传统视频生成模型在生成长视频时,常因高维时空信号的复杂性而难以维持长期的空间与时间一致性——场景结构漂移、物体位置突变、相机运动不连贯等问题普遍存在。
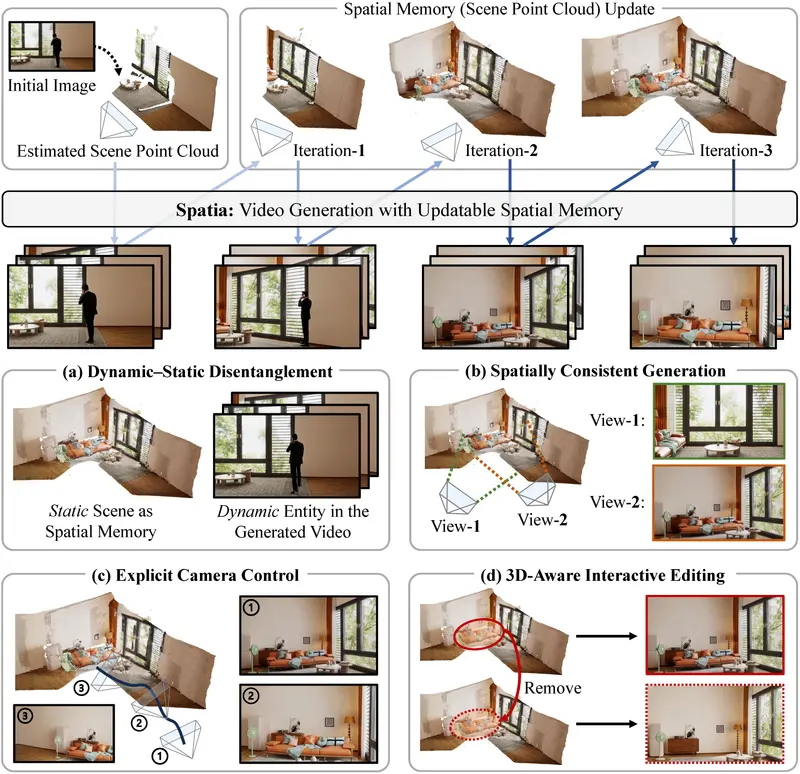
为解决这一挑战,悉尼大学、微软研究院、香港科技大学与滑铁卢大学联合提出 Spatia —— 一个空间记忆感知的视频生成框架。Spatia 通过显式构建并持续更新一个3D 场景点云作为持久空间记忆,将静态场景与动态内容解耦,在生成逼真运动的同时,确保整个视频在几何与结构上的长期一致性。
核心思想:用“记忆”代替“猜测”
Spatia 的关键洞察是:视频生成不应仅依赖前几帧的像素信息,而应维护一个可更新的 3D 场景表征。
该表征(即“空间记忆”)由去动态化的场景点云构成,在生成过程中被视觉 SLAM 算法持续优化,并作为后续片段生成的几何约束。
这种设计实现了:
- 动态-静态解耦:动态实体(人物、车辆)由扩散模型生成,静态环境由点云记忆固定
- 跨视角一致性:无论相机如何移动,场景结构始终保持稳定
- 长期可扩展性:支持多轮迭代生成,形成“闭环”轨迹(如相机绕行后返回原点)
技术实现
1. 两阶段训练流程
- 空间记忆构建(图 a)
从输入视频中移除动态区域,利用多视角几何方法重建静态场景点云,并从指定视角渲染为 2D 条件图。 - 参考帧检索(图 b)
基于点云重叠度,从历史帧中检索空间上最相关的参考片段,提供时间上下文。 - 多模态扩散生成(图 c)
采用扩散变换器(Diffusion Transformer),在文本指令 + 空间记忆 + 时间上下文三重条件下生成新视频片段。
2. 迭代生成与记忆更新
- 生成:以当前点云 + 历史帧为条件,输出新片段
- 更新:通过轻量级视觉 SLAM,将新帧中的静态结构融合进点云,修正漂移、补充细节
- 循环:新点云用于下一轮生成,形成“生成 → 观测 → 更新 → 再生成”闭环
核心能力
| 能力 | 说明 |
|---|---|
| 空间一致性生成 | 从不同视角生成同一场景,建筑、道路等静态元素位置严格对齐 |
| 显式相机控制 | 用户指定 3D 相机轨迹 → 系统渲染对应点云序列 → 引导视频生成 |
| 3D 意识交互编辑 | 直接修改点云(如删除一棵树、添加广告牌),生成视频自动反映变更 |
| 文本+动态内容生成 | 在固定场景中,按文本指令生成动态元素(如“飞过一架无人机”) |
实验结果
- WorldScore 基准:Spatia 以 69.73 分 领先现有方法,在静态结构保真度与动态内容自然度上均表现最优。
- 闭环一致性测试:在相机绕行后返回起点的场景中,Spatia 在 PSNR、SSIM、LPIPS 上显著优于基线,证明其长期几何稳定性。
- 多片段自回归生成:成功生成 2/4/6 段连续视频,即使经历复杂运动,场景仍保持连贯,无结构崩塌。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











