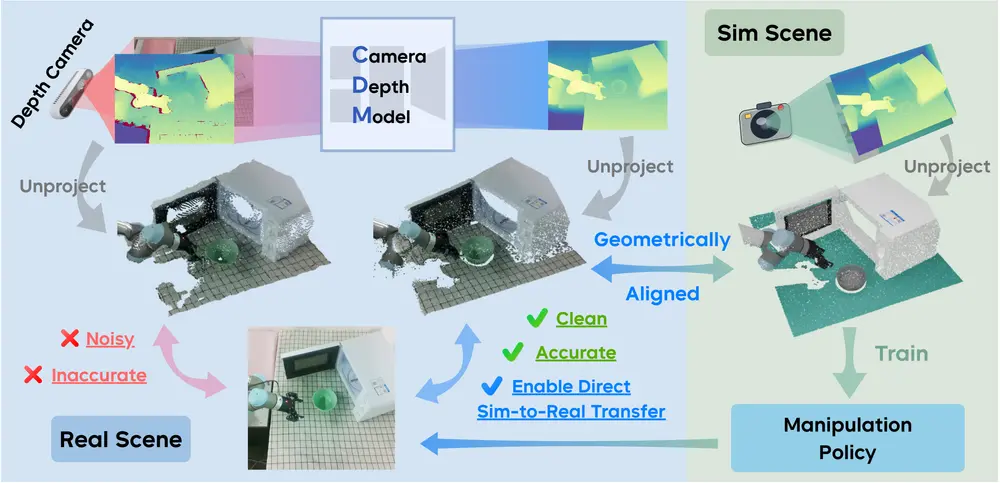
阿里Qwen团队在发布Qwen3系列模型后,又推出Qwen2.5-Omni系列的一个新模型Qwen2.5-Omni-3B,这是一个端到端多模态模型,能够无缝处理文本、图像、音频和视频等多种输入形式,并通过实时流式响应同时生成文本与自然语音合成输出。
- GitHub:https://github.com/QwenLM/Qwen2.5-Omni
- Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-3B
- 魔塔:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-3B
