
谷歌推出创新框架VLOGGER,它能够根据一段音频和一张人物的单张照片生成这个人说话和动作的逼真视频。想象一下,你只需提供一张你的照片和你的语音记录,VLOGGER就能制作出一个视频,在视频中你可以看到自己在说话、眨眼、做手势,甚至整个上半身的动作都与你的语音同步。
VLOGGER基于生成扩散模型,包括一种随机的人物到3D动作扩散模型,以及一种新的基于扩散的架构,将文本到图像模型与时间和空间控制相结合。据介绍,VLOGGER可以生成高质量、长度可变的视频,并通过人脸和身体的高级表达进行控制。

主要功能:
- 音频驱动的视频生成:VLOGGER可以根据提供的音频输入生成与之匹配的人类动作视频。
- 高质量视频输出:生成的视频具有高分辨率和良好的视觉效果,包括面部表情、头部运动、眨眼和手部动作。
- 身份保持和多样性:VLOGGER在生成视频时能够保持人物的身份特征,并且能够展现出丰富的表情和动作多样性。
主要特点:
- 不依赖于人脸检测和裁剪:与以往的方法不同,VLOGGER不需要对人物脸部进行检测和裁剪,它可以直接使用完整图像。
- 广泛的应用场景:适用于内容创作、娱乐、游戏等行业,也可以用于在线沟通、教育、个性化虚拟助手等领域。
工作原理:
VLOGGER的工作流程分为两个阶段。
- 第一阶段是一个基于随机扩散模型的网络,它根据输入的音频信号预测身体运动和面部表情。
- 第二阶段是一个时间扩散模型,它结合了文本到图像的模型,并增加了空间和时间的控制,从而生成与输入控制相匹配的视频帧。
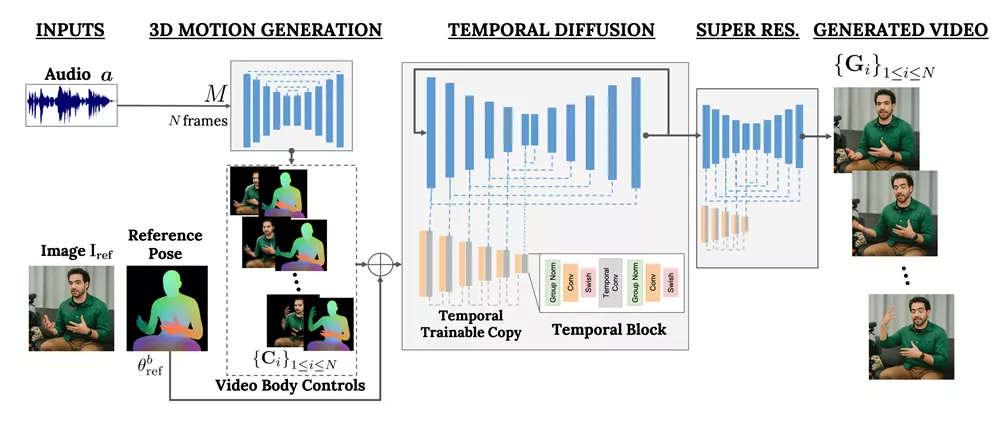
VLOGGER还利用了在预训练期间获得的生成性人类先验知识,以改善图像扩散模型的生成能力。
具体应用场景:
- 视频编辑和个性化:VLOGGER可以用于编辑视频,例如改变视频中人物的嘴型、眼睛状态或保持睁眼,同时保持时间上的连贯性。
- 虚拟助手和角色动画:在虚拟助手或游戏角色动画中,VLOGGER可以根据用户的语音指令生成逼真的角色动作和表情。
- 社交媒体内容创作:内容创作者可以使用VLOGGER来生成有趣的视频内容,而无需复杂的视频拍摄和编辑技术。
总的来说,VLOGGER是一个强大的工具,它将音频驱动的人类视频生成技术推向了一个新的高度,通过理解和模拟人类的复杂行为,为各种行业和应用提供了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











