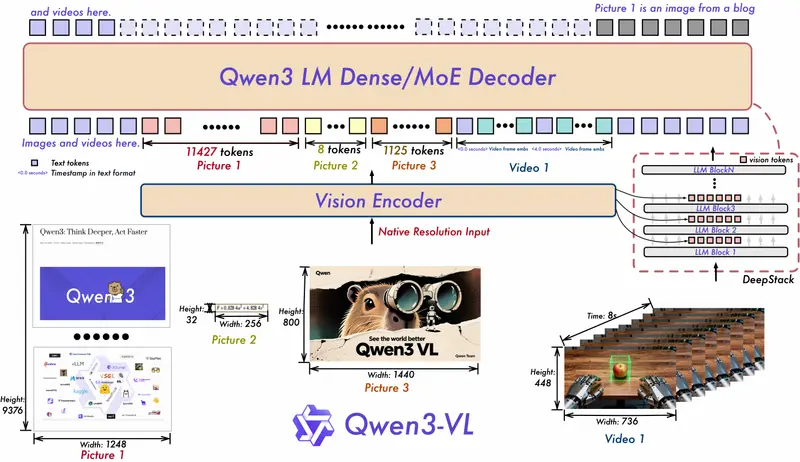
阿里通义实验室 Qwen 项目组正式推出全新升级的 Qwen3-VL 系列——这是截至目前 Qwen 多模态体系中能力最全面、性能最先进的视觉语言模型(Vision-Language Model, VLM)。
- 官方博文:https://qwen.ai/blog
- GitHub:https://github.com/QwenLM/Qwen3-VL
- Hugging Face:https://huggingface.co/collections/Qwen/qwen3-vl-68d2a7c1b8a8afce4ebd2dbe
- 魔塔:https://modelscope.cn/collections/Qwen3-VL-5c7a94c8cb144b
本次发布的旗舰型号为 Qwen3-VL-235B-A22B,包含两个版本:
- Instruct 版本:面向通用任务,在主流视觉感知评测中达到甚至超越 Gemini 2.5 Pro;
- Thinking 版本:专注复杂推理,在 MathVision、MMMU 等权威多模态推理基准上取得当前开源模型最佳表现。
该模型已全面开源,标志着中国在高端多模态大模型领域的又一次重要突破。

不止“看得见”,更要“看得懂”
Qwen3-VL 的核心目标,是让大模型从“图像识别”迈向“世界理解”。它不仅能够解析像素内容,更能:
- 理解事件逻辑
- 推理空间关系
- 执行真实任务
- 生成可运行代码
换句话说,Qwen3-VL 正在推动视觉语言模型从“感知系统”向“认知代理”演进。
核心能力升级:十大关键维度全面提升
1. 视觉智能体(Visual Agent):可操作的真实交互
Qwen3-VL 能够理解 GUI 元素、识别按钮功能,并调用工具完成端到端任务。
在 OS World 等具身智能基准测试中表现达到世界领先水平,适用于自动化办公、手机助手、RPA 场景。
示例:上传一张 App 截图 → 模型自动点击“登录”按钮 → 填写账号信息 → 提交表单。
2. 纯文本能力媲美顶级 LLM
尽管是多模态模型,其文本能力并未妥协。通过早期融合文本与视觉模态进行协同训练,Qwen3-VL 在纯文本任务上的表现与同级纯语言模型 Qwen3-235B-A22B-2507 相当,真正实现“文基扎实、多模全能”。
3. 视觉编程:所见即所得的代码生成
支持将设计图转化为可执行前端代码:
- 输入手绘草图或 UI 截图
- 输出 HTML/CSS/JS 或 Draw.io 可编辑格式
- 支持视频转动态页面逻辑代码
极大提升设计师与开发者的协作效率。
4. 空间感知能力跃升
- 2D 定位由绝对坐标改为相对坐标表示,更符合人类直觉;
- 支持判断遮挡、视角变化、方位关系;
- 新增 3D bounding box 预测能力,还原物体在真实空间中的位置与尺寸,为机器人导航、AR/VR 提供基础支持。
5. 长上下文与长视频理解
全系列原生支持 256K token 上下文长度,可通过扩展机制处理高达 1M tokens 的输入。
这意味着:
- 整本教材、数百页 PDF 可一次性输入;
- 两小时以上的视频内容可完整记忆;
- 视频问答能精确定位到秒级时间点。
在“视频大海捞针”实验中,即使面对 1M token 的超长序列,模型仍保持 99.5% 的准确率。
