昆仑万维天工项目组近日发布了 Skywork-R1V3-38B,这是其开源视觉-语言模型(VLM)系列 Skywork-R1V 的最新迭代版本,也是目前该系列中性能最强的多模态推理模型。基于 InternVL-38B 架构构建,并结合创新性的后训练强化学习策略,R1V3 在多个基准测试中实现了开源领域的 SOTA(State-of-the-Art)表现,显著推动了多模态与跨学科智能的发展。
技术亮点
Skywork-R1V3 是一个面向多模态推理任务设计的先进模型,其核心技术创新包括:
✅ 精炼的后训练强化学习
无需依赖传统的推理预训练流程,通过“细粒度冷启动微调”为后续的强化学习做好准备,从而大幅提升模型的推理能力。
🔗 关键连接器模块
研究发现,连接器模块在实现视觉与语言之间的高效对齐方面起着决定性作用。仅对连接器进行微调,即可在强化学习之后进一步提升模型整体表现。
🔢 关键推理令牌熵
引入了一种新的指标——“关键推理令牌的熵”,用于衡量模型的推理能力,并指导强化学习过程中的检查点选择,使训练更具针对性。
这些创新使得模型具备更强的跨领域泛化能力,不仅在数学推理上表现出色,还能将推理能力扩展到物理、化学、文学等多个学科领域。
主要功能
| 功能 | 描述 |
|---|---|
| 视觉推理 | 能够结合图像与文本信息进行复杂推理,如解决视觉数学题、逻辑推理等任务 |
| 跨模态对齐 | 利用连接器模块实现图像与语言的有效融合,确保多模态输入协同工作 |
| 强化学习优化 | 通过 RL 框架进一步提升推理能力,无需额外预训练 |
| 多领域迁移 | 支持从数学向其他学科的推理能力迁移,适用于多种知识场景 |
主要特点
| 特点 | 说明 |
|---|---|
| 创新训练框架 | 基于冷启动微调 + 强化学习的组合,激活并增强模型推理能力 |
| 高效推理能力 | 在多项多模态推理基准测试中达到开源模型领先水平,接近部分闭源顶尖模型 |
| 新型评估指标 | “关键推理令牌的熵”作为强化学习训练过程中的重要参考指标 |
| 跨领域泛化能力 | 不仅擅长数学推理,还具备向其他学科迁移的能力 |
工作原理简述
- 冷启动微调(Cold Start Finetuning)
使用早期版本 Skywork-R1V2 的数据集进行初始监督学习(SFT),为强化学习打下基础。 - 强化学习(Reinforcement Learning)
采用 PPO 和 GRPO 等算法,通过最大化奖励函数优化模型的推理策略。 - 连接器模块(Connector Module)
作为视觉与语言模态之间的桥梁,确保两者有效对齐与交互。 - 连接器唯一微调(Connector-Only Tuning)
在 RL 后阶段专门调整连接器参数,以平衡模型的知识分布,提升非数学类任务的表现。
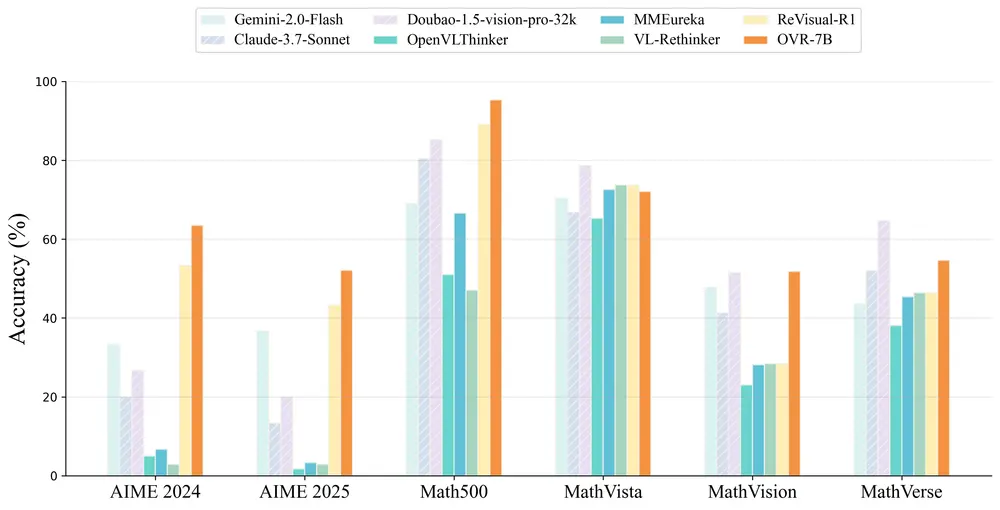
性能评估结果(主要基准)
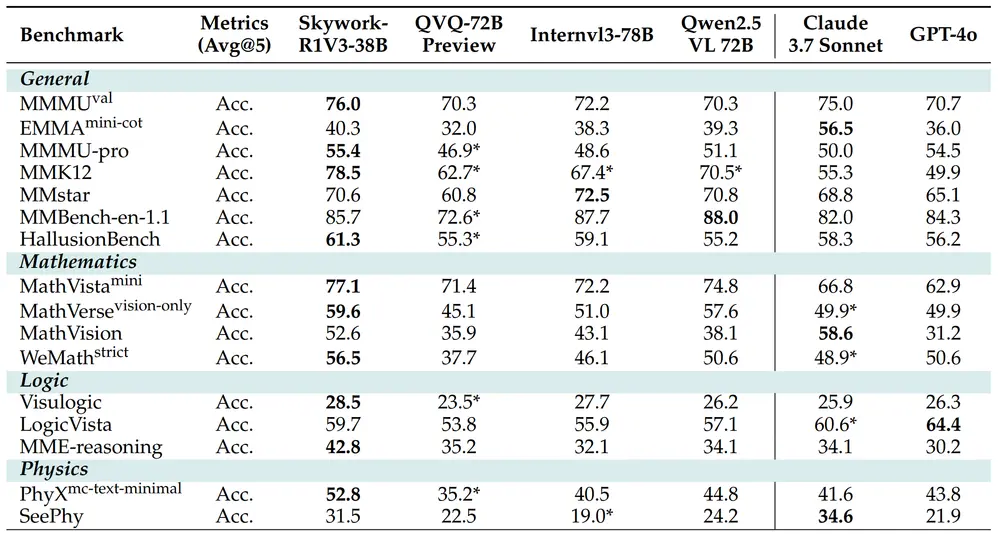
| 基准测试 | Skywork-R1V3-38B 得分 | 备注 |
|---|---|---|
| MMMU | 76.0 | 开源 SOTA,接近人类专家低值(76.2) |
| EMMA-Mini (CoT) | 40.3 | 开源最佳 |
| MMK12 | 78.5 | 开源最佳 |
| PhyX-MC-TM | 52.8 | 开源最佳 |
| SeePhys | 31.5 | 开源最佳 |
| MME-Reasoning | 42.8 | 超越 Claude-4-Sonnet |
| VisuLogic | 28.5 | 开源最佳 |
| MathVista | 77.1 | 数学问题解决能力强 |
| MathVerse | 59.6 | 表现优异 |
| MathVision | 52.6 | 出色推理能力 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











