联合研究团队:西南财经大学、上海交通大学、中南大学、Hithink研究院、西湖大学、哈尔滨工业大学、曼彻斯特大学、加州大学洛杉矶分校、阿德莱德大学、复旦大学、中国科学院深圳先进技术研究院
当AI开始替我们浏览网页、填写表单、完成购物,你是否曾想过:它究竟是“看图行事”,还是真的“理解”了任务?
近年来,基于多模态大模型的网络代理(Web Agent)在模拟人类操作网页方面取得了显著进展。但多数系统仍停留在“感知—执行”的表层模式,缺乏对任务本质的理解和推理能力。它们能“看见”按钮,却未必知道“为何点击”;能完成步骤,却难以应对变化。
为突破这一瓶颈,来自国内外11所高校与研究机构的联合团队提出了一种全新的认知架构——Web-CogReasoner。它不再依赖端到端的黑箱决策,而是从认知科学出发,系统性地构建代理的“知识体系”与“思维过程”。这项研究不仅提升了代理在复杂任务中的表现,也为AI如何“理解”数字世界提供了可解释的新路径。
一、从“模仿操作”到“理解任务”:认知能力的缺失
当前的网络代理大多依赖视觉或DOM信息,通过大量数据训练实现端到端的行为预测。这类方法在简单任务中表现尚可,但在面对新网站、新流程或动态干扰时,往往因缺乏深层理解而失败。
问题的核心在于:代理是否具备像人一样的“认知结构”?
受教育心理学中布卢姆分类法(Bloom’s Taxonomy)的启发,研究团队将代理的能力划分为两个核心阶段:
- 知识内容学习:掌握“是什么”——包括事实性与概念性知识;
- 认知过程执行:解决“如何做”——依赖程序性知识进行推理与规划。
基于这一划分,团队提出了Web-CogKnowledge 框架,并在此基础上开发了具备结构化认知能力的代理:Web-CogReasoner。

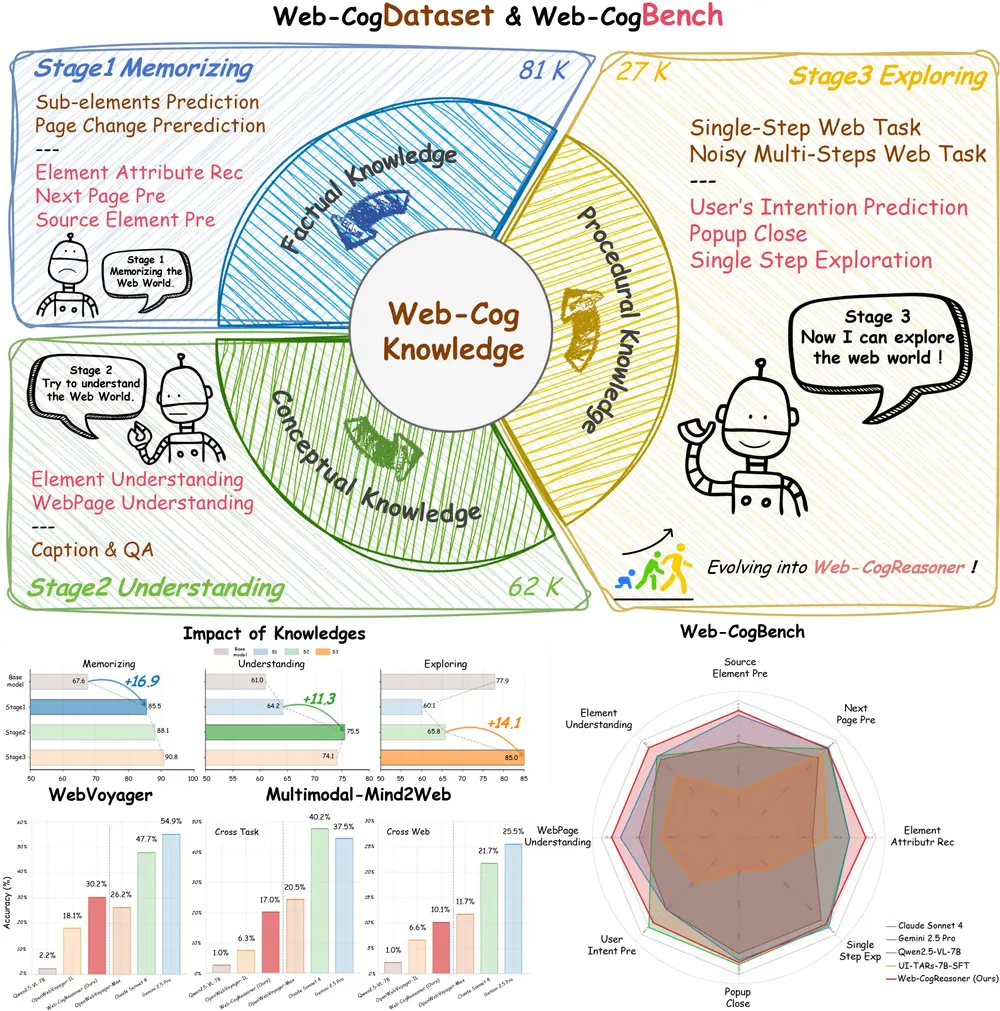
二、构建认知的“地基”:Web-CogDataset
要让代理“会思考”,首先得让它“有知识”。为此,团队构建了 Web-CogDataset ——一个系统化、课程式组织的知识训练集。
该数据集源自14个真实网站(涵盖电商、金融、社交等场景),包含12项渐进式任务,共21万样本,按知识类型分为三层:
1. 事实性知识(81K样本)
目标:训练代理识别网页中的具体元素与状态。
- 示例任务:识别按钮文本、预测点击后页面变化、判断某元素属于哪个父节点。
- 对应认知层级:记忆(Remember)
2. 概念性知识(62K样本)
目标:帮助代理理解界面背后的逻辑与语义。
- 示例任务:解释“购物车图标”的功能、说明页面布局的意图、回答“为什么这个字段是必填的”。
- 对应认知层级:理解(Understand)
3. 程序性知识(27K样本)
目标:教会代理如何规划并执行任务。
- 示例任务:预测用户下一步意图、关闭弹窗干扰、完成多步注册流程。
- 对应认知层级:应用与探索(Apply & Explore)
这种分层设计模拟了人类学习的过程:从记忆事实,到理解含义,再到实践应用,逐步建立完整的认知链条。
三、评估认知能力:Web-CogBench 基准发布
现有评估基准多关注任务完成率或视觉匹配精度,难以衡量代理是否真正“理解”了任务。为此,团队推出了 Web-CogBench ——首个专注于评估网络代理认知能力的测试套件。
该基准包含876个测试样本,覆盖三大认知维度:
| 认知能力 | 测试内容 | 关键指标 |
|---|---|---|
