
来自南京大学、复旦大学和阿里巴巴的研究团队推出一种用于创建人物图像动画的新方法Champ,该方法利用潜在扩散框架内的3D人体参数模型来强化当前人体生成技术中的形状对齐和运动引导。例如,你有一张静态的照片,而Champ技术可以让你照片中的人物动起来,就像在视频中一样。
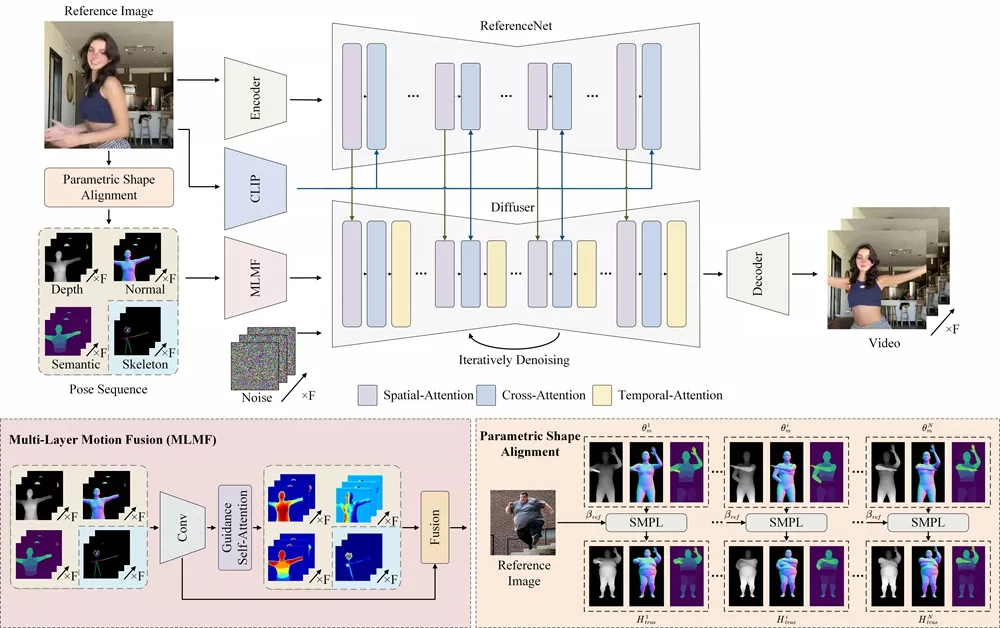
该方法以SMPL模型作为3D人体参数模型,构建了一个统一的体型和姿态表示,从而能够精准地从源视频中捕获人体复杂的几何结构和运动特征。具体而言,此方法结合了从SMPL序列中获取的渲染深度图像、法线图和语义图,以及基于骨骼的运动引导,为潜在扩散模型提供了丰富的3D形状和详细的姿态属性。同时,Champ采用了一个集成了自注意力机制的多层运动融合模块,用于在空间域中融合形状和运动的潜在表示。通过将3D人体参数模型作为运动引导,能够在参考图像和源视频运动之间实现精确的人体形状对齐。

在基准数据集上的实验评估表明,该方法论具有出色的能力,能够生成高质量的人体动画,准确捕捉姿态和形状的变化。此外,我们的方法在野生数据集上也展现出卓越的泛化能力。我们将公开我们的代码和模型,以供进一步研究和应用。
主要功能:
Champ技术的主要功能是将静态的人类图像转换成动态的视频动画。它能够捕捉人物的复杂动作和姿势变化,并将这些动作应用到源视频中,使得照片中的人物能够执行一系列连贯的动作。
主要特点:
- 3D参数模型的使用: Champ使用了一种名为SMPL的3D人体参数模型,这种模型能够精确地捕捉人体的形状和姿势。
- 动态对齐和运动引导: 通过使用深度图像、法线图和语义图等,Champ能够更好地对齐人物形状,并引导动画中的动作。
- 多层次运动融合: Champ采用了一个多层运动融合模块,通过自注意力机制将形状和运动的潜在表示在空间域中融合,以生成更自然的动作。
工作原理:
Champ的工作原理可以分为几个步骤:
- 形状和姿势的统一表示: 首先,它使用SMPL模型来表示照片中人物的形状和姿势。
- 从SMPL模型生成视觉信息: 然后,它从SMPL模型渲染出深度图像、法线图和语义图,这些图像包含了人物的3D结构和表面细节。
- 运动引导: 接着,Champ将这些视觉信息与基于骨架的运动引导结合起来,以增强对细节动作(如面部表情和手指动作)的表示。
- 特征融合和动画生成: 最后,通过自注意力机制和多层运动融合模块,Champ将这些信息融合到一起,并在一个潜在扩散模型中生成动画。
具体应用场景:
- 虚拟现实体验: Champ可以用来创建虚拟现实中的角色动画,让用户体验与虚拟人物的互动。
- 数字内容创作: 在电影、游戏和广告中,Champ可以用来生成高质量的人物动画,提高内容的吸引力。
- 交互式故事讲述: 通过Champ,可以创建能够根据用户输入做出反应的动画角色,增强故事的互动性。
Champ是一种先进的人物图像动画技术,它通过结合3D模型和深度学习,能够生成逼真且连贯的动画效果,为数字娱乐和内容创作领域带来了新的可能性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










