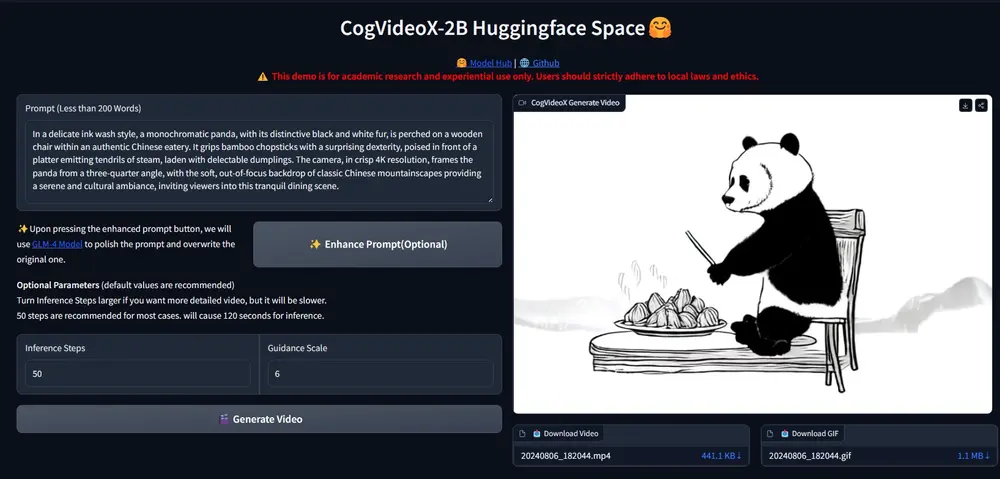
智谱 AI推出与“清影”同源的视频生成模型 —CogVideoX,CogVideoX模型包含多个不同尺寸大小的模型,目前将开源 CogVideoX-2B,它在 FP-16 精度下的推理需 18GB 显存,微调则需要 40GB 显存,这意味着单张 4090 显卡即可进行推理,而单张 A6000 显卡即可完成微调。CogVideoX-2B 的提示词上限为 226 个 token,视频长度为 6 秒,帧率为 8 帧 / 秒,视频分辨率为 720*480。目前CogVideo的一些局限性,比如输入序列长度的限制,以及未来的改进方向。
- 清影:https://chatglm.cn/video
- GitHub:https://github.com/THUDM/CogVideo
- 模型下载:https://huggingface.co/THUDM/CogVideoX-2b
- ComfyUI插件:https://github.com/kijai/ComfyUI-CogVideoXWrapper
主要功能
- 文本到视频生成:用户输入文本描述,模型生成与之匹配的视频内容。
主要特点
- 大规模参数:CogVideo拥有9.4亿参数,这使得它能够捕捉和学习复杂的数据模式。
- 多帧率层次化训练:模型采用多帧率层次化训练策略,以更好地对齐文本和视频片段。
- 开源:CogVideo是首个开源的大规模预训练文本到视频生成模型。
工作原理
- 继承预训练模型:CogVideo基于CogView2构建,继承了其从文本到图像的生成能力。
- 多帧率对齐:通过在训练中引入帧率描述,模型能够更好地理解文本和视频的时间对应关系。
- 序列生成与帧插值:模型首先生成关键帧,然后通过帧插值生成中间帧,使视频连贯。

具体应用场景
- 数字艺术创作:艺术家和设计师可以使用CogVideo快速将创意文本转化为视觉视频内容。
- 社交媒体:用户可以利用CogVideo生成个性化的视频内容,用于社交媒体分享。
- 教育和培训:在教育领域,CogVideo可以用来创建教学视频,帮助解释复杂的概念或过程。
- 娱乐和游戏:在游戏设计中,CogVideo可以根据玩家的操作或选择实时生成视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











