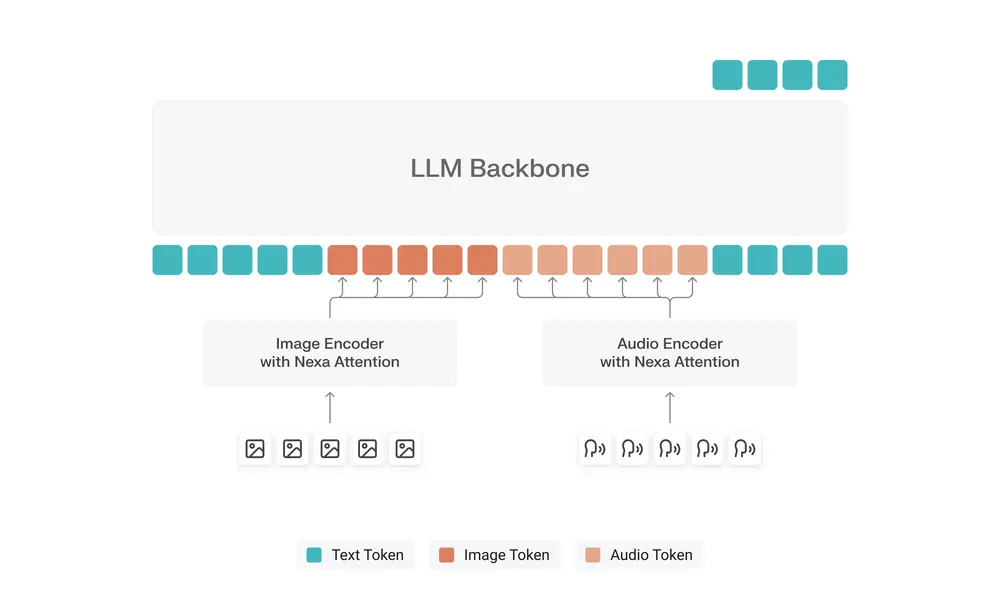
百度千帆团队推出 Qianfan-OCR,这是一款参数量仅为 4B 的端到端文档智能大模型。不同于传统“检测 + 识别 + 理解”的多阶段流水线,Qianfan-OCR 在单一的视觉 - 语言架构内,实现了从图像直接到 Markdown的转换,并支持提示驱动的各种复杂任务。
- GitHub:https://github.com/baidubce/Qianfan-VL
- 模型:https://huggingface.co/baidu/Qianfan-OCR
- Demo:https://huggingface.co/spaces/baidu/Qianfan-OCR-Demo
- Skill:https://github.com/baidubce/skills/tree/develop/skills/qianfanocr-document-intelligence
在权威基准测试中,Qianfan-OCR 展现了惊人的性能:OmniDocBench v1.5 综合得分 93.12,超越 DeepSeek-OCR-v2、Gemini-3 Pro 及所有其他端到端模型,位居全球第一。同时,其在关键信息提取(KIE)任务上也以平均分 87.9 的成绩领跑,甚至击败了参数量高达 235B 的 Qwen3-VL。
核心亮点:小参数,大能量
- 🏆 全能冠军:
- OmniDocBench v1.5:综合得分 93.12(第一名),在文本编辑距离、公式识别、表格还原及阅读顺序上全面领先。
- OlmOCR Bench:得分 79.8(端到端模型第一名)。
- 关键信息提取 (KIE):在五个公开基准测试中平均得分 87.9,超越 Gemini-3.1-Pro、Seed-2.0 等巨型模型。
- 🧠 创新架构:“布局即思考” (Layout-as-Thinking)
模型引入可选的⟨think⟩令牌触发机制。在生成最终输出前,模型会先生成结构化的版面表示。- 功能性:在端到端范式中恢复了显式的版面分析能力,用户可直接获取结构化数据。
- 增强性:针对复杂布局、元素杂乱或非标准阅读顺序的文档,显著提升识别准确率。
- 🌍 多语言与高效部署:
- 支持 192 种语言,覆盖全球主要文字体系。
- 在单张 A100 GPU 上使用 W8A8 量化后,页面处理速度高达 1.024 PPS(Pages Per Second),延迟极低。
技术架构:精简而强大
Qianfan-OCR 基于 Qianfan-VL 多模态桥接架构构建,仅用 4B 参数实现了越级打击:
| 组件 | 配置详情 |
|---|---|
