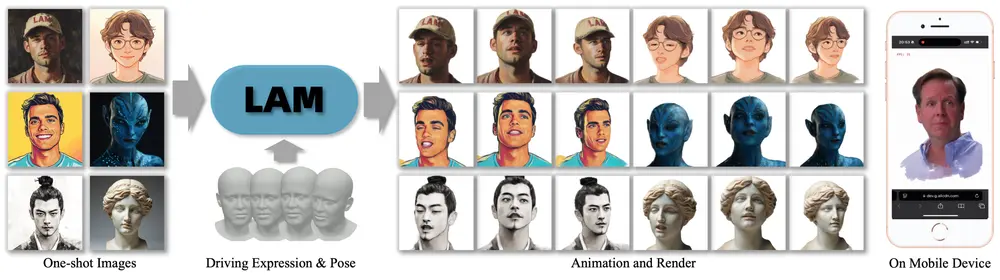
阿里巴巴通义实验室推出新型单次拍摄可动画化的高斯头部模型 LAM(Large Avatar Model),能够从单张图像中生成可动画化且可渲染的高斯头像。与以往需要大量视频序列训练或依赖辅助神经网络进行动画和渲染的方法不同,LAM 可以在单次前向传递中生成立即可动画化和渲染的高斯头像,支持实时动画和渲染,适用于各种平台,包括移动设备。
- 项目主页:https://aigc3d.github.io/projects/LAM
- GitHub:https://github.com/aigc3d/LAM
- 模型:https://huggingface.co/3DAIGC/LAM-20K
- Demo:https://huggingface.co/spaces/3DAIGC/LAM
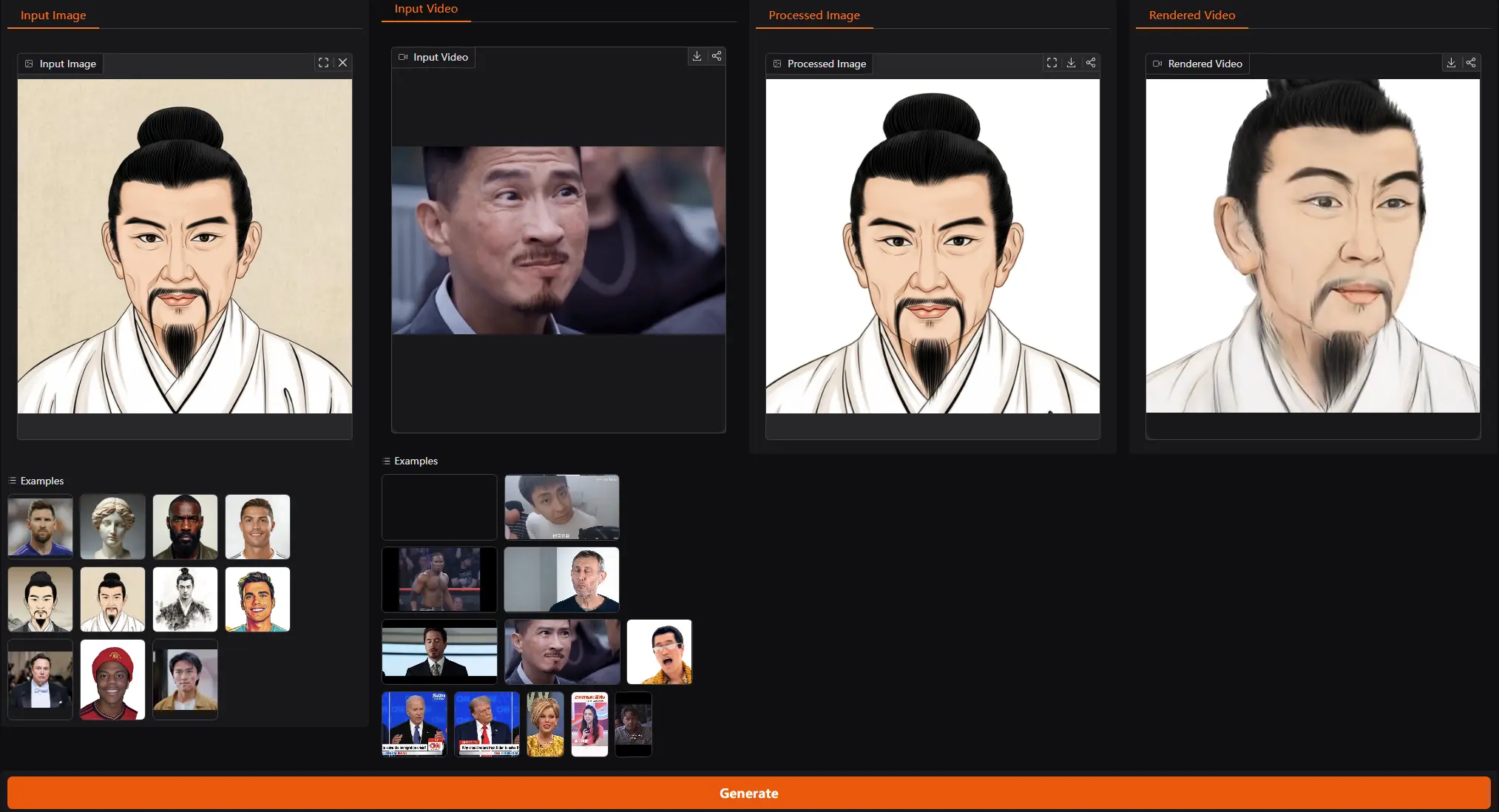
LAM 的核心目标是从单张图像中重建出可动画化的高斯头像,并使其能够与背景场景自然融合。例如,给定一张人物照片,LAM 可以生成一个高斯头像,并根据目标光照条件或背景图像进行实时动画化和渲染。这种方法在在线会议、影视制作、游戏行业和虚拟现实等领域具有广泛的应用前景。
主要功能
- 单次拍摄生成:仅通过单张图像,LAM 可以生成一个可动画化的高斯头像,无需额外的视频数据或复杂的神经网络后处理。
- 实时动画和渲染:生成的高斯头像可以利用标准的线性混合蒙皮(LBS)和修正混合形状进行动画化,并在各种平台上实时渲染。
- 背景融合:生成的头像可以与目标背景图像自然融合,支持实时动画和渲染。
- 文本到头像生成:支持从文本提示生成可动画化的高斯头像,并进行风格化编辑。
主要特点
- 高效性:LAM 通过单次前向传递生成可动画化的高斯头像,无需额外的神经网络或后处理步骤,显著提高了生成效率。
- 实时性:生成的头像可以实时动画化和渲染,适用于各种计算平台,包括移动设备。
