在构建基于视觉语言模型(VLM)的 GUI 代理系统中,一个关键挑战是如何准确理解屏幕上的视觉内容并定位应执行操作的区域。传统方法通常将此问题建模为“文本到坐标的生成”任务,即通过语言描述预测具体像素位置。然而,这类方法存在多个局限性,包括空间语义对齐弱、监督信号模糊以及与视觉特征粒度不匹配等。
微软最新研究提出了一种全新的解决方案——GUI-Actor,它摒弃了传统的坐标预测方式,转而采用基于注意力机制的动作头,直接从视觉块标记中提取动作区域,实现了更贴近人类行为的 GUI 操作定位方式。
- 项目主页:https://microsoft.github.io/GUI-Actor
- GitHub:https://github.com/microsoft/GUI-Actor
- 模型:https://huggingface.co/microsoft/GUI-Actor-7B-Qwen2-VL
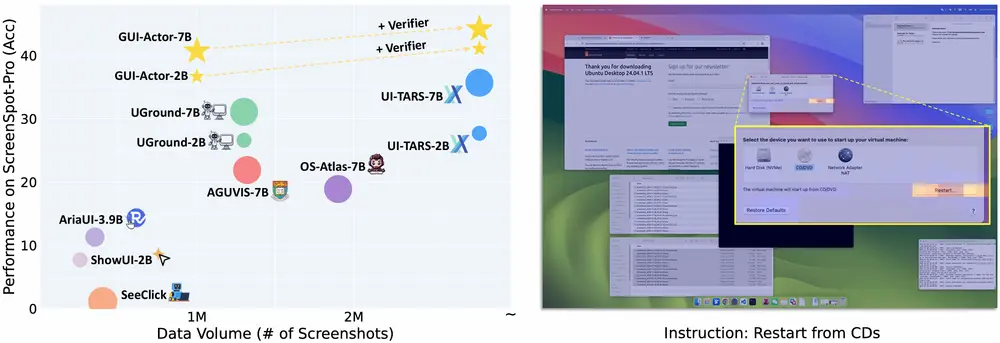
该成果已在多个 GUI 动作定位基准测试中取得当前最优性能,甚至超越了更大规模的模型(如 UI-TARS-72B),展现了其强大的泛化能力与实用性。
传统方法的局限性:坐标预测为何不够用?
尽管已有多种基于 VLM 的 GUI 代理尝试使用“文本+图像输入 → 坐标输出”的模式进行交互推理,但这些方法普遍存在以下问题:
📉 1. 空间-语义对齐较弱
由于缺乏显式的空间监督,模型难以精准捕捉视觉元素与语言指令之间的映射关系,导致动作定位偏差较大。
⚠️ 2. 监督信号模糊
单点坐标预测容易惩罚合理的动作变化,例如点击按钮的不同位置都应视为有效操作,但传统方法却可能将其判定为错误。
🧱 3. 视觉与动作空间粒度不一致
现代视觉模型(如 Qwen2-VL)通常基于“块”(patch-based)表示提取特征,而坐标预测依赖于连续空间,二者之间存在结构性不匹配。
GUI-Actor 的核心思想:从“找坐标”到“选区域”
GUI-Actor 提出了一种无坐标的动作区域识别方法,其设计灵感来自人类操作界面的方式:我们不会计算具体的 x/y 像素值,而是直接感知目标区域并与之互动。
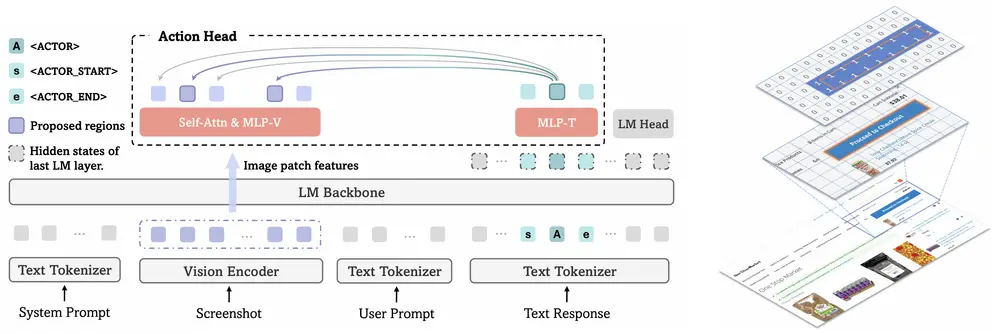
🔍 核心创新点如下:
✅ 注意力驱动的动作头(Attention-Based Action Head)
引入一个特殊的 <ACTOR> 标记,通过自注意力机制,与所有相关的视觉块(vision patch)进行对齐。这种方式使模型能够:
- 在一次前向传播中提出多个候选动作区域
- 支持多对象交互或多步骤操作(如先点击菜单再选择子项)
- 更自然地适配现代 VLM 的“块级”视觉表示结构
✅ 定位验证器(Localization Verifier)
为了进一步提升动作区域的准确性,团队设计了一个独立的定位验证模块,用于评估和筛选由动作头提出的候选区域,选出最合理的一个作为最终执行位置。
这一模块具备良好的扩展性,可与其他定位方法结合使用,进一步提升整体表现。
实验结果:优于现有 SOTA 方法,展现强泛化能力
