
NitroGen 是由英伟达开发的开放性具身智能基础模型(foundation model for embodied agents),旨在通过观察人类玩家的游戏视频,直接学习从原始画面到手柄动作的映射。该模型不依赖奖励信号或任务目标,而是通过大规模行为克隆(behavior cloning)在超过 40,000 小时、1,000+ 款商业游戏的公开视频上进行训练,探索视觉-动作智能的泛化能力。
- 项目主页:https://nitrogen.minedojo.org
- GitHub:https://github.com/MineDojo/NitroGen
- 模型:https://huggingface.co/nvidia/NitroGen
NitroGen 1 是该系列的首个版本,仅供学术研究与非商业开发使用。

核心目标:探索具身智能的“涌现”能力
与大型语言模型类似,NitroGen 的研究动机是验证:在足够多样、大规模的人类行为数据上进行模仿学习,是否能激发出跨任务、跨环境的通用操作能力?
这一路径试图绕过传统强化学习对奖励函数和环境仿真的依赖,直接从“人类怎么做”中学习“智能体该如何做”。
适用场景与局限
✅ 效果最佳的游戏类型(手柄为主):
- 3D 动作游戏(如《战神》《鬼泣》)
- 2D 平台跳跃(如《空洞骑士》《蔚蓝》)
- 竞速/驾驶类(如《马里奥赛车》)
- 程序生成开放世界(如《我的世界》)
❌ 效果有限的游戏类型(依赖键鼠):
- RTS(如《星际争霸》)
- MOBA(如《英雄联盟》)
- 高精度鼠标操作类游戏
原因:模型输出为手柄动作空间(方向键、ABXY、摇杆等),无法直接映射鼠标坐标或复杂键位组合。
关键技术特点
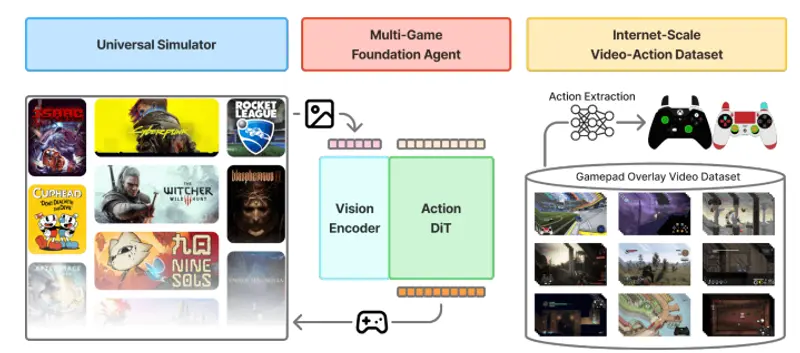
1. 大规模视频-动作数据集构建
- 数据来源:YouTube 等平台的公开游戏录屏,其中玩家操作以“输入覆盖”(input overlay)形式实时显示(如屏幕角落的按键提示)。
- 自动标注:通过模板匹配 + 分割网络,从视频帧中提取按键/摇杆状态,构建帧级动作标签。
- 规模:40,000+ 小时,覆盖 1,000+ 游戏,无需人工标注。
2. 模型架构:基于扩散的视觉-动作映射
- 视觉编码器:采用 SigLIP-ViT 等强视觉 backbone,提取游戏画面语义特征
- 动作生成器:基于 DiT(Diffusion Transformer)架构,通过条件流匹配(Conditional Flow Matching)生成未来动作序列
- 输入:单帧或短序列 RGB 图像
- 输出:标准化手柄动作(如摇杆 [-1,1]、按键 [0/1])
3. 训练与迁移范式
- 预训练:在全量数据集上进行行为克隆,学习通用游戏策略
- 微调:在新游戏中仅需数小时人类演示数据,即可适配特定任务(如 Boss 战、关卡通关)
- 零样本迁移:在未见过的游戏中,直接运行预训练模型即可完成基础操作
评估与性能
研究团队构建了 NitroBench——一个包含 10 款商业游戏、30 项任务的标准化评估套件,涵盖战斗、探索、平台跳跃、资源收集等场景。
主要结果:
- 零样本任务成功率:相比从头训练的基线,NitroGen 预训练模型在未见游戏中平均提升 52%
- 数据效率:在仅 30 小时演示数据下微调,即可在 3D 动作游戏中达到高难度任务的稳定执行
- 跨类型泛化:同一模型在 2D/3D、固定视角/自由视角、线性关卡/开放世界等不同范式中均表现稳健
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











