阿里巴巴集团通义实验室于 2025 年 2 月 25 日正式开源了其最新一代视频生成模型Wan2.1。该模型能够根据文本、图像或其他控制信号生成高质量的视频内容,适用于创意设计、影视制作和教育领域等多种应用场景。ComfyUI 在今天宣布已原生支持 Wan2.1,用户可以直接使用官方提供的工作流在 ComfyUI 上生成视频。(相关:阿里巴巴通义实验室开源视频生成模型 Wan2.)
Wan2.1 系列模型
Wan2.1 系列包括多个模型,每个模型都有其独特的优势和应用场景:
- Wan2.1-I2V-14B:在文本和图像生成视频方面实现了 SOTA 性能,能够生成展示复杂视觉场景和运动模式的视频。
- Wan2.1-T2V-14B:在开源和闭源模型中都创造了新的 SOTA 性能,展示了其生成具有强大运动动态的高质量视觉效果的能力。
- Wan2.1-T2V-1.3B:支持在几乎所有消费级 GPU 上进行视频生成,仅需 8.19 GB 显存即可生成 5 秒的 480P 视频。
Wan2.1 的亮点
- 支持消费级 GPU:T2V-1.3B 模型仅需要 8.19 GB 显存,使其与几乎所有消费级 GPU 兼容。例如,在 RTX 4090 上,大约 4 分钟内即可生成 5 秒的 480P 视频(不进行量化)。
- 多任务能力:Wan2.1 在文本到视频、图像到视频、视频编辑、文本到图像和视频到音频等多种任务上表现出色,推动了视频生成领域的发展。
- 可视化文本生成:Wan2.1 是第一个能够生成中文和英文文本的视频模型,支持多语言内容创作。
- 强大的视频 VAE:Wan-VAE 提供出色的效率和性能,能够编码和解码任意长度的 1080P 视频,同时保留时间信息,使其成为视频和图像生成的理想基础。
