
英伟达联合斯坦福大学、加州大学圣地亚哥分校、加州大学伯克利分校和德克萨斯大学奥斯汀分校的研究人员,通过引入 Test-Time Training(TTT)层,成功让预训练的 DiT 模型能够从文本故事板生成长达一分钟的视频。这项研究以经典的《猫和老鼠》动画为概念验证,展示了模型生成连贯、复杂且具有动态运动的多场景故事视频的能力。
- 项目主页:https://test-time-training.github.io/video-dit
- GitHub:https://github.com/test-time-training/ttt-video-dit
TTT-Video:让 AI 创作长视频成为可能
TTT-Video 是一个用于微调 DiT 模型以实现风格迁移和上下文扩展的开源项目。研究人员通过在模型中加入 TTT 层,处理全局上下文中的长距离关系,同时重用原始预训练模型的注意力层,对每个三秒片段进行局部注意力处理。这种方法不仅保留了预训练模型的优势,还显著提升了模型对长序列的处理能力。

在这个项目中,研究人员提供了支持生成最长 63 秒视频的训练和推理代码。他们首先在原始预训练的 3 秒视频长度上微调模型,加入 TTT 层以实现风格迁移。随后,通过分阶段对 9 秒、18 秒、30 秒和 63 秒的视频长度进行训练,逐步扩展模型的上下文处理能力。
模型架构:基于 CogVideoX 5B 的改进
TTT-Video 的架构基于 CogVideoX 5B 模型,这是一个用于文本到视频生成的扩散变换器。研究人员在其中加入了 TTT 层进行优化,保留了原始预训练的注意力层,用于对每个 3 秒片段及其对应文本进行局部注意力处理。此外,TTT 层被插入以处理全局序列及其反向版本,其输出通过残差连接进行门控。
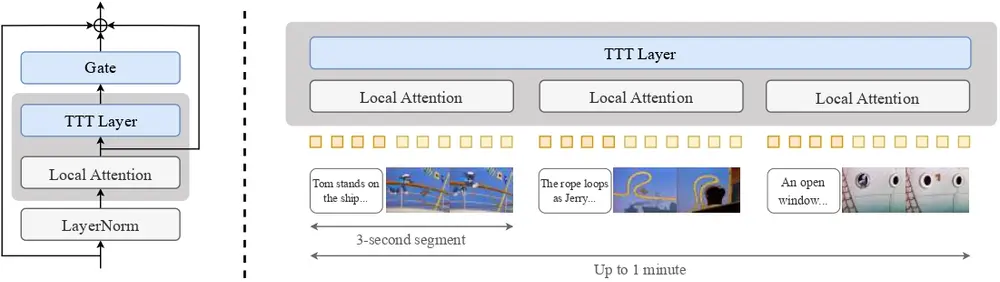
为了将上下文扩展到超过预训练的 3 秒片段,研究人员将每个片段与文本和视频嵌入交错排列。这种设计使得模型能够在处理长序列时保持连贯性和动态运动。
主要功能与特点
长视频生成
- 功能:能够从文本故事板生成长达一分钟的视频,支持复杂的多场景故事。
- 特点:通过多阶段微调策略,逐步扩展模型的上下文长度,适应更长的视频生成任务。
动态运动和连贯性
- 功能:生成的视频具有连贯的场景过渡和自然的动态运动。
- 特点:TTT 层的引入显著提升了模型对长序列的处理能力,使得生成的视频更加流畅和自然。
文本到视频的映射
- 功能:根据详细的文本描述(如故事板)生成对应的视频内容。
- 特点:将文本故事分解为多个 3 秒的片段,每个片段通过文本和视频标记的组合输入到模型中,模型在每个片段上独立应用局部自注意力,而 TTT 层则全局处理整个序列。
高效的长序列处理
- 功能:TTT 层的隐藏状态可以是神经网络,因此比传统的 RNN 层更具表现力,能够处理复杂的长序列。
- 特点:通过内循环小批量更新和片上张量并行技术,优化了 TTT 层的训练和推理过程,使其能够高效处理长序列。
工作原理
预训练模型的选择
- 以预训练的扩散变换器(CogVideo-X 5B)为基础,该模型原本只能生成 3 秒的视频片段。
TTT 层的集成
- 在预训练模型中插入 TTT 层,并通过微调使其能够处理长达一分钟的视频。TTT 层通过在测试时对隐藏状态进行训练(即测试时训练),从而能够处理长序列。
多阶段微调
- 采用多阶段微调策略,逐步扩展上下文长度,从 3 秒逐步增加到 63 秒。
文本到视频的映射
- 将文本故事分解为多个 3 秒的片段,每个片段通过文本和视频标记的组合输入到模型中。模型在每个片段上独立应用局部自注意力,而 TTT 层则全局处理整个序列。
并行化和优化
- 通过内循环小批量更新和片上张量并行技术,优化了 TTT 层的训练和推理过程,使其能够高效处理长序列。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