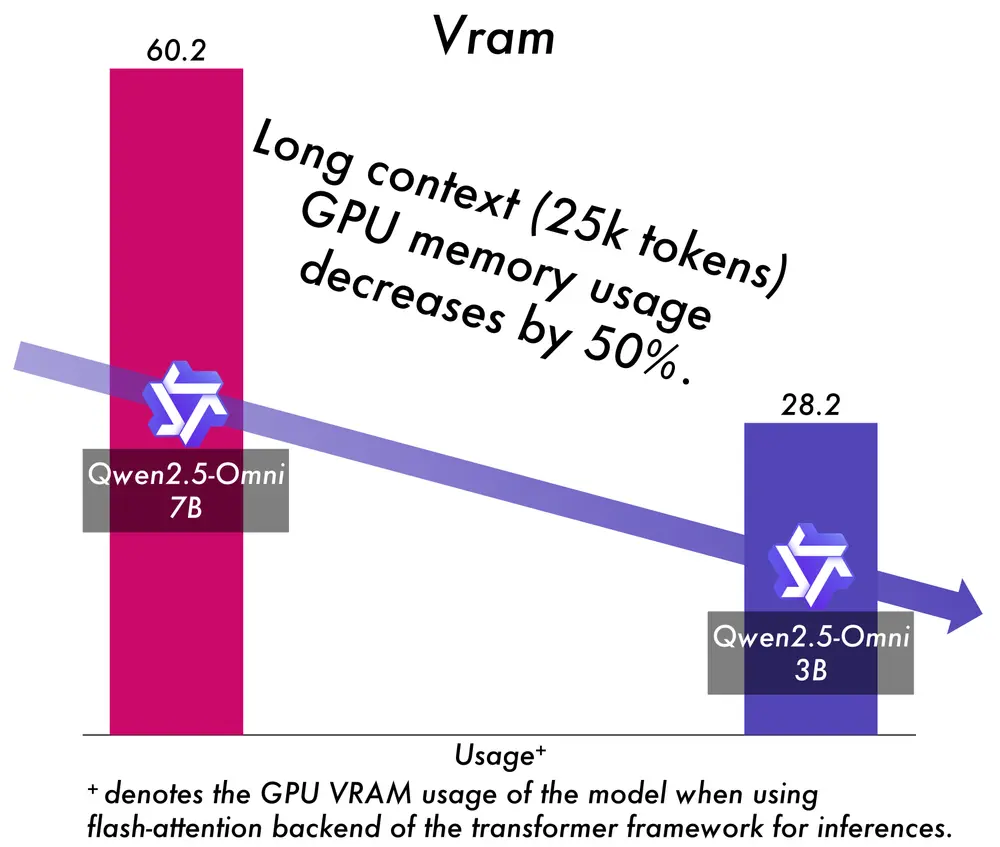
- 与之前发布的 Qwen2.5-Omni-7B 模型相比,3B 版本在长上下文序列处理(约 25k 个 token)中实现了令人瞩目的 50%+的 VRAM 消耗降低,同时在典型的 24GB 消费级 GPU 上支持扩展的 30 秒音视频交互。
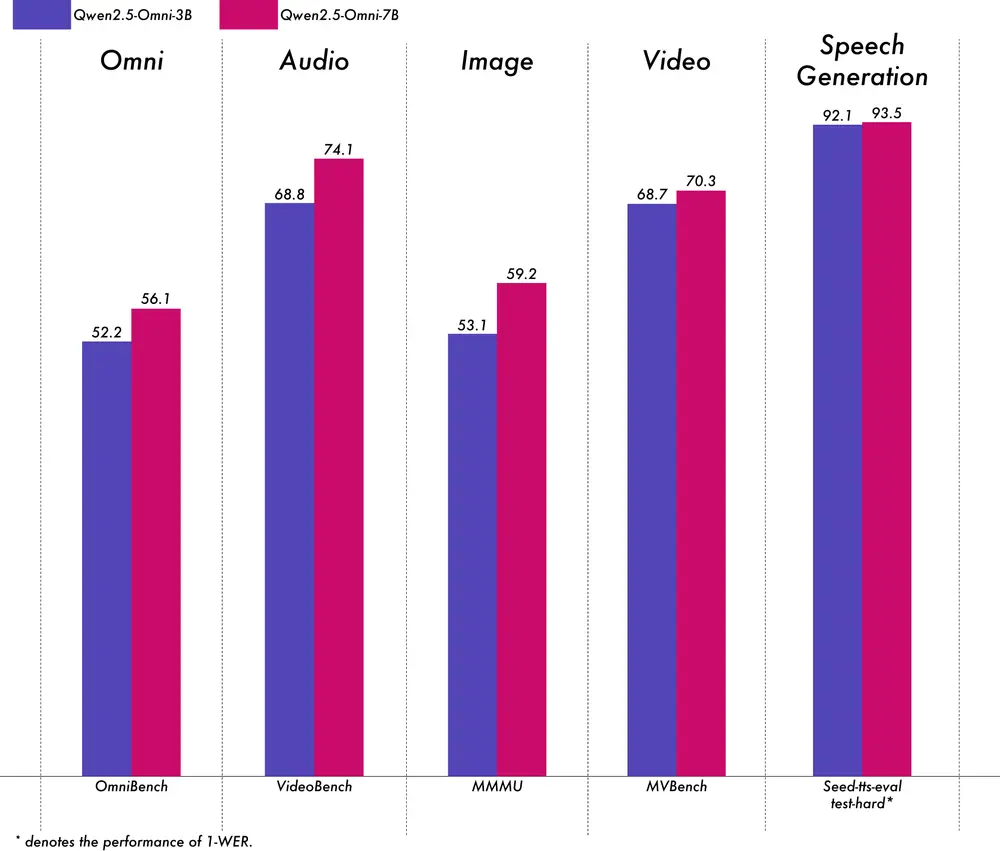
- 保留了 7B 模型的 90%+的多模态理解能力,自然语音输出的准确性和稳定性与 7B 版本相当。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











