
谷歌今日推出 Gemini 2.5 Flash 和 Gemini 2.5 Flash-Lite 的预览更新版本,已在 Google AI Studio 与 Vertex AI 平台上线。此次升级聚焦于提升模型在实际应用中的效率、准确性和多模态能力,进一步强化其在高吞吐、低延迟场景下的表现。

这不仅是性能的微调,更是对生产级 AI 应用需求的直接回应。
Gemini 2.5 Flash-Lite:更轻量,更精准
新版 gemini-2.5-flash-lite-preview-09-2025 针对轻量级任务进行了专项优化,主要改进集中在三个方面:
- 更强的指令遵循能力
模型在理解复杂提示(prompt)和系统指令方面显著提升,减少误解或偏离预期输出的情况,更适合用于自动化流程和规则明确的应用。 - 回答更简洁,冗余更少
输出内容经过压缩优化,在保持信息完整的前提下大幅降低 token 使用量。这对需要高频调用的 API 场景尤为重要——意味着更低的成本与更短的响应延迟。 - 多模态与翻译能力增强
- 图像理解更准确,能更好识别上下文细节;
- 音频转录质量提升,适用于语音处理任务;
- 翻译结果更加自然流畅,跨语言支持更可靠。
开发者可通过以下模型字符串立即测试:
gemini-2.5-flash-lite-preview-09-2025
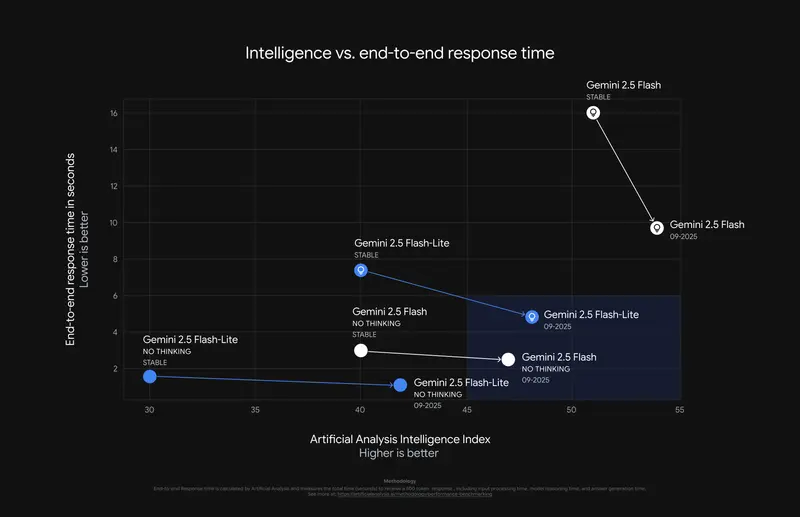
与当前的稳定版本相比,Gemini 2.5 Flash和2.5 Flash Lite预览版在质量和速度方面都有了显著提升
Gemini 2.5 Flash:智能体任务性能显著提升
新版本 gemini-2.5-flash-preview-09-2025 则重点加强了在复杂任务中的表现,尤其面向“AI 智能体”(Agent)类应用:
- 工具使用能力更强
模型在调用外部工具(如搜索、代码执行、数据库查询)时逻辑更清晰,决策路径更合理。在关键基准测试 SWE-Bench Verified 上,性能从 48.9% 提升至 54%,进步明显。 - 推理效率更高
即使开启“思维链”(thinking process),新模型也能以更少的 token 实现更高质量的输出,从而降低整体计算开销和响应时间。
早期测试反馈积极。自主 AI 智能体公司 Manus 的联合创始人兼首席科学家季逸超表示:
“新的 Gemini 2.5 Flash 在速度与智能之间实现了卓越平衡。我们在长周期智能体任务上的评估显示性能提升了 15%。出色的性价比让我们能够扩展规模,更好地实现‘延伸人类触达范围’的使命。”
该预览版模型字符串为:
gemini-2.5-flash-preview-09-2025
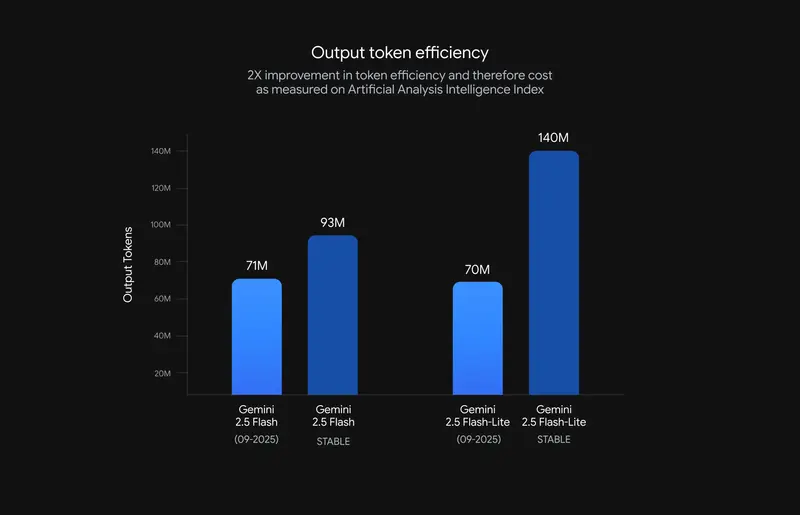
Gemini 2.5 Flash-Lite型号的产量代币减少了50%(相应地,成本也降低了50%),而Gemini 2.5 Flash型号的产量代币则减少了24%
新增 -latest 别名,简化开发流程
为了让开发者更便捷地体验最新模型,谷歌引入了两个新别名:
gemini-flash-latestgemini-flash-lite-latest
这两个别名将始终指向当前最新的预览版本,无需每次手动更新模型名称即可获取最新能力。
需要注意的是:
- 别名背后的模型会定期更新;
- 成本、速率限制和功能可能随版本变化;
- 谷歌承诺将在变更前 提前两周通过邮件通知,确保平稳过渡。
建议:
- 对稳定性要求高的生产环境:继续使用固定版本(如
gemini-2.5-flash); - 希望快速试用新特性的项目:可采用
-latest别名进行原型开发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











