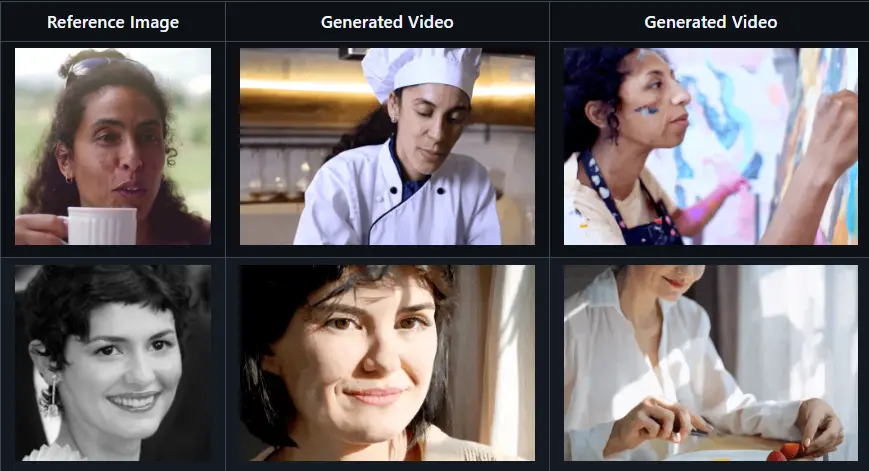
来自香港中文大学、腾讯人工智能实验室、北京大学的研究人员推出动态视频模型DynamiCrafter,它是一个利用视频扩散模型(Video Diffusion Models)来为静态图片添加动画效果的工具。
DynamiCrafter的核心思想是将图片融入到视频生成过程中,以此来创建动态内容,使得静态图片能够转化为具有自然动态的视频。
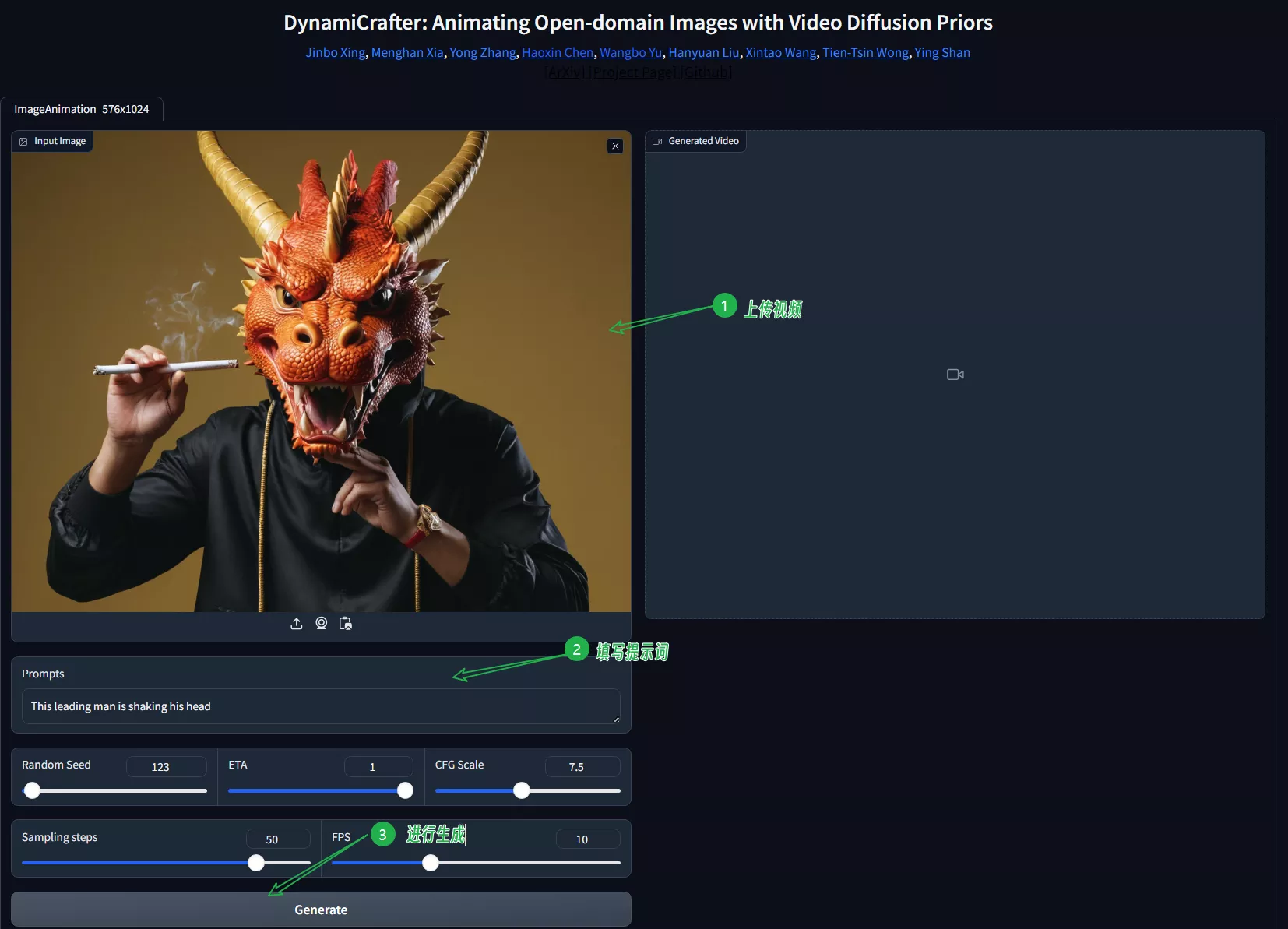
主要功能:
- 将静态图片转换为动态视频,同时保持图片原有的视觉内容。
- 通过文本提示来控制生成视频的动态效果,实现对动画内容的精确控制。
主要特点:
- 双流图像注入机制:DynamiCrafter结合了文本对齐的上下文表示和视觉细节引导,确保视频模型能够综合利用全局上下文和局部细节。
- 文本提示控制:用户可以通过文本提示来指导动画的动态内容,例如指定人物的动作或者场景的变化。
- 训练范式:DynamiCrafter采用了专门的训练策略,包括图像上下文表示网络的训练、适应T2V模型的调整,以及与视觉细节引导的联合微调。

工作原理:
- 图像上下文表示:首先,将输入图片通过一个查询变换器投影到文本对齐的丰富上下文表示空间,以便视频模型能够以兼容的方式消化图像内容。
- 视觉细节引导(VDG):为了增强视觉一致性,将完整的图像与每帧的初始噪声连接起来,作为形式指导输入到去噪U-Net中。
- 训练策略:通过三个阶段的训练,首先训练图像上下文表示网络,然后将其适应到T2V模型,最后与VDG联合微调,以增强视觉一致性。
具体应用场景:
- 故事视频生成:结合文本生成工具(如ChatGPT)和DynamiCrafter,可以生成基于故事脚本的动画视频。
- 循环视频生成:通过微调,DynamiCrafter可以生成循环播放的视频,适用于社交媒体和广告。
- 生成帧插值:DynamiCrafter还可以用于生成帧插值,即在两个不同帧之间生成过渡帧,用于视频编辑和视觉效果增强。
DynamiCrafter是一个创新的工具,它通过结合文本提示和图像信息,能够为静态图片创造出生动的动态视频,具有广泛的应用潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