在 ComfyUI 中使用 Wan2.1
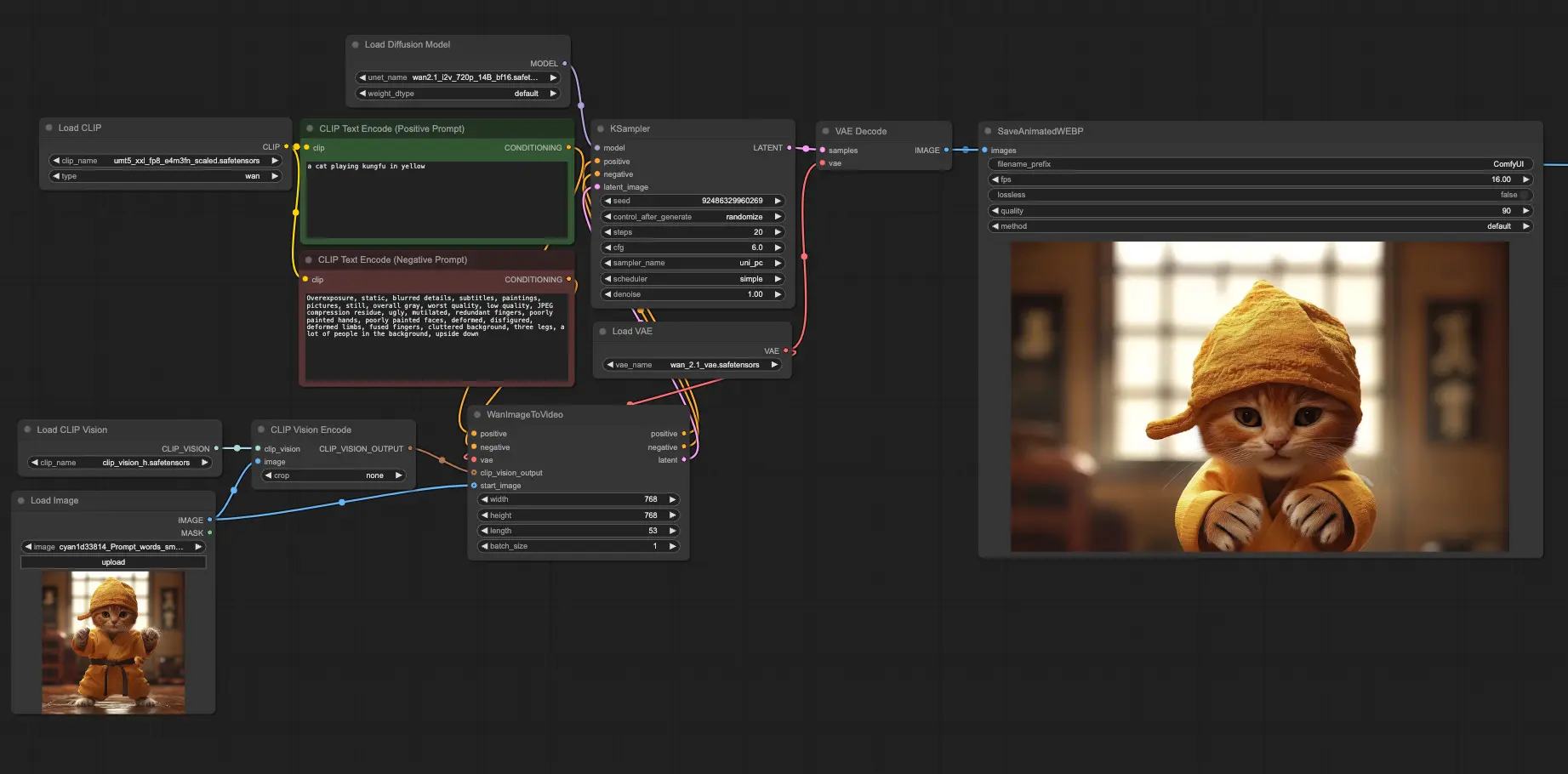
ComfyUI 已原生支持 Wan2.1,用户可以直接使用官方提供的工作流生成视频。
1、更新 ComfyUI
- 将 ComfyUI 更新到最新版本。
2、下载相关文件
下载以下 4 个文件,并将它们放置在指定目录中:
- 扩散模型:选择一个扩散模型,放置在
ComfyUI/models/diffusion_models中 - umt5_xxl_fp8_e4m3fn_scaled.safetensors:放置在
ComfyUI/models/text_encoders中 - clip_vision_h.safetensors:放置在
ComfyUI/models/clip_vision中 - wan_2.1_vae.safetensors:放置在
ComfyUI/models/vae中
3、使用示例工作流
- 使用 ComfyUI 提供的示例工作流或参考示例视频进行操作
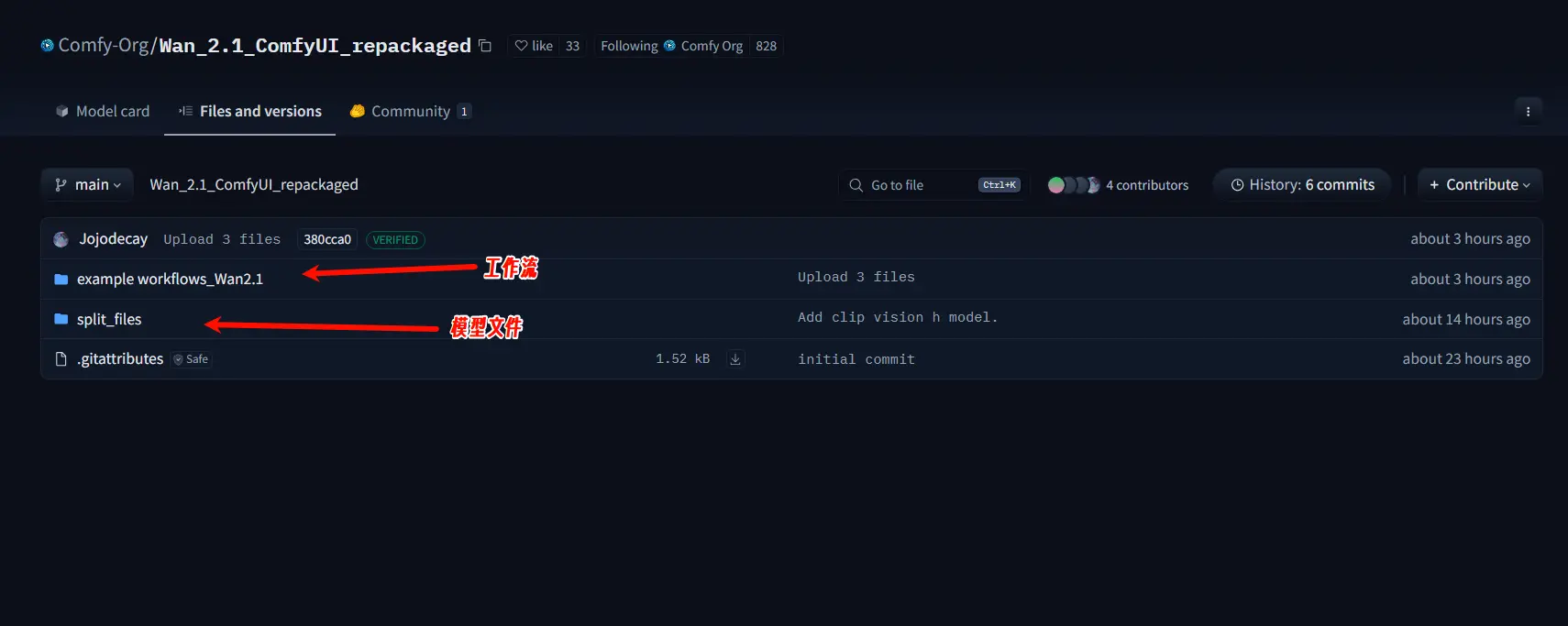
- 模型:Hugging Face|魔塔 (国内用户请从魔塔下载)
- 工作流:https://comfyanonymous.github.io/ComfyUI_examples/wan
注意事项
显存要求
- 使用 umt5_xxl_fp8_e4m3fn_scaled.safetensors 运行 480p/720p 图像到视频模型时,需要约 40GB 显存。
- 1.3B 文本到视频模型 需要约 15GB 显存。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











