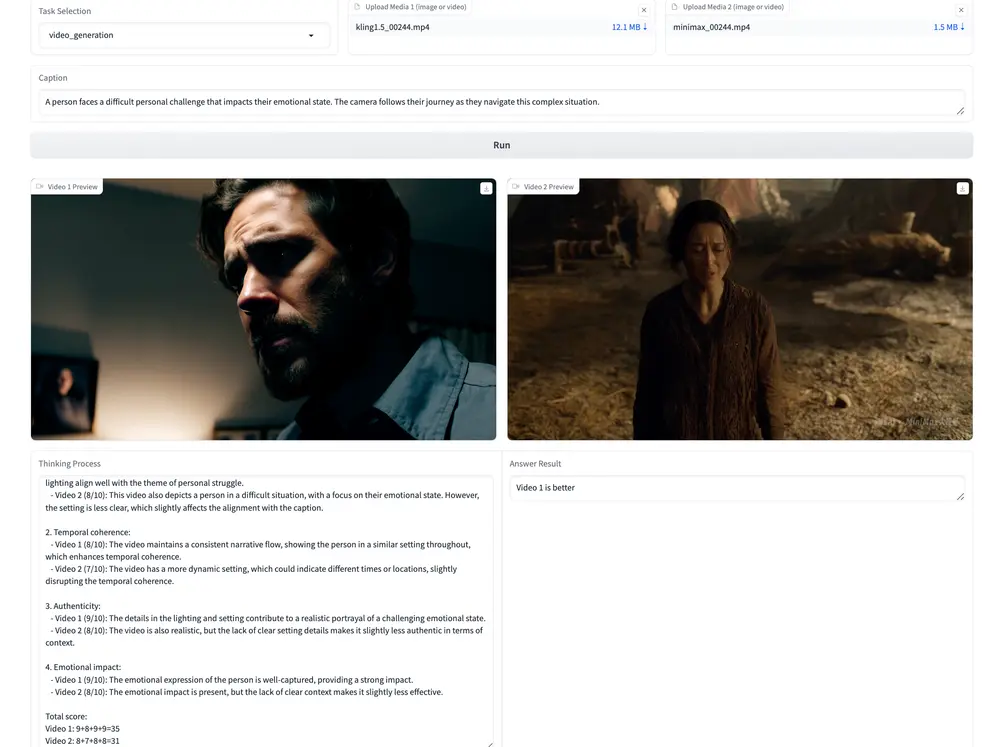
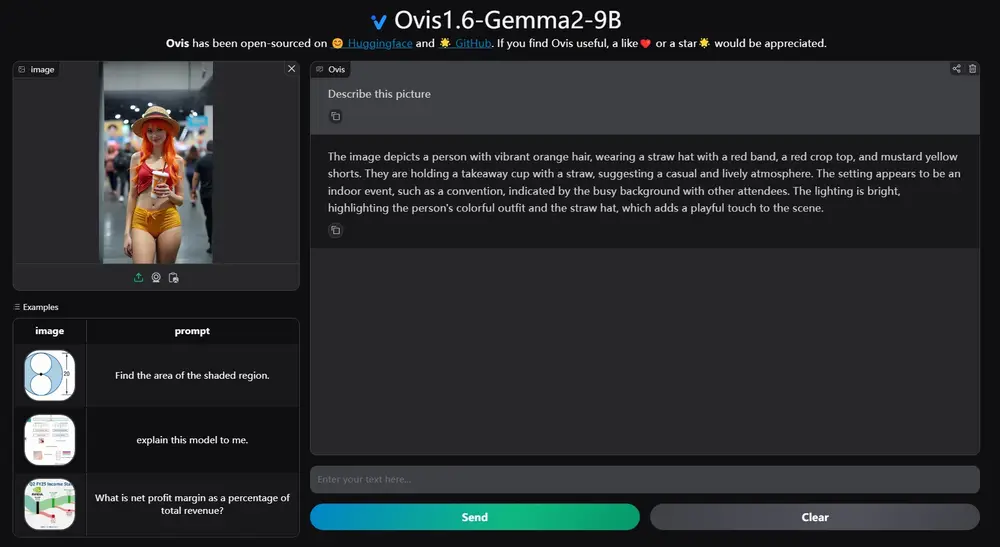
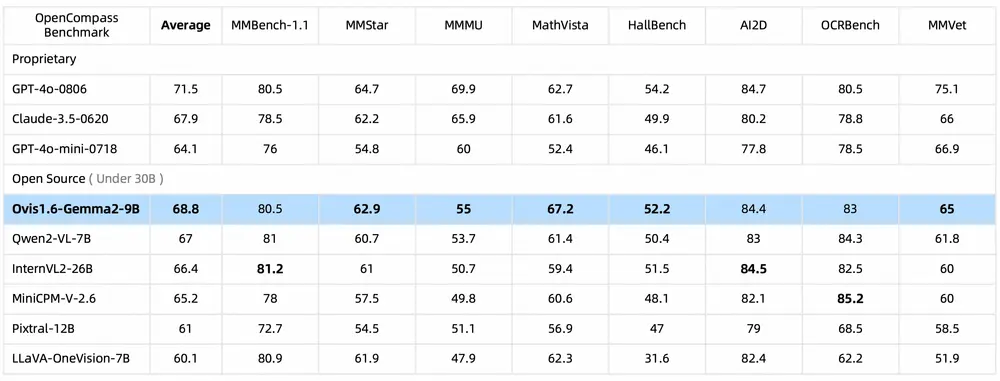
Ovis1.6-Gemma2-9B是阿里国际推出的一款多模态大语言模型,Ovis是一种新颖的多模态大语言模型(MLLM)架构,旨在结构化地对齐视觉和文本嵌入。Ovis1.6-Gemma2-9B基于Ovis1.5构建,Ovis1.6进一步增强了高分辨率图像处理,训练于更大、更多样化和更高质量的数据集,并通过遵循指令调优的DPO训练改进了训练过程。
主要功能:
- 结构化嵌入对齐:Ovis通过一种特别的方法,让模型在处理图片和文本时使用类似的结构化嵌入方式,这就像是给视觉信息和文本信息都贴上了易于理解的标签,使得它们能够更好地融合和交流。
- 多模态学习:它能够学习图片和文本之间的关系,从而更好地理解和生成描述图片内容的文本。
主要特点:
- 视觉嵌入表:Ovis引入了一个视觉嵌入表,这就像是给每个视觉元素(比如图片中的一个部分)一个特定的“身份证”,以便模型能够识别和使用这些元素。
- 概率化的视觉嵌入:模型会计算每个视觉元素与嵌入表中各个“身份证”的相似度,形成一个概率分布,这增加了模型处理视觉信息的灵活性。
工作原理:
Ovis首先将图片分割成多个小块,称为“视觉补丁”。然后,它为每个视觉补丁分配一个概率分布,这个分布表明了该补丁与嵌入表中各个视觉词的相似度。通过这种方式,每个视觉补丁可以与嵌入表中的多个视觉词相关联,形成一个综合的视觉嵌入。这类似于文本处理中的嵌入查找,但用于视觉信息。
具体应用场景:
- 图像描述:给定一张图片,Ovis能够生成描述这张图片内容的文本。
- 视觉问答:用户可以问模型关于图片的问题,比如“图片中有多少人在骑自行车?”Ovis能够理解问题并给出答案。
- 多模态交互:在需要同时理解文本和视觉信息的场景中,比如帮助视障人士理解图片内容,或者在教育中提供图文结合的学习材料。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











