
由阿里巴巴与北京邮电大学联合提出,FantasyPortrait 是一个基于扩散变换器(Diffusion Transformer)的创新框架,用于从静态图像生成高保真、富有表现力的单角色与多角色面部动画。该方法在跨身份重演(cross-identity reenactment)和多角色控制方面展现出卓越性能,解决了当前方法中常见的伪影、表情干扰与动作失真问题。
- 项目主页:https://fantasy-amap.github.io/fantasy-portrait
- GitHub:https://github.com/Fantasy-AMAP/fantasy-portrait

项目亮点
- ✅ 高质量多角色动画生成:支持多个角色同步动画,表情独立且协调
- ✅ 跨身份重演能力强:即使在面部结构差异大的角色间也能保持自然动作
- ✅ 表情增强学习策略:通过隐式表示捕捉与身份无关的面部动态
- ✅ 掩码交叉注意力机制:防止角色间表情干扰,提升多角色控制精度
- ✅ 音频驱动扩展支持:仅需少量样本即可实现音视同步,支持多语言与方言
模型概述
从静态图像生成富有表现力的面部动画是一项极具挑战的任务。传统方法依赖显式的几何先验(如面部关键点或3DMM),在跨身份重演和多角色场景中常出现伪影,且难以捕捉细腻的情感变化。
为此,研究人员提出了 FantasyPortrait,一个基于扩散变换器的新框架,能够生成:
- 高保真度
- 情感丰富
- 多角色协调
的面部动画,适用于肖像视频生成、虚拟角色驱动、语音驱动等场景。
✅ 主要功能
- 单角色肖像动画生成
从静态图像出发,生成具有自然表情变化和头部运动的高质量面部视频。 - 多角色肖像动画生成
支持多个角色同时动画化,每个角色表情独立控制,避免相互干扰。 - 跨身份重演(Cross-Identity Reenactment)
可将一个角色的驱动动作迁移到另一个角色上,即便两者面部结构差异显著。
⚙️ 技术创新
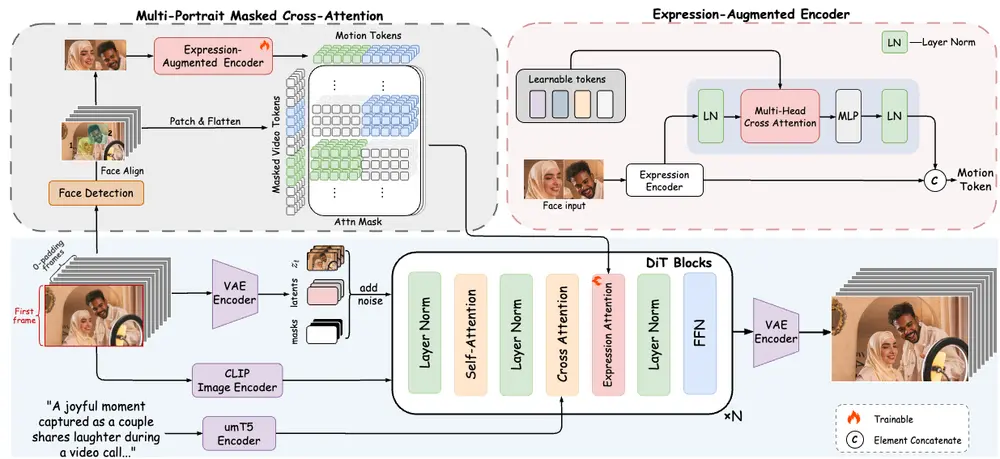
1. 表情增强的隐式控制策略
FantasyPortrait 采用隐式面部表情表示,从驱动视频中提取与身份无关的动态特征,包括:
- 嘴唇运动
- 眼部变化(注视、眨眼)
- 头部姿态
- 情感表达
通过表情增强编码器(Expression-Augmented Encoder)对这些特征进行细粒度建模,显著提升情感表达的丰富性。
2. 掩码交叉注意力机制(Masked Cross-Attention)
在多角色场景中,不同角色的表情特征容易相互干扰。FantasyPortrait 引入了掩码交叉注意力机制,对角色嵌入进行加权控制,确保:
- 每个角色的表情独立生成
- 动作保持协调一致
- 避免表情泄露与动作失真
3. 扩展支持音频驱动动画
FantasyPortrait 可轻松扩展为音频驱动的肖像动画框架:
- 使用 Whisper 提取音频特征
- 通过小型变换器网络映射到潜在驱动表示
- 仅需数百个样本即可微调支持新语言(如中文、日语、阿拉伯语)
这一特性显著降低了训练成本与语言适配门槛,提升了技术的包容性。
📦 数据集与评估
为推动该领域研究,团队还贡献了两个重要资源:
📚 Multi-Expr 数据集
- 专为多角色肖像动画设计
- 包含多人视频与单人视频数据
- 支持多种表情与动作组合
📊 ExprBench 基准测试
- 包含多个评估指标:
- LMD(Lip Movement Distance)
- MAE(Mean Angular Error)
- AED(Action Emotion Distance)
- APD(Appearance Preservation Distance)
FantasyPortrait 在 ExprBench 上的测试结果表明:
- 在表情与动作相似性方面优于现有方法
- 在跨身份重演任务中表现尤为突出
- 多角色动画中保持高一致性与自然性
📊 定量与定性评估结果
| 模型 | LMD ↓ | MAE ↓ | AED ↓ | APD ↓ | 用户评分 ↑ |
|---|---|---|---|---|---|
| 基线方法 A | 2.14 | 0.87 | 1.22 | 0.95 | 3.6 |
| 基线方法 B | 1.98 | 0.81 | 1.15 | 0.90 | 3.8 |
| FantasyPortrait | 1.65 | 0.63 | 0.92 | 0.78 | 4.7 |
在多个关键指标与用户研究中,FantasyPortrait 均取得最优表现,尤其在复杂背景与多角色干扰下保持了自然流畅的动画输出。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











