美团LongCat团队推出 LongCat-Video,这是一个基础视频生成模型,拥有 13.6B 参数,在文本到视频、图像到视频以及视频续接生成任务中表现出色。它特别擅长高效且高质量的长视频生成,标志着我们迈向世界模型的第一步。
- 项目主页:https://meituan-longcat.github.io/LongCat-Video
- GitHub:https://github.com/meituan-longcat/LongCat-Video
- 模型:https://huggingface.co/meituan-longcat/LongCat-Video
例如,LongCat-Video 可以根据文本提示(如“一个滑板少年在街头滑行,带有运动模糊”)生成长达几分钟的连贯视频。它还可以从一张图片出发生成视频(Image-to-Video),或者继续生成已有视频的后续内容(Video-Continuation),支持交互式生成。

关键特性
- 🌟 多任务统一架构:LongCat-Video 在单一视频生成框架内统一了文本到视频、图像到视频以及视频续接任务。它使用单个模型原生支持所有这些任务,并在每个单独任务中持续提供出色性能。
- 🌟 长视频生成:LongCat-Video 在视频续接任务上原生预训练,使其能够生成数分钟长的视频,而不会出现颜色漂移或质量下降。
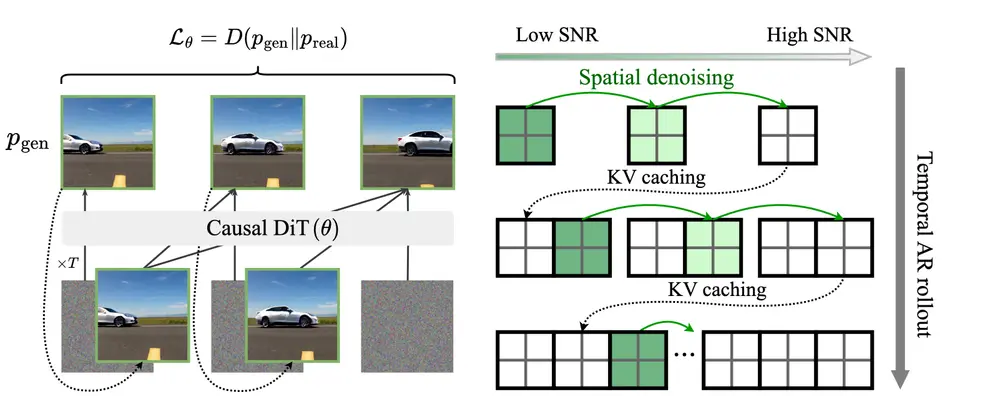
- 🌟 高效推理:LongCat-Video 通过在时间和空间轴上采用粗到精生成策略,在几分钟内生成 720p、30fps 视频。块稀疏注意力进一步提升了效率,尤其在高分辨率下。
- 🌟 多奖励 RLHF 的强大性能:通过多奖励组相对策略优化(GRPO)驱动,在内部和公共基准上的全面评估表明,LongCat-Video 的性能可与领先的开源视频生成模型以及最新的商业解决方案相媲美。
主要特点
- 高效长视频生成:解决了长视频生成中常见的累积误差问题,能够生成高质量、长时间的视频内容。
- 多任务支持:在一个模型框架内支持多种视频生成任务,减少了模型切换和训练成本。
- 高效推理:结合粗到细生成策略和块稀疏注意力机制,显著降低计算成本,使高分辨率视频生成变得可行。
- 开源性:代码和模型权重公开,便于社区进一步研究和应用。
工作原理
- 模型架构:基于 Diffusion Transformer (DiT) 框架,使用单流 Transformer 块,结合 AdaLN-Zero 调制和 RMSNorm 稳定训练。
- 多任务输入表示:通过条件帧和噪声帧的组合输入,模型能够根据输入模式识别不同的任务类型。
- GRPO 训练:通过多奖励优化,结合视觉质量、动作质量和文本对齐等多个奖励模型,提升生成视频的综合质量。
- 高效生成策略:
- 粗到细生成:先生成低分辨率视频,再通过高分辨率专家模块进行细化。
- 块稀疏注意力:通过稀疏化注意力机制,减少计算复杂度,提升生成效率。
测试结果
- 在 内部基准测试 中,LongCat-Video 在 Text-to-Video 和 Image-to-Video 任务上表现出色,尤其在视觉质量方面接近 SOTA 模型。
- 在 VBench 2.0 公共基准 中,LongCat-Video 在常识性(Commonsense)维度上表现最佳,表明其在动作合理性和物理规律性方面的优势。
- 效率提升:通过粗到细生成策略和块稀疏注意力,720p、30fps 视频生成速度提升超过 10 倍,可在几分钟内完成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...