6. 多模态思考能力显著增强
Thinking 版本重点强化 STEM 与数学推理能力:
- 在 MathVision、MathVista、MMMU 等复杂多学科评测中达到 SOTA;
- 能分析因果链、拆解步骤、验证中间结果;
- 对图表题、几何题、物理情境题的理解更加深入。
7. OCR 多语言与复杂场景覆盖
- 支持语言从 10 种扩展至 32 种,涵盖希腊语、希伯来语、印地语、泰语等;
- 在模糊、倾斜、低光照等实拍条件下稳定性更强;
- 对古籍字、生僻字、专业术语识别准确率显著提升;
- 超长文档结构还原能力增强,支持图文混排精细解析。
8. 万物识别:覆盖日常生活与专业领域
模型具备广泛的对象识别能力,可准确识别:
- 名人、动漫角色、商品品牌
- 动植物种类、地标建筑
- 医疗影像、工业零件、电路图
满足教育、电商、社交、科研等多场景需求。
9. 创意写作与内容生成
根据图片或视频生成高质量描述性文本,适用于:
- 短视频脚本创作
- 商品文案撰写
- 新闻摘要生成
- 故事续写与情节推演
10. 复杂指令遵循与多轮对话
支持多条件、嵌套逻辑、分步执行类指令,例如:
“如果这张照片中有猫且背景是户外,请找出它的品种并推荐三个适合的名字;否则,请说明原因。”
同时增强多图理解与跨轮次记忆能力,可在连续讨论中保持上下文一致性。
技术架构创新:三大关键升级
✅ MRoPE-Interleave:更鲁棒的位置编码
传统 MRoPE 将时间、高度、宽度特征按顺序分块,导致时间信息集中在高频维度。
Qwen3-VL 改为 t-h-w 交错分布,实现对时空信息的全频率覆盖,显著提升长视频建模能力。
✅ DeepStack:多层次视觉特征注入
不再仅在 LLM 第一层输入视觉 token,而是采用 多层注入机制,将 ViT 不同层级的特征逐步融入语言模型深层结构,提升图文对齐精度与细节捕捉能力。
✅ 时间戳对齐机制取代 T-RoPE
引入“时间戳-视频帧交错输入”机制,实现帧级别的时间与内容细粒度对齐。支持输出“秒数”和“时:分:秒”两种格式,在事件定位、动作边界检测等任务中响应更精准。
此外,模型还优化了视觉特征 token 化策略,保留从底层边缘纹理到高层语义概念的完整信息流。
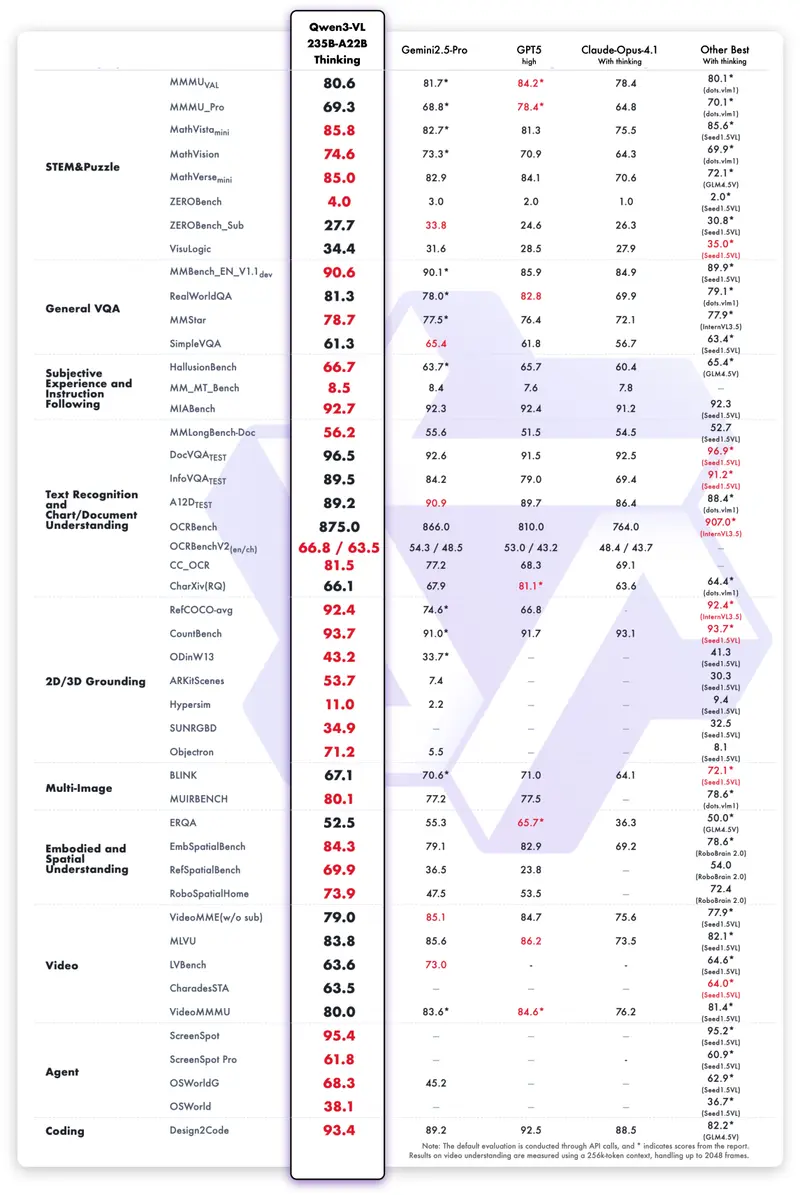
性能对比:开源之光,逼近闭源 SOTA
我们在十个维度评估了 Qwen3-VL 的综合能力,包括:
| 维度 | 表现 |
|---|---|
| 视觉问答(VQA) | 显著优于 Gemini 2.5 Pro(非推理类) |
| 数学与科学推理 | Thinking 版本在 MathVision 上超过 Gemini |
| 文档理解 | 多页 PDF、扫描件解析能力领先 |
| OCR 多语言 | 32 种语言可用,中文场景尤其出色 |
| Agent 任务执行 | OS World 排行榜前列,优于多数闭源模型 |
| 代码生成 | 设计图转前端代码成功率高,结构合理 |
虽然在部分跨模态推理和视频理解任务上仍略逊于顶尖闭源模型(如 GPT-5),但在 Agent 能力、文档理解、2D/3D grounding 等方向展现出明显优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











