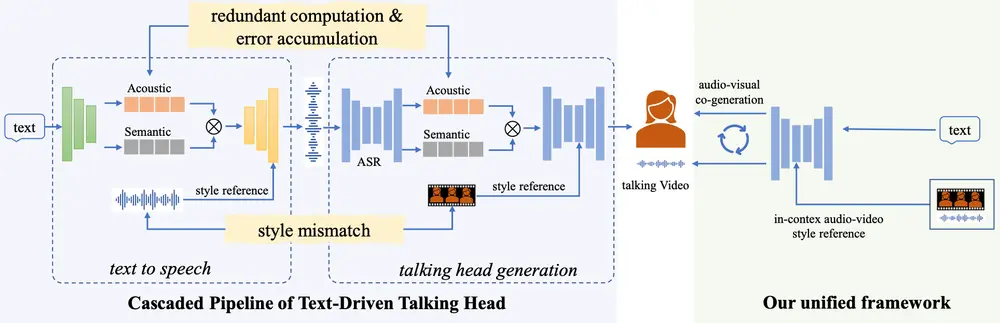
阿里通义实验室推出新型实时文本驱动的说话头像生成框架OmniTalker ,能够在零样本(zero-shot)场景下同时生成同步的语音和说话头像视频,同时保留语音风格和面部风格。OmniTalker 通过端到端的统一框架解决了现有方法中存在的计算冗余、错误累积和音视频风格不匹配等问题。
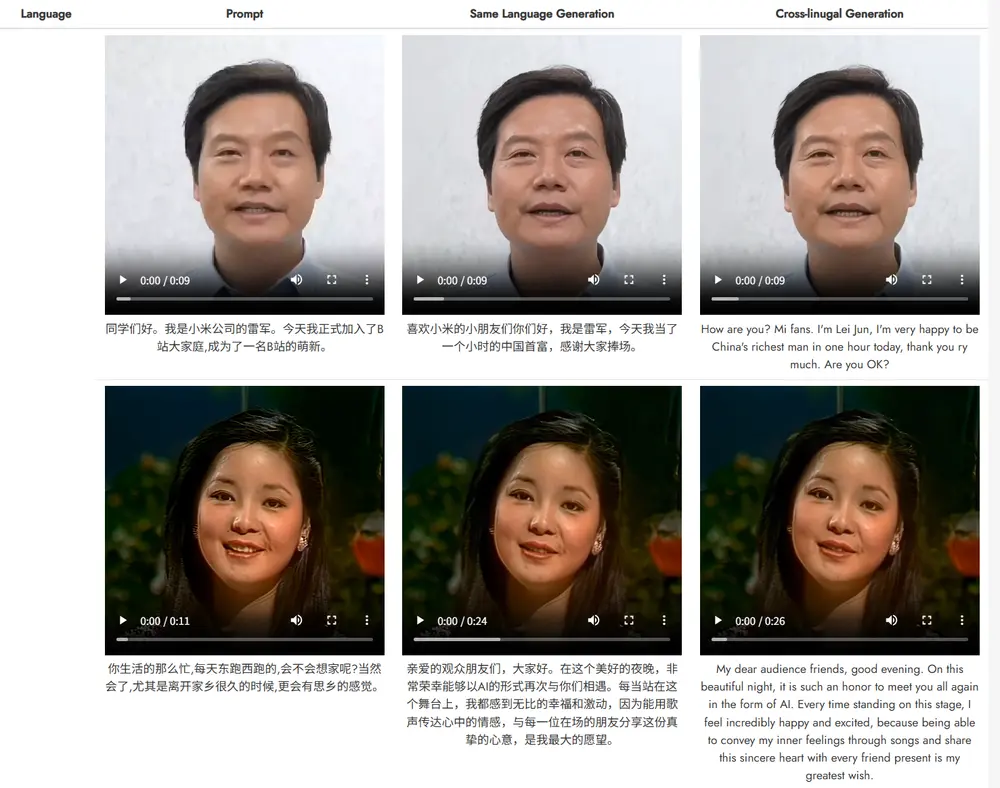
OmniTalker 的核心目标是从文本输入生成同步的语音和说话头像视频,同时保留参考视频中的语音风格和面部风格。例如,给定一段文本和一个参考视频,OmniTalker 可以生成一个与参考视频风格一致的说话头像视频,同时生成与之同步的语音。这种方法在虚拟助手、在线教育、视频会议等领域具有广泛的应用前景。
主要功能
- 同步语音和视频生成:从文本输入同时生成语音和说话头像视频,确保音视频同步。
- 风格保留:能够从参考视频中学习并保留语音风格和面部风格,实现风格一致的生成。
- 实时生成:支持实时推理,生成速度达到 25 FPS,适用于实时交互场景。
- 零样本学习:无需针对新身份或风格进行额外训练,直接从参考视频中学习风格特征。
主要特点
- 统一的多模态框架:通过双分支扩散变换器(DiT)架构,同时处理音频和视频生成任务,确保音视频的同步和风格一致性。
- 上下文风格学习:通过上下文参考学习模块,从单个参考视频中捕获语音和面部风格特征,无需额外的风格提取模块。
- 高效的训练和推理:采用流匹配(Flow Matching)技术进行训练,结合紧凑的模型架构(0.8 亿参数),实现高效的训练和实时推理。
- 大规模数据集支持:通过自动化数据管道构建高质量的多模态数据集,支持大规模训练。
工作原理
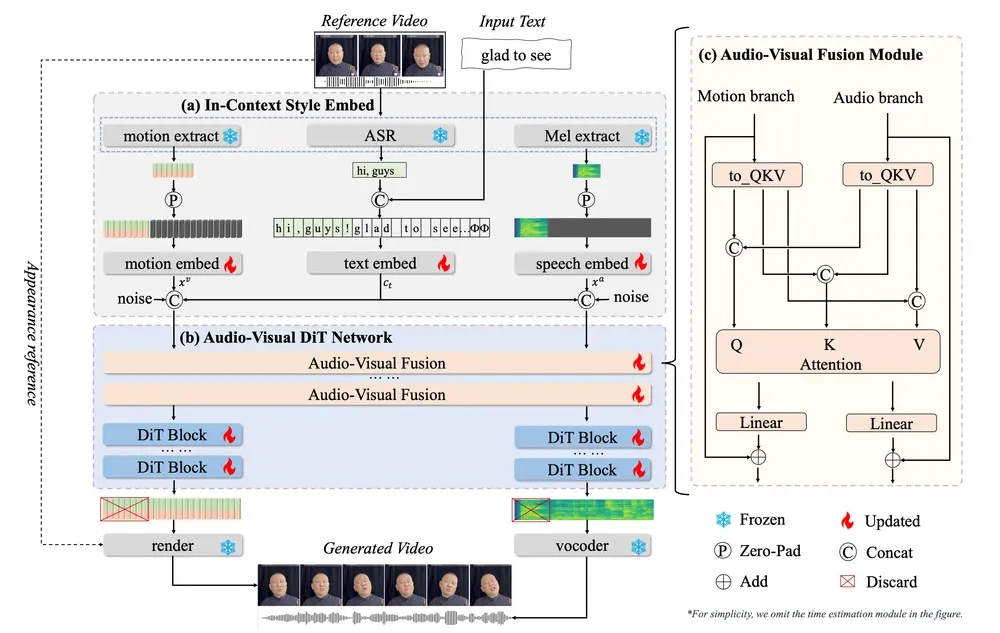
