视频超分辨率(Video Super-Resolution, VSR)的目标是将低分辨率视频高质量地重建为高分辨率版本。近年来,扩散模型在图像和视频恢复任务中展现出强大能力,但其高延迟、高计算开销和对超高分辨率泛化能力弱的问题,限制了在实时场景中的应用。
- 项目主页:https://zhuang2002.github.io/FlashVSR
- GitHub:https://github.com/OpenImagingLab/FlashVSR
- 模型:https://huggingface.co/JunhaoZhuang/FlashVSR
为解决这些问题,清华大学、上海人工智能实验室、香港中文大学与上海交通大学联合提出 FlashVSR ——首个面向实时视频超分的流式单步扩散框架。它在单张 A100 GPU 上处理 768×1408 分辨率视频时可达到约 17 FPS,相比此前最快的单步扩散 VSR 模型提速近 12 倍,同时保持领先的感知质量。
三大关键技术支撑高效推理
FlashVSR 的高效性源于三项互补设计:
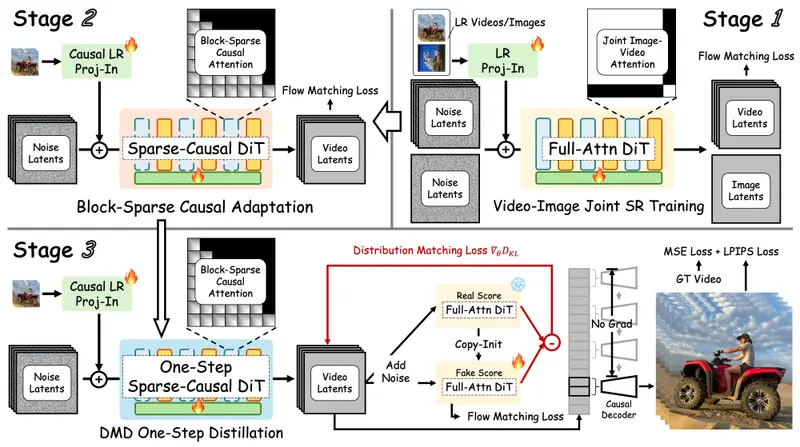
- 训练友好的三阶段蒸馏流程
从全注意力教师模型出发,逐步蒸馏为适用于流式推理的稀疏因果单步学生模型。该流程支持端到端训练,并有效弥合多步到单步、静态到流式的建模差距。 - 本地约束稀疏注意力机制
传统扩散模型在超高分辨率推理时,常因位置编码超出训练范围而出现纹理重复或模糊。FlashVSR 限制每个查询仅在局部空间窗口内进行注意力计算,既避免了位置混叠问题,又大幅减少冗余运算。在此基础上,进一步引入 top-k 稀疏策略,将计算聚焦于最相关区域。 - 轻量级条件解码器(TC Decoder)
与标准 VAE 解码器不同,TC Decoder 同时接收潜在表示和对应的低分辨率帧作为输入。利用 LR 信号作为先验,显著简化高分辨率重建过程,在保持视觉质量几乎无损的前提下,实现 7 倍解码加速。
专为超分训练构建的新数据集:VSR-120K
为支持大规模训练,团队还构建了 VSR-120K 数据集,包含:
- 约 120,000 个高动态视频片段(平均长度 >350 帧)
- 180,000 张高分辨率图像
所有样本均来自开放平台,经 LAION-Aesthetic 与 MUSIQ 质量评分筛选,并使用 RAFT 过滤掉运动不足的片段。最终保留的均为分辨率 ≥1080p、具有丰富时序变化的高质量内容,适用于联合图像与视频超分训练。
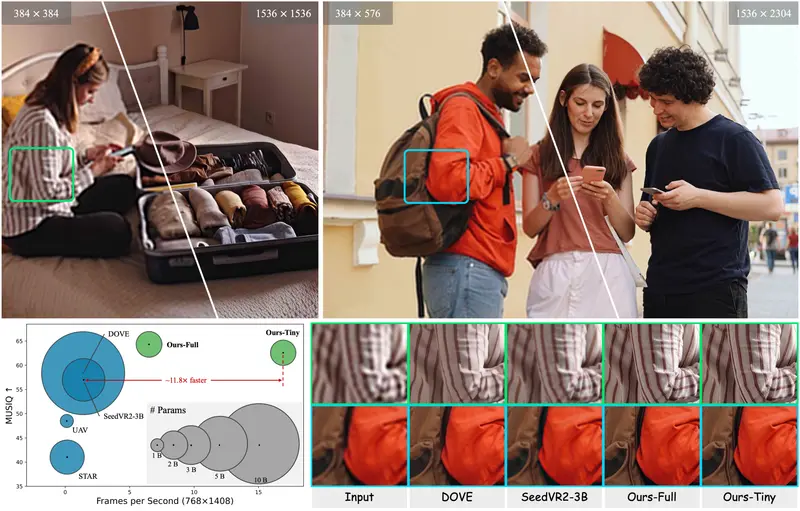
实测性能:快而准,可扩展至 1440p
在多个基准测试中,FlashVSR 表现出显著优势:
- 速度:768×1408 分辨率下达 17 FPS,比 SeedVR2-3B 快 12 倍,比多步模型 Upscale-A-Video 快 136 倍;
- 质量:在 PSNR、SSIM 和 LPIPS 等指标上均优于现有方法,尤其在视觉感知质量上提升明显;
- 可扩展性:框架可稳定扩展至 1440p 分辨率,输出细节丰富、无伪影。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











