StabilityAI在今天推出一个新的视频生成模型Stable Video 4D(SV4D),只需 40 秒就可将单个视频转化为 8 个不同角度/视图的新视图视频(5 帧/个视角),整个 4D 优化大约需要 20 - 25 分钟,用户也可以指定摄像机角度。简单来说,SV4D能够从一个单一视角的视频,生成多视角且时间上连贯的动态3D对象视频。这就像是给视频中的物体赋予了“生命”,让它可以在虚拟世界中从不同角度被观察到,并且保持其动作的连贯性。例如,你用手机拍摄了一段小猫玩耍的视频。现在,使用SV4D技术,你可以生成从不同角度观看小猫玩耍的视频,就好像你围绕着小猫走动,从各个方向拍摄一样。而且,这些新生成的视频不仅视角不同,还能保持小猫动作的流畅和自然。
- 官方介绍:https://stability.ai/news/stable-video-4d
- 项目主页:https://sv4d.github.io
- 模型地址:https://huggingface.co/stabilityai/sv4d
请注意:对于个人或组织,如果年收入达到或超过 1,000,000 美元(或等值本地货币),不论收入来源为何,在商业使用 SV4D 或其任何衍生作品(如“微调”或“低秩适应”模型)之前,您必须直接从 Stability AI 获取企业商用许可证。您可以通过访问 https://stability.ai/enterprise 提交企业许可证申请。更多信息请参考 Stability AI 的社区许可协议,该协议可从 https://stability.ai/license 获取。
关键要点:
- Stable Video 4D 能够将单一物体的视频转换成八个不同角度的新视角视频。
- Stable Video 4D 仅需一次推理便能在大约 40 秒内生成八个视角中的五个帧。
- 用户可以指定摄像机角度,以满足特定创意需求来定制输出结果。
该模型目前仍处于研究阶段,在游戏开发、视频编辑和虚拟现实领域有未来的应用前景,并预期会有持续改进。我们很高兴地宣布 Stable Video 4D 的可用性,这是一项创新技术,让使用者能够上传单个视频并获得八个新视角的动态视频,带来了前所未有的多功能性和创造力。
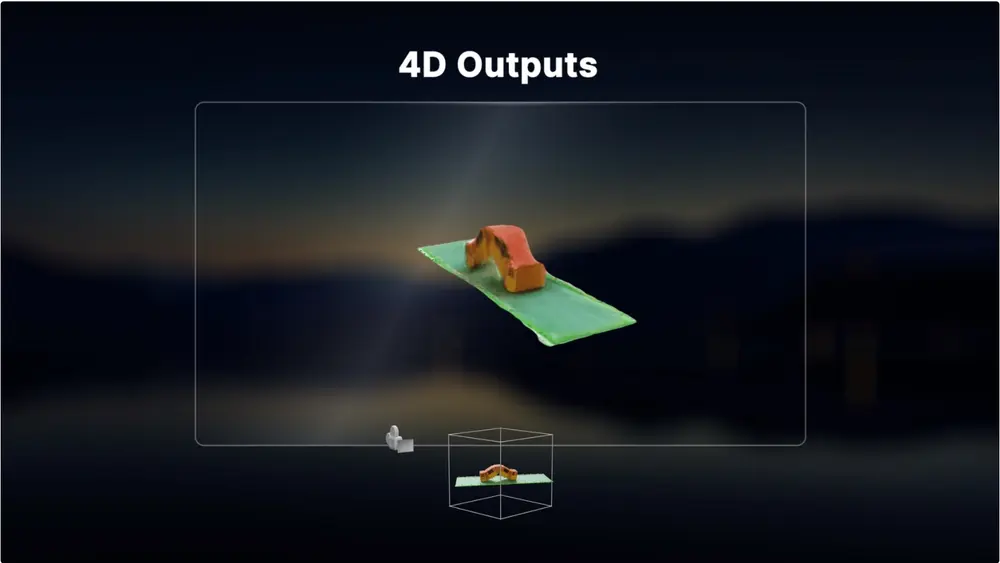
工作原理
用户开始时上传单一视频并指定所需的三维摄像机位置。Stable Video 4D 随后根据所指定的摄像机视角生成八个新视角的视频,为视频主体提供了全面的多角度观察。生成的视频可用于高效优化视频中主题的动态三维表示。
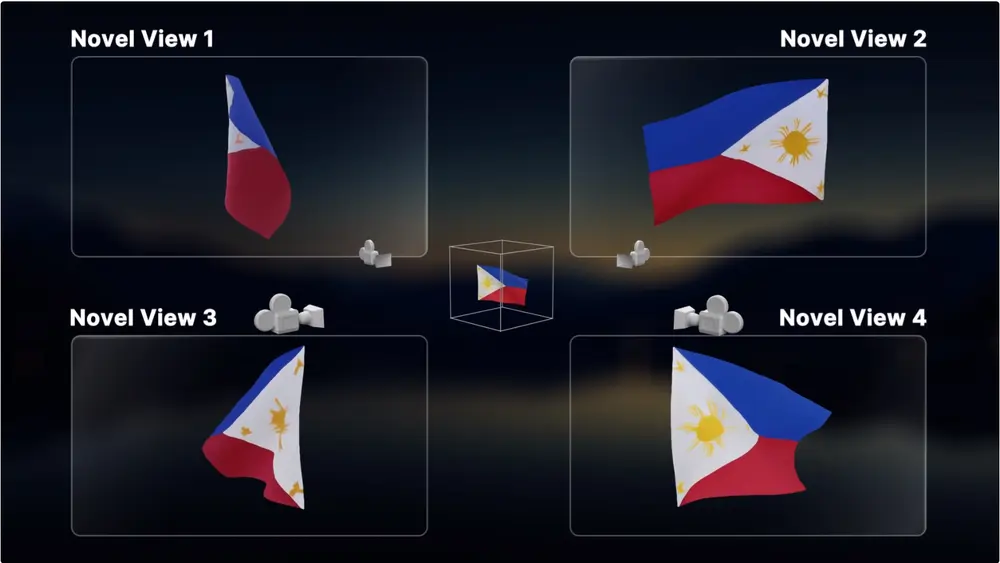