- 输入表示:
- 文本输入:将输入文本和参考文本转换为拼音序列或字符序列,并通过 ConvNeXt-V2 模块提取文本嵌入。
- 音频特征:从参考视频中提取音频特征(如梅尔频谱图),并将其与文本嵌入对齐。
- 视觉特征:从参考视频中提取面部表情、头部姿态和眼部运动的特征,并将其投影到视觉嵌入中。
- 多模态融合:
- 音频-视觉融合模块:通过多模态注意力机制(MM-Attn)将音频和视觉特征进行融合,确保生成的视频与音频在时间上对齐,并保持风格一致性。
- 单模态 DiT 块:在融合后的多模态特征基础上,分别对音频和视觉特征进行细化处理,生成高质量的音频和视频输出。
- 音频和视频解码:
- 音频解码:使用 Vocos 高保真语音合成器将梅尔频谱图解码为语音。
- 视频渲染:基于预测的头部姿态和面部表情,使用基于变形的 GAN 模型生成视频帧,支持实时渲染。
- 上下文风格学习:
- 在训练阶段,通过随机遮蔽参考视频的一部分,迫使模型学习参考视频的风格特征,而无需额外的风格提取模块。
- 在推理阶段,丢弃参考部分,仅保留最终输出。
- 流匹配训练:
- 使用流匹配技术训练模型,通过优化概率路径的变换过程,提高训练效率和生成质量。
实验结果
实验表明,OmniTalker 在多个关键指标上优于现有的文本驱动说话头像生成方法。例如,在语音质量评估中,OmniTalker 的词错误率(WER)显著低于基线模型,表明其在音频生成模块中具有更高的预测准确性。在视频质量评估中,OmniTalker 在 PSNR、SSIM、FID 和 FVD 等指标上均取得了最佳性能,特别是在风格保留方面表现出色。此外,OmniTalker 的实时推理能力使其在实际应用中具有显著优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











