Pusa 是基于 Mochi 微调的开源视频模型,不仅开源了整个微调过程,还以极低的训练成本(仅 100 美元)实现了多种视频生成任务的无缝支持。
Pusa专注于通过帧级噪声控制和矢量化时间步实现高效的视频扩散建模。这一方法首次在 FVDM(帧级视频扩散建模) 论文中提出,并在 Pusa 中得到了实际应用。凭借其优化的架构设计,Pusa 能够无缝支持多种视频生成任务,包括文本到视频、图像到视频、视频到视频等,同时保持出色的运动保真度和提示遵循性。

Pusa 的早期版本 Pusa-V0.5 基于 Mochi1-Preview ,是一个功能强大且灵活的预览版。团队希望通过开源的方式促进社区协作,进一步改进方法并扩展能力。
关键功能
全面的多任务支持
Pusa 模型在视频生成领域展现了强大的多功能性,支持以下任务:
- 文本到视频生成:根据文本描述生成对应的视频内容。
- 图像到视频转换:将静态图像转化为动态视频。
- 帧插值:在视频帧之间生成过渡帧,使视频更加流畅。
- 视频过渡:生成视频之间的自然过渡效果。
- 无缝循环:创建可以无缝循环播放的视频片段。
- 扩展视频生成:生成更长的视频内容。
- 更多功能:随着社区的不断探索,未来还将支持更多视频生成任务。
前所未有的效率
Pusa 的训练成本和硬件需求都非常低,具体如下:
- 训练成本:仅需 0.1k H800 GPU 小时,总成本为 0.1k 美元。
- 硬件需求:16 个 H800 GPU。
- 训练配置:批次大小 32,500 次训练迭代,学习率 1e-5。
- 优化潜力:通过单节点训练和高级并行技术,还可以进一步提升训练效率。Pusa 团队欢迎社区成员参与协作,共同探索更高效的训练方法。
完全开源发布
Pusa 的开源程度非常高,为开发者提供了全面的支持:
- 完整代码库:包括模型代码、训练代码和推理代码。
- 详细架构规格:清晰展示了模型的架构设计。
- 全面的训练方法:提供了详细的训练流程和参数设置,方便开发者复现和改进。
独特架构
新颖的扩散范式
Pusa 引入了帧级噪声控制和矢量化的时间步,这一创新最初在 FVDM 论文中提出。与传统方法相比,Pusa 的时间步数从传统的 1000 个增加到数千个,极大地提升了模型的灵活性和可扩展性。这种帧级噪声控制使得 Pusa 在视频生成过程中能够更精细地处理每一帧的内容,从而实现更高质量的视频生成效果。
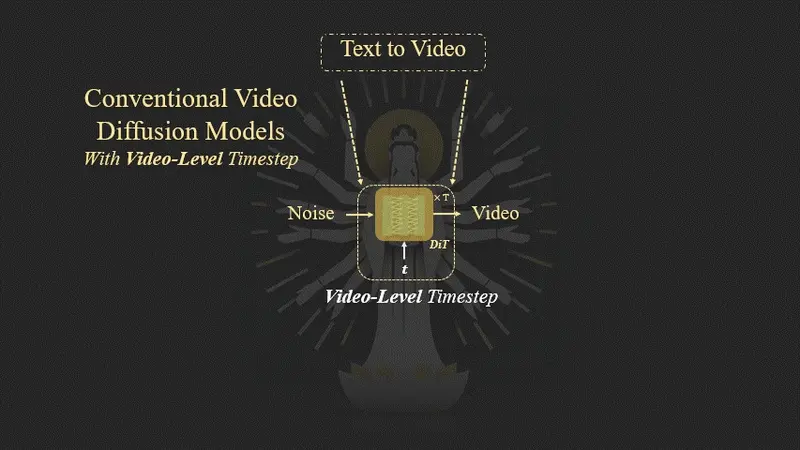
非破坏性修改
Pusa 对基础模型的适配保留了其原有的文本到视频生成能力。通过轻微微调,Pusa 便能够适应多种视频生成任务,而无需对基础模型进行大规模的修改。这种非破坏性修改不仅节省了开发时间和成本,还确保了模型的稳定性和可靠性。
通用适用性
Pusa 的方法不仅适用于 Mochi 模型,还可以轻松应用于其他领先的视频扩散模型,如 Hunyuan Video、Wan2.1 等。Pusa 团队热忱欢迎社区成员参与协作,共同探索这一方法在更多模型上的应用,推动视频生成技术的发展。
更新日志
v0.5(2025 年 3 月 28 日)
- 首次公开发布:向社区展示了 Pusa 模型的初步成果。
- 发布模型权重和基础推理代码:为开发者提供了模型的基础使用能力。
- 支持文本到视频和图像到视频生成:展示了模型在两种核心任务上的能力。
v0.5(2025 年 4 月 10 日)
- 发布训练代码和细节:进一步开源了训练过程,为开发者提供了完整的复现和改进基础。
- 支持 Pusa 和 Mochi 的多节点/单节点完整微调代码:提供了灵活的训练方式,满足不同开发者的需求。
- 发布训练数据集:提供了用于训练的数据集,方便社区成员进行实验和改进。
Pusa 模型以其低成本、高效率和强大的多任务支持能力,为视频生成领域带来了新的可能性。通过开源整个微调过程,Pusa 为社区提供了一个良好的合作平台,相信在社区的共同努力下,Pusa 将不断进化,为视频生成技术的发展注入新的活力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...