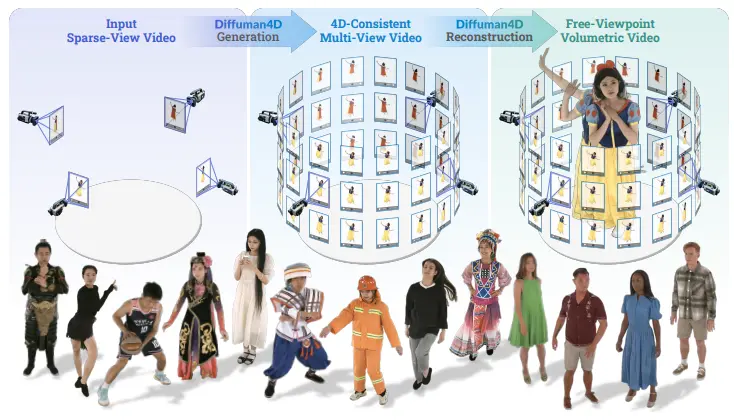
浙江大学和蚂蚁研究的研究人员推出新型扩散模型 Diffuman4D ,从稀疏视角视频中生成高质量、4D 一致的人体自由视角视频。该模型通过引入滑动迭代去噪过程和基于人体骨骼的姿态条件机制,显著提升了生成视频的空间和时间一致性,同时保持了高效的推理能力。
例如,给定一个包含少量视角(如 4 个视角)的视频输入,Diffuman4D 能够生成高分辨率(1024p)的多视角视频,这些视频在空间和时间上保持高度一致。生成的视频可以用于实时渲染,为用户提供沉浸式的观看体验。
主要功能
Diffuman4D 的主要功能包括:
- 稀疏视角视频输入:从少量视角的视频中生成高质量的多视角视频。
- 4D 一致性:生成的视频在空间和时间上保持高度一致性,适用于动态场景。
- 高分辨率输出:支持高达 1024p 的视频分辨率,适用于高保真渲染。
- 实时渲染:通过优化的 4D 高斯点云(4DGS)重建,支持实时自由视角渲染。
主要特点
- 滑动迭代去噪机制:通过滑动窗口在空间和时间维度上交替去噪,确保生成视频的 4D 一致性。
- 人体骨骼姿态条件:引入 3D 人体骨骼序列作为结构先验,增强生成视频的姿态准确性和视觉质量。
- 高效的推理能力:通过并行化处理和优化的去噪策略,保持高效的推理速度。
- 高质量数据集:对 DNA-Rendering 数据集进行了详细的预处理,包括相机参数校准、颜色校正矩阵优化、前景掩码预测和人体骨骼估计。
工作原理
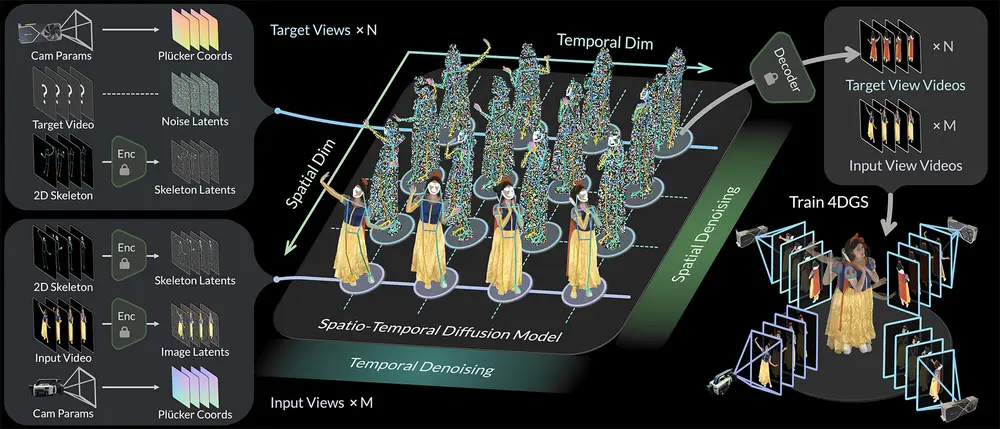
Diffuman4D 的工作原理基于以下几个关键步骤:
- 输入编码:将稀疏视角视频编码为潜在空间表示,同时生成目标视角的噪声潜在表示,形成 4D 潜在网格。
- 滑动迭代去噪:通过滑动窗口在空间和时间维度上交替去噪,每个目标样本在去噪过程中会感知到周围的空间和时间信息,从而增强生成视频的 4D 一致性。
- 姿态条件机制:将 3D 人体骨骼序列投影到每个视角和时间戳上,作为条件信号输入扩散模型,增强生成视频的姿态准确性和视觉质量。
- 视频解码:从去噪后的潜在表示中解码出目标视角的视频。
- 4D 高斯点云重建:使用优化的 4D 高斯点云(4DGS)模型重建高质量的人体表演,支持实时自由视角渲染。
测试结果
Diffuman4D 在多个关键指标上表现出色:
- 定量评估:在 DNA-Rendering 和 ActorsHQ 数据集上,Diffuman4D 在 PSNR、SSIM 和 LPIPS 等指标上显著优于现有方法。
- 定性评估:通过视觉结果展示,Diffuman4D 在稀疏视角输入下能够生成高质量、4D 一致的多视角视频,即使在复杂的动态场景中也能保持自然的外观和运动。
- 用户研究:用户研究结果表明,Diffuman4D 在视觉质量和时间一致性方面优于现有方法。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











