
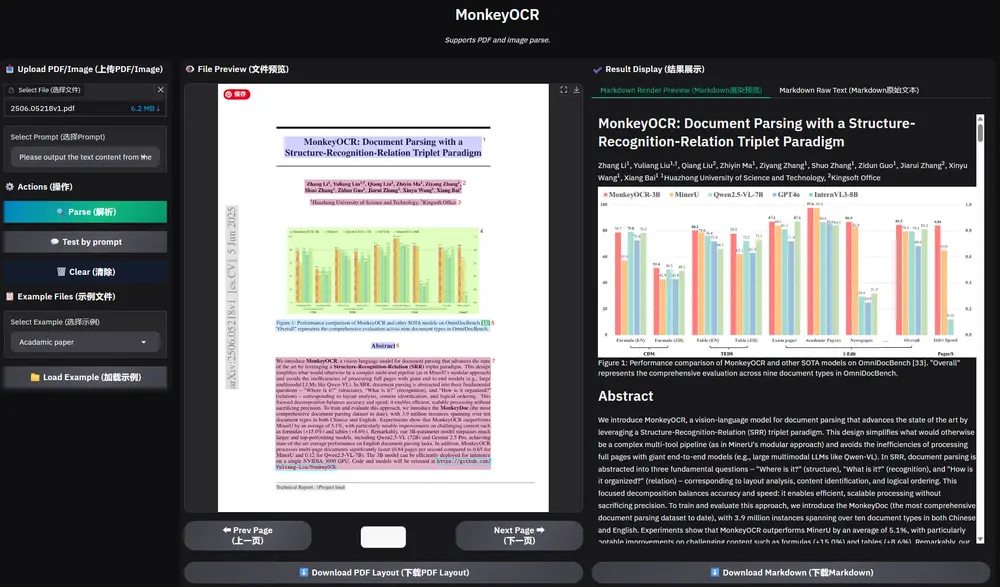
近日,华中科技大学与金山办公联合研究团队发布了一款全新的文档解析模型 —— MonkeyOCR。该模型通过引入“结构-识别-关系”(Structure-Recognition-Relation, SRR)三元组范式,有效解决了当前文档解析方法在准确性、效率与灵活性之间的权衡难题。
- GitHub:https://github.com/Yuliang-Liu/MonkeyOCR
- 模型:https://huggingface.co/echo840/MonkeyOCR
- Demo:http://vlrlabmonkey.xyz:7685
为什么需要MonkeyOCR?
现有的文档解析方法通常存在两大问题:
- 流程复杂:基于流水线的方法依赖多个独立工具依次处理布局分析、文本识别、表格提取等任务,步骤繁琐且容易出错;
- 效率低下:端到端多模态模型虽然统一了处理流程,但在整页文档上推理速度慢,尤其在处理多页长文档时表现不佳。
针对这些问题,MonkeyOCR提出了一个全新的三阶段解析框架,将复杂的文档解析任务拆解为三个基本子任务:结构检测、内容识别与关系预测。
🔍 MonkeyOCR的核心技术:SRR三元范式
MonkeyOCR采用结构-识别-关系(SRR)三元范式,融合了模块化方法的可解释性与端到端架构的全局优化能力,具体流程如下:
- 结构检测
使用基于YOLO的文档布局检测器,识别文档中的语义区域(如文本块、表格、公式等),并输出每个区域的边界框和类型。 - 块级内容识别
对每个区域进行裁剪,并结合特定类型的提示词输入大型多模态模型(LMM),完成内容识别。 - 关系预测
利用专门设计的阅读顺序模型,预测各区域之间的逻辑顺序,并按此顺序组装最终的结构化输出。
这一方法不仅提升了处理效率,也保证了高精度,尤其适用于包含多种元素的复杂文档(如学术论文、教科书、手写笔记等)。
🚀 性能优势显著,超越现有主流方案
在OmniDocBench基准测试中,MonkeyOCR展现出卓越性能:
| 指标 | 提升幅度 |
|---|---|
| 公式识别准确率 | +15.0% |
| 表格识别准确率 | +8.6% |
| 中英文文档整体平均性能 | +5.1% |
与主流方法对比结果如下:
| 模型 | 英文文档平均性能 | 多页文档处理速度(页/秒) |
|---|---|---|
| MinerU | - | 0.65 |
| Qwen2.5-VL-7B | - | 0.12 |
| Gemini 2.5 Pro | - | - |
| MonkeyOCR(3B参数) | 最佳 | 0.84 |
此外,MonkeyOCR在单页文档上的处理速度达 0.24页/秒,远超当前主流模型。

✅ 主要功能与特点
功能支持
- 文档解析:将非结构化的多模态文档(文本、表格、图像、公式等)转换为结构化数据。
- 多语言支持:涵盖中文与英文文档解析。
- 多文档类型:适用于学术论文、教科书、手写笔记、报纸等多种场景。
技术优势
- 高效性:模块化设计+块级并行处理,显著提升解析速度,尤其擅长处理多页文档。
- 准确性:在多项任务(如公式、表格识别)中达到领先水平。
- 灵活性:兼顾传统管道方法的可解释性与端到端架构的简洁性。
⏳ 当前限制与未来计划
目前,MonkeyOCR主要面向扫描版或排版清晰的电子文档,暂不支持拍摄文档(如照片、模糊图像)。但研究人员表示,后续版本将持续优化并扩展至更多使用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











