
加州大学圣巴巴拉分校、加州大学洛杉矶分校、亚马逊 AGI和滑铁卢大学的研究人员推出新型视频生成模型T2V-Turbo-v2,它旨在提升基于扩散的文本到视频(T2V)生成的质量和效率。简单来说,这项技术可以根据用户提供的文本描述生成高质量的视频,比如“一个小狗在公园里玩耍”。
- 项目主页:https://t2v-turbo-v2.github.io
- GitHub:https://github.com/Ji4chenLi/t2v-turbo
- 模型:https://huggingface.co/collections/jiachenli-ucsb/t2v-turbo-v2-67063359f83fded3443e371e
- Demo:https://huggingface.co/spaces/TIGER-Lab/T2V-Turbo-V2
T2V-Turbo-v2 通过将各种监督信号(包括高质量训练数据、奖励模型反馈和条件指导)整合到一致性蒸馏过程中,引入了显著的进步。通过全面的消融研究,研究团队强调了针对特定学习目标定制数据集的关键重要性,以及从多样化的奖励模型中学习以提高视觉质量和文本视频对齐的有效性。此外,研究团队强调了条件指导策略的巨大设计空间,其核心是设计一个有效的能量函数来增强教师 ODE 求解器。研究团队通过从训练数据集中提取运动指导并将其纳入 ODE 求解器中,展示了这种方法的潜力,展示了其在提高生成视频的运动质量方面的有效性,这些视频的运动相关指标从 VBench 和 T2V-CompBench 中得到了改进。从经验上看, T2V-Turbo-v2 在 VBench 上建立了新的最先进结果,总分为 85.13,超过了 Gen-3 和 Kling 等专有系统。
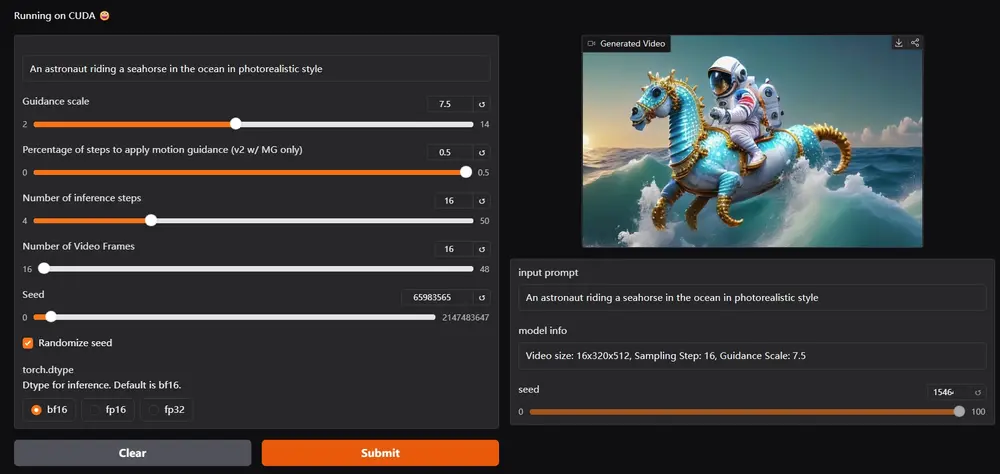
主要功能:
- 文本到视频生成:用户可以输入描述,模型会生成与描述相符的视频。
- 多种监督信号整合:通过结合高质量训练数据、奖励模型反馈和条件引导,提升生成视频的视觉质量和文本对齐度。
- 运动引导:在生成视频时,模型能够提取运动信息,使得视频中的动作更加自然流畅。

主要特点:
- 后训练增强:T2V-Turbo-v2在模型训练完成后,通过引入额外的数据和反馈进行优化,提升生成效果。
- 高质量生成:与传统方法相比,生成的视频在视觉效果和语义一致性上都有显著提升。
- 灵活性强:该模型可以适应不同类型的输入和生成需求,支持多种视频生成场景。
工作原理:
T2V-Turbo-v2的工作原理包括几个关键步骤:
- 数据收集与处理:模型使用高质量的视频数据集进行训练,同时结合奖励模型来优化生成效果。
- 分阶段采样:在生成过程中,模型将采样过程分为两个阶段,首先进行多对象感知采样,然后在去噪图像空间中融合不同概念的外观。
- 运动引导整合:通过提取运动信息,模型能够在生成视频时保持动作的连贯性和自然性。
具体应用场景:
- 内容创作:艺术家和内容创作者可以使用该技术快速生成符合特定主题的视频,提升创作效率。
- 广告与营销:企业可以利用T2V-Turbo-v2生成个性化的广告视频,以吸引目标客户。
- 教育与培训:在教育场景中,可以生成教学视频,帮助学生更好地理解复杂概念。
- 社交媒体:用户可以通过简单的文本描述生成有趣的视频内容,分享给朋友和家人。
总之,T2V-Turbo-v2通过创新的技术手段,提升了视频生成的质量和效率,为多个领域的应用提供了强有力的支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











