
多模态模型的快速发展为通用人工智能(AGI)的实现铺平了道路,但如何在保持跨任务泛化能力的同时提升专业推理能力,仍然是一个关键挑战。近期,天工AI(Skywork AI)推出了下一代多模态推理模型 Skywork R1V2,通过引入混合强化学习框架,显著提升了模型在复杂推理和通用视觉理解任务中的表现。
- GitHub:https://github.com/SkyworkAI/Skywork-R1V
- Hugging Face:https://huggingface.co/Skywork/Skywork-R1V2-38B
- 魔塔:https://modelscope.cn/models/Skywork/Skywork-R1V2-38B
多模态 AI 的核心困境
当前的多模态 AI 模型通常面临一个权衡:专注于复杂推理的“慢思考”模型(如 OpenAI-o1 和 Gemini-Thinking)在特定任务中表现出色,但在通用视觉理解任务上的性能却有所下降,甚至容易产生视觉幻觉。而过于强调泛化的模型,则可能在深度推理任务中表现不足。如何平衡这两者,成为推动多模态 AI 发展的关键问题。
Skywork R1V2 的创新解决方案
Skywork R1V2 是 Skywork R1V 的升级版,采用了全新的混合强化学习框架,结合奖励模型指导和基于规则的信号,以系统性地解决推理与泛化之间的权衡问题。以下是其核心技术亮点:
1. 混合强化学习框架
组相对策略优化 (GRPO)
GRPO 能够在同一查询组内的候选响应之间进行相对评估,从而更有效地提取学习信号。然而,这种机制可能导致收敛问题,削弱训练效果。选择性样本缓冲 (SSB)
SSB 通过维护一个信息丰富的样本缓存,确保模型能够持续访问高价值梯度,解决了 GRPO 中的收敛难题,进一步提高了训练的稳定性和效率。
2. 混合偏好优化 (MPO)
MPO 策略将基于奖励模型的偏好与基于规则的约束相结合,使模型在保持通用感知任务一致性的同时,加强逐步推理的质量。这种混合优化方法不仅提升了模型的推理能力,还降低了视觉幻觉的发生率。
3. 模块化训练架构
R1V2 在冻结的 Intern ViT-6B 视觉编码器和预训练语言模型之间引入轻量级适配器。这种设计保留了语言模型的推理能力,同时高效优化了跨模态对齐,确保模型在多模态任务中的表现更加稳健。
实证结果:领先的性能表现
Skywork R1V2 在一系列推理和多模态基准测试中表现出色,超越了许多同等或更大规模的开源基线模型,并缩小了与专有模型的性能差距。
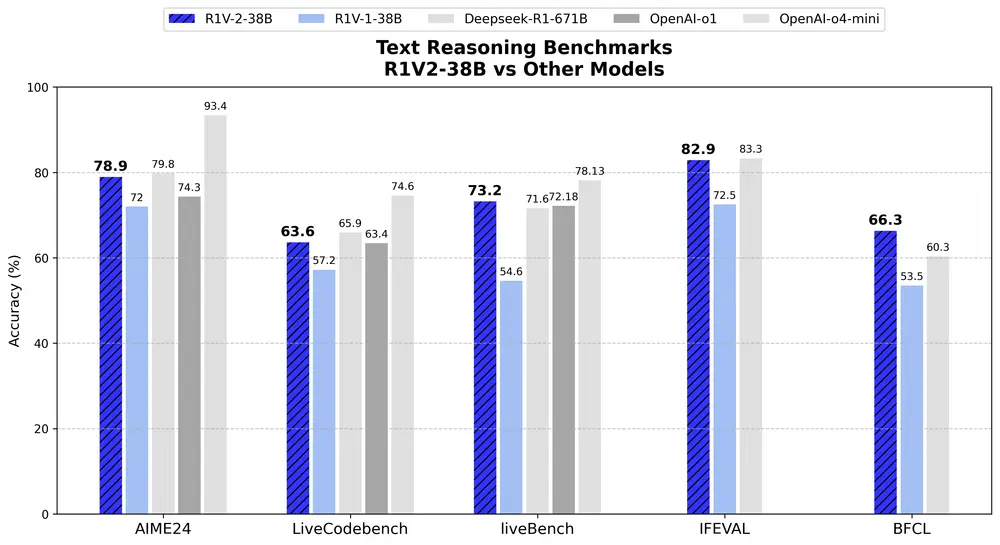
文本推理任务
AIME2024: 78.9% LiveCodeBench: 63.6% LiveBench: 73.2% IFEVAL: 82.9% BFCL: 66.3%
这些成绩相较于 Skywork R1V1 显著提升,并且在某些任务上可与参数量更大的模型(如 Deepseek R1, 参数量 671B)相媲美。
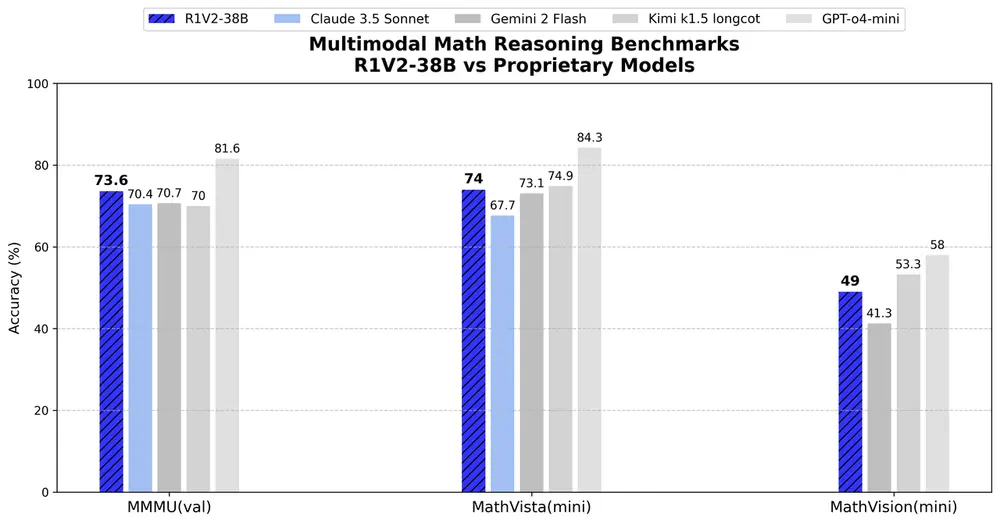
多模态任务
MMMU: 73.6% MathVista: 74.0% OlympiadBench: 62.6% MathVision: 49.0% MMMU-Pro: 52.0%
R1V2 在多模态任务中同样表现出色,尤其是在需要跨视觉和文本输入进行结构化问题解决的任务中。它超越了包括 Qwen2.5-VL-72B 和 QvQ-Preview-72B 在内的多个开源基线模型,并在部分任务上超过了 Claude 3.5 Sonnet 和 Gemini 2 Flash 等专有模型。
视觉幻觉控制
通过校准的强化策略,R1V2 将视觉幻觉率降低至 8.7%,在复杂的推理过程中保持了事实的完整性。
定性分析:系统性问题解决能力
除了定量指标外,R1V2 在定性评估中也展现了卓越的表现。模型在复杂的科学和数学任务中表现出条理清晰的分解和验证行为,例如:
在数学问题中,能够逐步推导并验证每一步的结果; 在科学推理任务中,能够识别关键变量并提出合理的假设。
这些特性表明,R1V2 更接近于人类的反思性认知模式,能够以系统化的方式解决复杂问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











