
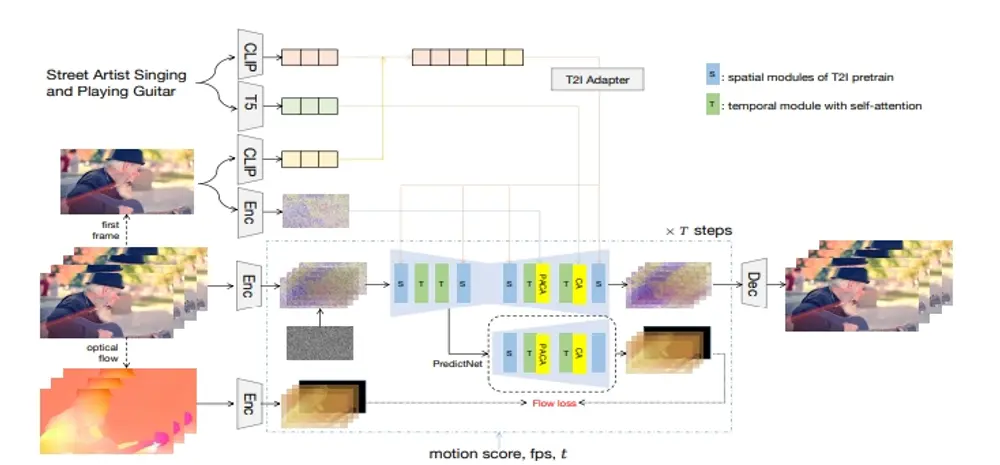
字节跳动和香港理工大学的研究人员推出新型视频生成模型Factorized-Dreamer,它专门用于将文本转换成高质量的视频(Text-to-Video, T2V)。Factorized-Dreamer是一种包含几个关键设计的时空分解框架,用于 T2V 生成,包括用于结合文本和图像嵌入的适配器、用于捕捉像素级图像信息的像素感知交叉注意力模块、用于更好地理解动作描述的 T5 文本编码器,以及用于监督光流的 PredictNet。此外,研究团队还提出了一种噪声调度方案,这对确保视频生成的质量和稳定性起着关键作用。Factorized-Dreamer降低了对详细标题和高质量视频的要求,并可以直接在有限的低质量数据集上进行训练,这些数据集可能包含嘈杂和简短的标题,如 WebVid-10M,从而大大减轻了收集大规模高质量视频-文本对的成本。

主要功能:
- 文本到视频的转换:用户可以输入一段描述性的文本,Factorized-Dreamer能够根据这段文本生成视频内容。
- 视频质量提升:即使在训练数据有限且质量不高的情况下,也能生成高质量的视频。
主要特点:
- 双步骤生成过程:首先生成与文本描述相关的图片,然后基于这张图片和文本的动态细节描述合成视频。
- 简化训练流程:Factorized-Dreamer不需要重新标注或微调,可以直接在有限的低质量数据集上训练。
- 创新的设计:包括适配器结合文本和图像嵌入、像素级交叉注意力模块、T5文本编码器以及用于监督光流的PredictNet。
工作原理:
- 文本到图像的适配:使用预训练的文本到图像(T2I)模型生成与文本描述相匹配的第一帧图像。
- 像素级信息捕捉:通过像素感知交叉注意力(PACA)模块来理解图像中的像素级细节。
- 文本编码:使用T5模型作为文本编码器,更好地理解文本中的动态描述。
- 光流监督:通过PredictNet来监督光流,增强生成视频的运动连贯性。
- 噪声调度:调整噪声调度策略,确保视频生成的质量和稳定性。
具体应用场景:
- 社交媒体内容创作:用户可以输入描述性文本,自动生成视频内容,用于社交媒体分享。
- 电影和视频制作:在剧本创作阶段,快速生成视频草图,辅助导演和制作团队预览场景。
- 教育和培训:根据教学文本自动生成教学视频,提高学习材料的丰富性和互动性。
- 虚拟现实:生成虚拟现实环境中的视频内容,提供更加真实和沉浸式的体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











