英伟达正式发布了 Llama Nemotron Nano VL —— 一款专为高效处理复杂文档设计的轻量级视觉-语言模型(VLM)。该模型基于 Llama 3.1 架构构建,在保持高性能的同时兼顾推理效率,适用于表格解析、财务报告理解和多模态文档问答等实际应用场景。
这款模型不仅展示了英伟达在 VLM 领域的技术积累,也为资源受限环境下的部署提供了实用方案。

🧠 模型架构与核心技术亮点
✅ 核心组成
Llama Nemotron Nano VL 是一个结合了先进视觉编码器和语言模型的多模态系统:
- 视觉编码器:采用 CRadioV2-H,轻量且具备高分辨率捕捉能力
- 语言模型:基于 Llama 3.1 8B 进行指令微调,支持复杂任务交互
- 跨模态对齐:通过投影层与旋转位置编码实现图像补丁与文本之间的精准融合
✅ 上下文长度与多图支持
该模型支持最长 16K token 的上下文长度,能够同时处理多个图像和长文本输入,非常适合处理如多页合同、扫描报告或带图表的论文等复杂文档任务。
🔧 训练流程与优化策略
Nemotron Nano VL 的训练分为三个阶段,确保其在多种任务中表现优异:
| 阶段 | 目标 |
|---|---|
| 阶段 1 | 在大规模图文数据集上进行预训练,学习基本的视觉-语言联合表示 |
| 阶段 2 | 多模态指令微调,增强用户提示理解与交互响应能力 |
| 阶段 3 | 补充纯文本指令数据,提升在标准语言模型基准上的表现 |
整个训练过程依托英伟达自研框架 Megatron-LLM 和 Energon 数据加载器,并在 A100/H100 GPU 集群上进行分布式训练,确保高质量输出。
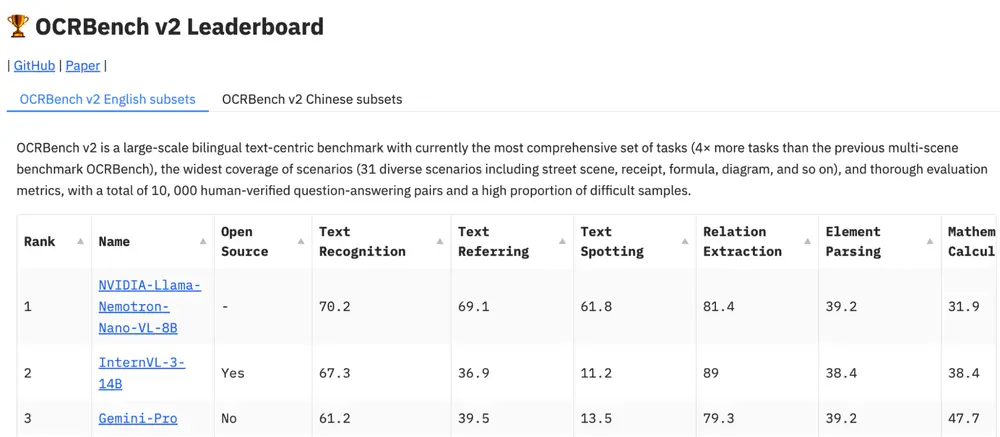
📊 基准测试结果:OCR 与结构化信息提取表现出色
为了验证 Nemotron Nano VL 的文档理解能力,英伟达将其在 OCRBench v2 基准上进行了评估。该基准专注于文档级别的多模态理解任务,包括:
- OCR 提取
- 表格结构识别
- 图表解读
- 跨模态问答
结果显示:
- 在紧凑型视觉-语言模型中达到 SOTA 级别准确率
- 特别擅长从表格、键值对和布局依赖问题中提取结构化信息
- 具备良好的泛化能力,可应对非英语文档与低质量扫描件
这些表现表明,Nemotron Nano VL 不仅能在实验室环境下表现良好,在现实世界的应用中也具备高度实用性。
🚀 部署灵活:边缘设备也能跑得动
考虑到企业级应用对部署灵活性的需求,英伟达为 Nemotron Nano VL 提供了多种优化选项:
- 4-bit 量化版本(AWQ):显著降低内存占用,适用于 Jetson Orin 等边缘设备
- TinyChat / TensorRT-LLM 支持:加速推理,提高吞吐量
- ONNX / TensorRT 导出:兼容不同硬件平台,提升部署适配性
- 预计算视觉嵌入:进一步减少静态文档处理时的延迟
此外,该模型还支持 模块化 NIM(NVIDIA Inference Microservices),简化 API 接入流程,方便集成到现有系统中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