目前,Stable Video 4D 可以在约 40 秒内生成八个视角的五帧视频,整个 4D 优化过程大约需要 20 到 25 分钟。我们的团队设想未来在游戏开发、视频编辑和虚拟现实领域的应用。这些领域的专业人士将从多个视角可视化物体的能力中受益良多,从而增强产品的真实感和沉浸感。
最先进性能
与以往通常需要从图像扩散模型、视频扩散模型和多视角扩散模型组合中采样的方法不同,SV4D 能够同时生成多个新视角视频,极大地提高了空间轴和时间轴上的一致性。这种能力不仅确保了物体外观在多个视角和时间戳之间的一致性,而且实现了更轻量级的 4D 优化框架,不需要使用多个扩散模型的繁琐评分蒸馏采样 (SDS)。

Stable Video 4D 能够生成比现有工作更细致、更忠实于输入视频、并且在帧和视角间一致性更高的新视角视频。
研究与发展
Stable Video 4D 已在 Hugging Face 上开放,这是我们首个视频到视频生成模型,标志着 Stability AI 的一个重要里程碑。我们正在积极改进该模型,优化其处理更广泛的真实世界视频的能力,而不仅仅局限于目前训练所使用的合成数据集。Stability AI 团队致力于持续创新和探索这项技术及其他技术在现实世界中的应用场景。我们预计企业会采用我们的模型并进一步微调以适应其独特需求。这项技术在创建逼真的多角度视频方面潜力巨大,我们期待看到随着持续的研究和发展它将如何演变。
技术报告
与这一公告同步发布的还有一份详尽的技术报告,概述了模型开发过程中所采用的方法、面临的挑战及取得的突破。Stable Video 4D 代表了最先进的开源新视角视频生成技术。通过将单一视频输入转化为动态的多角度三维输出,我们为各个行业打开了新的创意和创新途径。

主要功能:
- 生成多视角、时间连贯的动态3D视频内容。
- 从单目视频创建4D(动态3D)表示。
主要特点:
- 统一的扩散模型:与以往分别训练视频生成和新视角合成的方法不同,SV4D设计了一个统一的模型来同时处理这两个任务。
- 多帧和多视角一致性:生成的视频在不同视角和时间帧上都能保持一致性。
- 高效的4D表示优化:无需使用复杂的基于SDS(Score-Distillation Sampling)的优化过程,就能高效地优化出隐式的4D表示。
工作原理:
- 输入处理:SV4D接受一个单目参考视频,并根据用户指定的相机轨迹来生成视频。
- 扩散模型:基于Stable Video Diffusion(SVD)和SV3D模型,SV4D通过添加视图注意力和帧注意力模块来增强模型的能力。
- 生成过程:模型首先生成视频的第一帧的多视角图像,然后联合输出剩余的图像网格,确保在视图和运动轴上的一致性。
- 4D优化:使用生成的新视角视频来优化动态3D对象的隐式4D表示,这个过程不需要SDS损失函数。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