- 高质量重建:通过利用 FLAME 模型的先验形状信息和多尺度图像特征,LAM 能够生成高质量的头像,保留细节和身份一致性。
- 风格化编辑:支持从文本提示生成头像,并进行风格化编辑,例如改变年龄或转换为卡通风格。
工作原理
- 核心框架:LAM 的核心是规范化的高斯属性生成器,使用 Transformer 网络从单张图像中提取多尺度特征,并利用 FLAME 模型的规范点作为查询,通过交叉注意力机制预测规范空间中的高斯属性。
- 规范化空间重建:所有高斯头像在规范空间中重建,具有相同的表情和姿态,简化了重建问题,并便于在推理时进行动画化。
- 动画化:利用 FLAME 模型的动画权重,将重建的规范高斯点动画化到目标姿态和表情。动画化后的高斯头像可以通过高斯绘制(splatting)过程渲染成最终图像。
- 风格化编辑:通过文本到图像生成框架(如 Stable Diffusion)生成目标肖像图像,然后通过 LAM 创建可动画化的高斯头像,并进行风格化编辑。
应用场景
- 在线会议:在视频会议中,LAM 可以实时生成和渲染高质量的虚拟头像,提升用户体验。
- 影视制作:在影视后期制作中,LAM 可以用于生成高质量的虚拟角色,支持实时动画和渲染。
- 游戏行业:在游戏开发中,LAM 可以快速生成可动画化的虚拟角色,支持实时渲染,提升游戏性能。
- 虚拟现实:在虚拟现实应用中,LAM 可以生成与虚拟环境自然融合的虚拟头像,提升沉浸感。
- 社交媒体:用户可以通过上传单张照片生成个性化的虚拟头像,并进行风格化编辑,用于社交媒体分享。
实验结果
LAM 在多个基准数据集上的表现优于现有的最先进方法。例如,在 VFHQ 数据集上,LAM 的 PSNR、SSIM 和 LPIPS 指标均优于其他方法,同时在实时渲染速度上具有显著优势。此外,LAM 还支持从文本提示生成可动画化的高斯头像,并进行风格化编辑,展示了其在生成多样化头像方面的潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











