在当前多模态大模型(MLLM)普遍依赖数据驱动“试错式”解题的背景下,北京邮电大学、清华大学与腾讯的研究团队提出了一条不同的技术路径:让模型真正理解数学。
他们联合发布了 We-Math 2.0 —— 一个致力于系统性提升多模态模型数学推理能力的统一框架。不同于简单堆叠训练数据或优化提示工程,We-Math 2.0 的核心理念是:构建知识、结构化训练、渐进提升。
其目标明确:使多模态大模型不仅“会算”,更要“懂理”,具备应对开放、复杂数学问题的深度理解力与泛化能力。

为什么需要 We-Math?
当前多数多模态模型在面对数学问题时,尤其是涉及图形与符号结合的几何题、应用题,往往表现不稳定。原因在于:
- 缺乏系统性数学知识组织;
- 推理过程依赖模式匹配而非逻辑推导;
- 对视觉信息的理解停留在表层,难以与数学原理关联。
为此,We-Math 团队从基础出发,构建了一套完整的“知识—数据—训练—评估”闭环体系,推动多模态数学推理迈向更深层次。
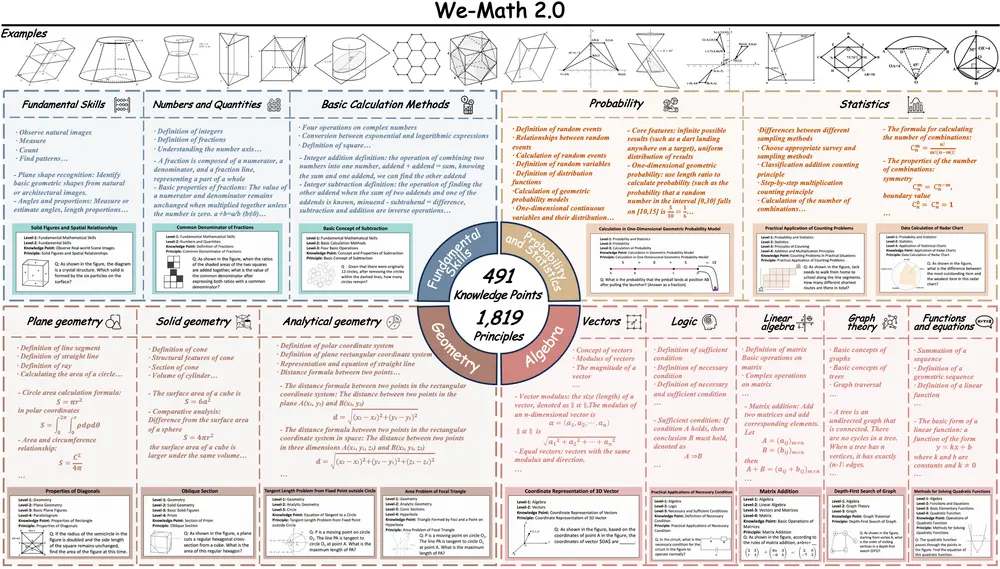
We-Math 2.0 的四大核心组件
1. MathBook:结构化的数学知识体系
We-Math 2.0 的基石是一个名为 MathBook 的五级层次化知识体系,包含:
- 491 个知识点(如“勾股定理”、“相似三角形判定”)
- 1,819 条基本原理(包括定义、定理、推论等)
这些内容源自维基百科、开源教材等可信来源,经由 AI 初筛与人工专家双重修订,确保准确性与教学逻辑性。知识以“领域 → 主题 → 子主题 → 概念 → 原理”的五层结构组织,形成可追溯、可扩展的知识图谱。
✅ 示例:在“几何”领域下,“三角形”主题包含“全等”“相似”等子主题,进一步细化到“SAS 判定准则”等具体原理。
这一知识体系不仅是训练基础,也为后续的数据生成与评估提供了统一标准。
2. MathBook-Standard:覆盖全面的基础训练集
基于 MathBook 构建的 MathBook-Standard 是一个高质量、原理级标注的数据集,旨在实现广泛且均衡的知识覆盖。
其关键设计是“双重扩展”策略:
- 一题多图:同一数学问题配以不同视觉表达(如不同角度的图形),增强模型对形式变化的鲁棒性;
- 一图多题:同一图像衍生多个问题(如求面积、角度、比例),提升模型对语义差异的敏感度。
所有图像均使用 GeoGebra 手工绘制,确保几何关系精确无误。该数据集覆盖全部 491 个知识点,特别加强了传统数据集中被忽视的冷门领域。
3. MathBook-Pro:面向难度进阶的挑战性数据集
如果说 MathBook-Standard 是“打基础”,那么 MathBook-Pro 就是“练高手”。
它引入了一个三维难度建模框架,从三个正交维度系统性地控制问题复杂度:
| 维度 | 描述 |
|---|---|
| 步骤复杂性 | 涉及的知识点数量。最多可组合 6 个以上知识点,形成深层推理链。 |
| 视觉复杂性 | 图形中添加辅助线、遮挡、变形等干扰项,考验模型对核心结构的识别能力。 |