在多个 GUI 动作定位基准测试中,GUI-Actor 表现出色:
| 模型 | 参数量 | ScreenSpot-Pro 得分 |
|---|---|---|
| UI-TARS-72B | 720亿 | 38.1 |
| GUI-Actor-7B(Qwen2-VL) | 70亿 | 40.7 |
| GUI-Actor-7B(Qwen2.5-VL) | 70亿 | 44.6 |
📈 可见,GUI-Actor 不仅超越了此前最先进的模型,还展现出更强的适应性与泛化能力。
🌟 分布外泛化优势显著
在 ScreenSpot-Pro 这类具有更高分辨率、布局偏移的分布外场景下,GUI-Actor 显著优于其他方法:
- GUI-Actor-2B 超过基线 +9.0 分;
- GUI-Actor-7B 超过 +5.0 分。
这种提升主要归因于其显式空间-语义对齐机制,使得模型能更稳健地应对不同屏幕尺寸与界面布局的变化。
轻量化训练也能实现高性能
微软团队进一步探索了 GUI-Actor-LiteTrain 的训练策略,即:
- 冻结骨干 VLM 所有参数
- 仅微调新增的动作头与特殊标记
令人惊讶的是,即使只调整约 1亿参数(占总模型的极小部分),GUI-Actor-LiteTrain 仍取得了与完全微调模型相当甚至更好的性能。
这表明:
- 骨干 VLM 已具备出色的界面理解能力;
- 问题的关键在于如何更好地引导其输出“动作区域”,而非重新学习视觉语义;
- GUI-Actor 在不牺牲通用能力的前提下,成功赋予 VLM 强大的 GUI 定位能力。
无需额外成本的多区域预测
得益于基于注意力的机制,GUI-Actor 可以在单次前向传播中生成多个候选动作区域,而不会增加推理时间开销。
实验结果显示,在 Hit@k 指标 下,GUI-Actor 在 Hit@1 到 Hit@3 之间有明显提升,说明多个候选区域确实有助于覆盖更多有效操作路径。
相比之下,传统方法即使多次采样,也往往集中在同一区域附近,缺乏多样性。而 GUI-Actor 的注意力机制天然支持互斥、多样化的区域预测,极大提升了真实场景下的鲁棒性。
迈向更智能、更贴近人类的 GUI 代理系统
微软提出的 GUI-Actor 是 GUI 操作领域的一次重要突破,其核心贡献包括:
| 创新方向 | 实现方式 | 效果 |
|---|---|---|
| 动作区域识别 | 使用 <ACTOR> 标记与视觉块对齐 | 更精确的空间-语义匹配 |
| 多区域预测 | 注意力机制原生支持 | 提升覆盖完整操作路径的能力 |
| 定位验证机制 | 引入验证器模块 | 提高动作区域选择的合理性 |
| 轻量化集成 | 仅微调动作头 | 保留 VLM 原始能力的同时获得定位功能 |
| 泛化能力 | 对未见分辨率/布局适应性强 | 更广泛适用于真实应用场景 |
GUI-Actor 不仅解决了传统方法中的诸多限制,也为未来构建基于 VLM 的智能助手、自动化测试工具、数字助理系统提供了新的技术思路。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











