当前的大语言模型(LLMs)在处理短视频时已表现出强大能力,但面对数小时甚至跨集的长视频(如讲座系列、纪录片、剧集),它们往往力不从心——上下文窗口有限、计算成本高、跨场景语义断裂。
由香港大学与百度联合提出的新框架 VideoRAG,为这一难题提供了可扩展的解决方案。它不依赖重新训练模型,而是通过图结构知识组织 + 多模态检索增强,让任何现有 LLM 都能高效“读懂”超长视频。

为什么传统方法在长视频上失效?
现有的大型视频语言模型(LVLMs),如 VideoLLaMA、LLaVA-Video,通常:
- 逐帧或分段处理视频,无法跨越数小时建立语义连贯性;
- 受限于上下文长度(如 32K tokens),面对 10 小时视频只能“管中窥豹”;
- 纯文本 RAG(检索增强生成)忽略视觉与音频信号,丢失关键上下文。
结果:模型能回答“这一帧有什么”,却无法回答“主角在整部纪录片中如何转变立场”。
VideoRAG 的核心思想:不处理每一帧,只检索关键片段
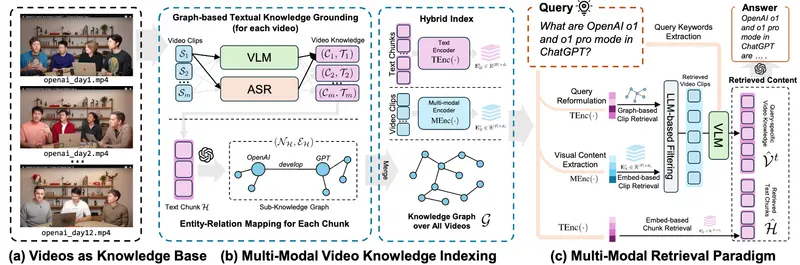
VideoRAG 是首个专为超长上下文视频设计的 RAG 框架。它不做全视频编码,而是构建一个混合索引系统,通过两步实现高效理解:
1. 基于图的文本知识定位(Graph-Based Text Knowledge Grounding)
- 从视频字幕、语音转录中提取实体(如人名、地点、概念);
- 构建知识图谱,节点为实体,边为关系(如“X 讨论了 Y”“Z 出现在第3集”);
- 该图谱天然支持跨视频、跨时段的语义关联,例如将“强化学习”与“OpenAI 第5天讲座”自动链接。
相比线性文本索引,图结构能捕捉“谁在何时说了什么”这一深层逻辑。
2. 多模态上下文编码(Multimodal Context Encoding)
- 使用多模态编码器(如 CLIP 或 Video-LLM)为关键视频片段生成嵌入;
- 这些嵌入融合了视觉、语音、文本三重信号;
- 查询与片段在统一向量空间中对齐,实现“语义检索”而非“关键词匹配”。
例如,用户问:“评分者在强化微调中起什么作用?”
VideoRAG 能从 OpenAI 12 天讲座系列(总时长超 60 小时)中,精准定位相关片段并合成答案。
免训练、即插即用
VideoRAG 无需微调任何模型,其架构包含:
- 检索层:图谱 + 多模态索引;
- 过滤与生成层:轻量级 LLM 模块,负责查询重写、片段筛选与答案合成。
这意味着:
- 可与 GPT-4、Claude、Llama 3 等任意 LLM 集成;
- 部署成本低,适合实际应用;
- 模型能力随 LLM 进化而自动提升。
实验验证:在 134 小时视频上超越现有方法
研究团队构建了 LongerVideos 基准数据集:
- 包含 160+ 视频,总时长 134 小时;
- 涵盖教育讲座、纪录片、娱乐节目三大类;
- 评估维度:全面性、深度、可信度、信息密度等。
结果表明,VideoRAG 在所有指标上显著优于现有视频 RAG 与 LVLM 方法。用户研究也显示,其生成的答案在语义连贯性与事实准确性上更受认可。
潜在应用场景
- 教育分析:从数十小时课程视频中提取知识脉络,辅助学习或教学;
- 媒体档案检索:快速定位纪录片中某观点的完整论述;
- 内容创作辅助:为编剧或记者提供跨集事件的时间线与角色关系;
- 企业知识管理:将内部培训视频转化为可搜索的知识库。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...