
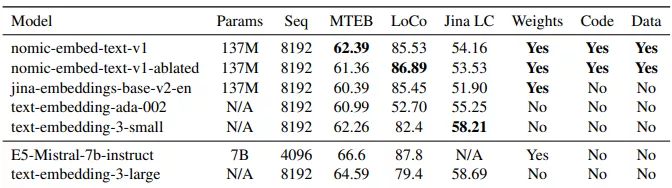
Nomic AI发布文本嵌入模型nomic-embed-text-v1,这是一个开源的、可复现的、拥有8192个上下文长度的英文文本嵌入模型。这个模型在处理短文本和长文本任务上的表现超过了OpenAI的Ada-002和text-embedding-3-small模型。
Nomic AI在论文中详细描述了训练数据,包括用于预训练的4.7亿对比数据对,以及用于监督微调的MSMarco、NQ、NLI、HotpotQA、FEVER等数据集。他们还公开了训练代码和模型权重,以便研究人员可以完全复制他们的结果。
主要功能:
nomic-embed-text-v1模型的主要功能是将句子或文档编码成低维向量,这些向量可以用于下游应用,如数据可视化、分类和信息检索。它特别擅长处理长文本,这在很多领域中非常有用,比如在处理整篇文章或报告时,传统的模型可能无法捕捉到整体的语义信息。
主要特点:
- 长上下文处理能力: 模型支持长达8192个token的上下文长度,这比大多数开源模型的512个token限制要长得多。
- 开源和可复现: 所有训练数据、代码和模型权重都是公开的,允许任何人完整地复现模型的训练过程。
- 性能优异: 在短文本和长文本任务的基准测试中,nomic-embed-text-v1都表现出色,超过了现有的一些顶尖模型。
工作原理:
nomic-embed-text-v1的训练过程分为几个阶段:
- 预训练: 使用大量未标记的数据(如BooksCorpus和Wikipedia)来训练一个长上下文的BERT模型。
- 无监督对比预训练: 使用公开可用的数据集生成文本对,并通过对比学习来训练模型区分相似和不相似的文档。
- 有监督对比微调: 在有标记的数据集上进行微调,以进一步提升模型在特定任务上的性能。
具体应用场景:
这个模型可以应用于多种自然语言处理(NLP)任务,包括但不限于:
- 信息检索: 在大量文本数据中快速找到与查询最相关的文档。
- 语义搜索: 提高搜索引擎的准确性,理解用户的查询意图并返回最相关的结果。
- 文档聚类: 将具有相似主题或内容的文档分组在一起,便于用户浏览和分析。
- 长文本理解: 在处理长篇文章、报告或书籍时,能够捕捉到整体的语义信息,而不是仅仅局限于单个句子或段落。
nomic-embed-text-v1是一个强大的工具,它通过其长上下文处理能力和开源特性,为研究人员和开发者提供了一个强大的基础,以构建和改进各种NLP应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











