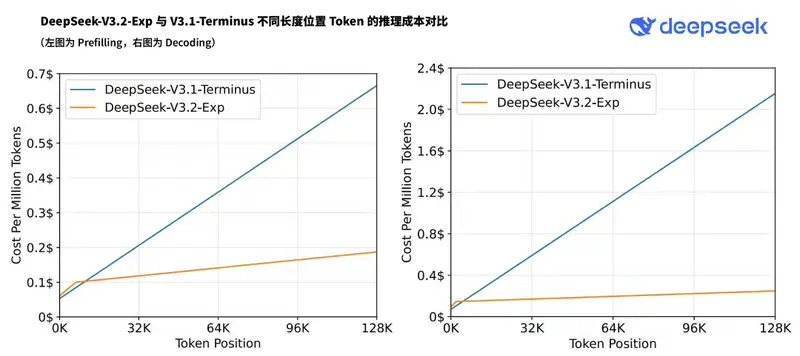
性能表现:效率提升,效果持平
为准确评估 DSA 的实际影响,团队刻意保持 V3.2-Exp 与 V3.1-Terminus 在数据、训练步数、学习率等关键参数上完全一致。测试结果显示:
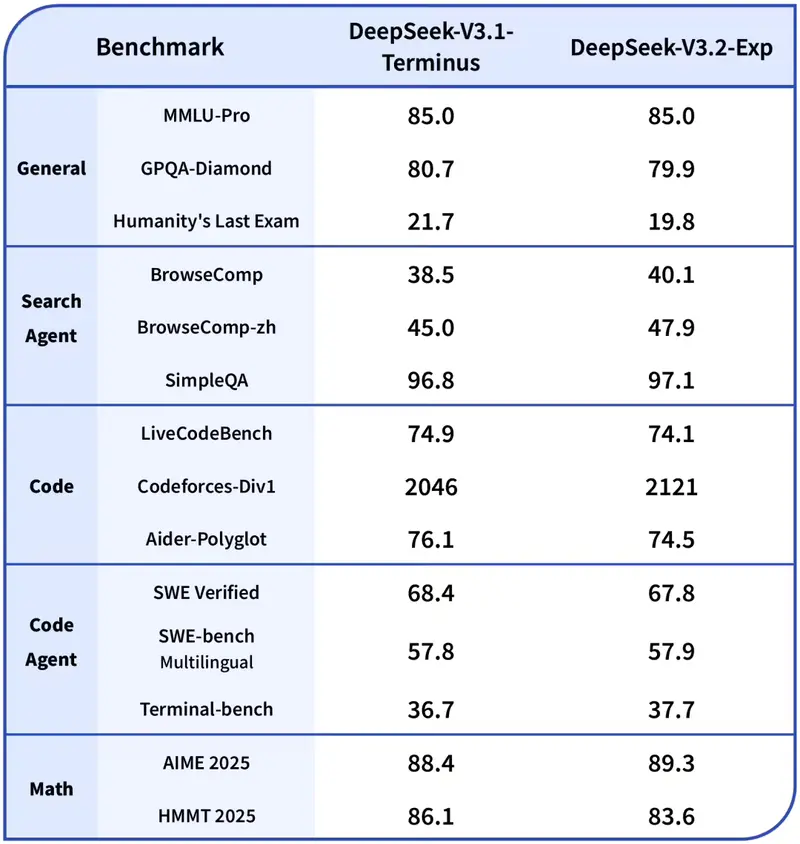
可见,在多数公开评测集中,V3.2-Exp 的性能与前代基本持平,仅在极少数高难度任务中出现轻微波动。
而在长文本推理效率方面,提升显著:
- 在 H800 GPU 上实测,V3.2-Exp 的解码阶段推理成本明显低于 V3.1-Terminus;
- 随着输入长度增加,性能优势进一步放大。
这表明 DSA 成功实现了“几乎无损的质量换效率”目标。
当前定位:实验性版本,欢迎广泛测试
尽管已在标准基准中验证有效性,V3.2-Exp 仍被定义为实验性版本,主要目的包括:
- 验证稀疏注意力在真实用户场景中的稳定性;
- 收集长文本任务下的反馈数据;
- 为后续正式迭代积累工程与体验依据。
为此,官方已为开发者临时保留 V3.1-Terminus 的 API 接口,方便进行横向对比测试。用户可通过指定模型名称调用旧版本,以便评估迁移影响。
多领域适应性持续增强
除效率优化外,V3.2-Exp 延续了 DeepSeek 系列在以下领域的强表现:
- 数学推导
- 编程能力(支持多种语言)
- 逻辑推理
- 长文档理解与摘要
得益于持续训练策略,模型在长上下文任务中的连贯性和准确性也得到进一步巩固。
后续展望
V3.2-Exp 的发布,不仅是技术路线图中的一次阶段性验证,更是 DeepSeek 向更高能效比、更大上下文支持迈进的重要一步。
未来,团队将持续优化稀疏注意力机制,并探索其在多模态、Agent 场景中的扩展应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