| 语境复杂性 | 将抽象数学题转化为现实场景(如“小明测量旗杆影子”),增加语言理解和语义解析难度。 |
每个原始问题通过逐步叠加这三个维度,生成 7 个渐进式变体,构成一条清晰的学习路径。这为模型提供了类似“课程学习”的训练节奏。
4. MathBookEval:全面评估数学能力的新基准
为了真实衡量模型的数学理解水平,团队同步推出 MathBookEval —— 一个覆盖全部 491 个知识点的综合评测集。
其特点包括:
- 问题类型多样,涵盖代数、几何、概率、应用题等;
- 推理步骤分布广泛,从单步到多步递进;
- 注重知识迁移能力,避免模型依赖记忆或模板匹配。
该基准不再只看最终答案是否正确,更关注推理过程的合理性与知识调用的准确性。
训练方法:两阶段强化学习,实现渐进对齐
We-Math 2.0 的训练策略被称为 MathBook-RL,采用两阶段强化学习框架,引导模型从“知道”走向“会用”。
第一阶段:冷启动微调(Cold-Start Fine-tuning)
在 MathBook-Standard 上进行监督微调,目标是让模型初步建立“知识驱动”的思维链习惯。例如,在解几何题时,先识别涉及的知识点(如“平行线性质”),再据此展开推理。
这一步相当于为模型植入“知识意识”。
第二阶段:渐进式强化学习(Progressive Alignment RL)
分为两个子阶段:
(1)预对齐强化学习
在同一知识点下的多个变体上训练,计算平均奖励,鼓励模型在不同表现形式中保持推理一致性,而非依赖特定题目特征。
(2)动态调度强化学习
基于 MathBook-Pro 的难度轨迹,按“步骤 → 视觉 → 语境”顺序逐步提升挑战。
当模型在某一级失败时,系统会自动触发“增量学习”机制:
- 若因新增知识点失败 → 从 MathBook-Standard 中采样该知识点的辅助题;
- 若因视觉或语境干扰失败 → 提供单模态简化题进行专项训练。
这种“哪里不会补哪里”的动态调度策略,显著提升了训练效率与稳定性。
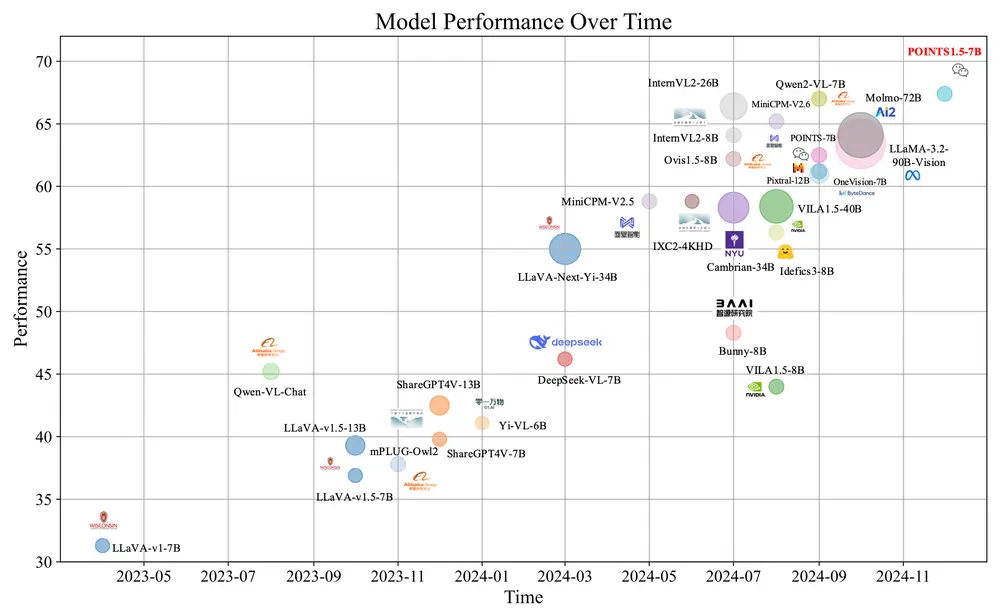
实验结果:全面领先,泛化能力突出
We-Math 2.0 在多个主流数学推理基准上表现优异:
| 基准 | 准确率 | 相比 Qwen2.5-VL-7B 提升 |
|---|---|---|
| MathVista | 48.7% | +6.1% |
| MathVision | 73.0% | +4.8% |
| We-Math | 28.0% | +2.9% |
| MathVerse | 48.4% | +7.4% |
在自建基准 MathBookEval 上,模型展现出更强的多步推理能力和几何理解深度,尤其在跨知识点组合任务中优势明显。
消融实验表明,知识体系引导和动态难度调度是性能提升的关键因素。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