| 视觉编码器 | Qianfan-ViT (24 层 Transformer),支持 AnyResolution (最高 4K),每张图最多 4096 个视觉令牌 |
| 语言模型 | Qwen3-4B (36 层,隐藏维度 2560,GQA,32K 上下文) |
| 跨模态适配器 | 2 层 MLP (GELU 激活),将 1024 维视觉特征映射至 2560 维语言空间 |
基准测试详解
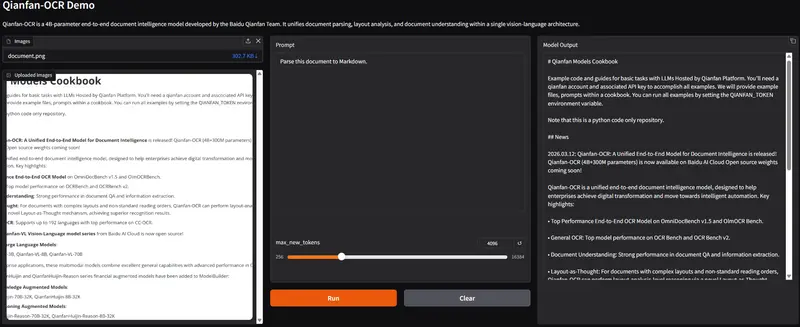
1. 文档解析 (OmniDocBench v1.5)
Qianfan-OCR 以 93.12 的综合分夺冠,尤其在公式识别 (CDM 92.43) 和表格结构还原 (TEDss 93.85) 上表现优异,远超同量级的 DeepSeek-OCR-v2 和 Gemini-3 Pro。
注:虽然传统的 PaddleOCR-VL 1.5 流水线方案在部分指标略高,但 Qianfan-OCR 作为端到端模型,在架构简洁性和泛化能力上具有代际优势。
2. 文档理解与图表推理
在需要深度理解的 CharXiv (科学图表问答) 和 ChartQA 系列测试中,Qianfan-OCR 大幅领先 Qwen3-VL-4B/2B。
- CharXiv_DQ: 94.0 (vs Qwen3-VL-4B 的 81.8)
- ChartQAPro: 42.9 (vs Qwen3-VL-4B 的 36.2)
- 数据证明:传统两阶段系统在图表推理上得分为 0,因为结构信息在提取阶段已丢失,而 Qianfan-OCR 保留了完整的语义结构。
3. 关键信息提取 (KIE)
在发票、收据、证件等场景的提取任务中,Qianfan-OCR 综合得分 87.9,不仅超越了参数量大数十倍的 Qwen3-VL-235B,也在中文 KIE 任务上取得了 82.3 的高分。
应用场景与生态集成
Qianfan-OCR 通过提示词即可灵活切换任务模式,覆盖:
- 文档解析:图像/PDF 转 Markdown,保留完整格式。
- 表格与公式:复杂表格转 HTML/Excel,数学公式转 LaTeX。
- 图表理解:自动分析趋势、提取数据并回答相关问题。
- 多语言 OCR:支持 192 种语言的场景文本及手写体识别。
OpenClaw 技能集成:
百度已发布 Qianfan OCR 文档智能 技能包,兼容 OpenClaw、Claude Code、Codex 等主流 Agent 框架。开发者可一键调用该技能,实现文档自动解析、版面分析、信息提取等工作流的自动化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