| 记忆 | 元素属性识别、下一页预测、源元素追溯 | ROUGE-L、准确率 |
| 理解 | 元素功能解释、页面语义分析 | LVM Judge(语义评分) |
| 探索 | 用户意图推断、弹窗处理、单步任务执行 | 准确率 |
每个任务都要求代理不仅输出动作,还需提供基于知识的推理过程。例如,在“关闭弹窗”任务中,模型不仅要做出正确操作,还需说明:“这是一个广告弹窗,不影响主任务,应关闭以减少干扰。”
🔍 亮点:Web-CogBench 将随论文开源,旨在推动社区对“认知型代理”的系统研究。
四、让推理“可追溯”:知识驱动的思维链(CoT)
传统思维链(Chain-of-Thought)推理常产生虚构或不一致的中间步骤。Web-CogReasoner 则引入了知识驱动的CoT机制,确保每一步推理都锚定在明确的知识类型上。
其推理流程分为三个层级,颜色编码便于追踪:
- 蓝色:事实性知识
- 问题:“页面上有什么?”
- 行为:提取DOM结构、ARIA标签、文本内容等可观测信息。
- 绿色:概念性知识
- 问题:“这个元素意味着什么?”
- 行为:推断按钮用途(如“提交订单”)、判断字段类型(如“密码输入框”)。
- 黄色:程序性知识
- 问题:“任务应该如何完成?”
- 行为:分解目标、规划步骤、处理异常(如验证码弹出)。
这种模块化、分阶段的推理结构,使整个决策过程可解释、可调试、可复现,也为后续优化提供了清晰路径。
五、实测表现:认知能力带来泛化优势
团队在多个基准上对比了 Web-CogReasoner 与其他主流模型的表现。
1. 认知 vs 视觉能力对比
| 模型 | Web-CogBench(认知) | VisualWebBench(视觉) |
|---|---|---|
| Claude Sonnet 4 | 76.8% | 85.9% |
| Gemini 2.5 Pro | 80.2% | 86.6% |
| Qwen2.5-VL-7B | 69.8% | 76.0% |
| UI-TARS-7B-SFT | 46.4% | 86.0% |
| Web-CogReasoner( ours) | 84.4% | 86.3% |
💡 关键发现:UI-TARS 虽在视觉任务中表现优异(86.0%),但在认知任务中大幅落后(46.4%),说明视觉感知强 ≠ 认知能力强。而 Web-CogReasoner 在两项指标上均达到领先水平。
2. 在线复杂任务泛化能力
| 模型 | WebVoyager(泛化) | Mind2Web(跨任务) | Mind2Web(跨网站) |
|---|---|---|---|
| Claude Sonnet 4 | 47.7% | 40.2% | 21.7% |
| Gemini 2.5 Pro | 54.9% | 37.5% | 25.5% |
| Qwen2.5-VL-7B | 2.2% | 1.0% | 1.0% |
| OpenWebVoyagerIL | 18.1% | 6.3% | 6.6% |
| Web-CogReasoner(ours) | 30.2% | 17.0% | 10.1% |
尽管当前最优模型(如Gemini)在封闭测试中表现更强,但 Web-CogReasoner 作为首个基于结构化认知框架的开源代理,在跨任务与跨网站场景中展现出显著优于其他开源模型的泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











