在视频理解领域,长久以来存在一个巨大的效率悖论:人类只需扫视关键物体就能理解场景,而AI模型却必须像素级地“硬啃”每一帧。这种对时空冗余数据的无差别处理,导致当前的多模态大语言模型(MLLM)在面对长时长、高分辨率(如4K)视频时,不仅算力消耗巨大,甚至根本无法运行。
- 项目主页:https://autogaze.github.io
- GitHub:https://github.com/NVlabs/AutoGaze
- 模型:https://huggingface.co/collections/bfshi/autogaze
- Demo:https://huggingface.co/spaces/bfshi/AutoGaze
今日,来自加州大学伯克利分校、麻省理工学院、Clarifai 和英伟达的研究团队联合推出了 Attend Before Attention 框架及其核心模块 AutoGaze。这项研究模仿人类视觉系统的“扫视”(Saccade)机制,通过在数据进入大模型之前主动剔除冗余信息,实现了视觉词元(Token)减少 4-100 倍,并将推理速度提升最高 19 倍。这使得将 MLLM 扩展至 1000 帧、4K 分辨率 的视频成为现实。
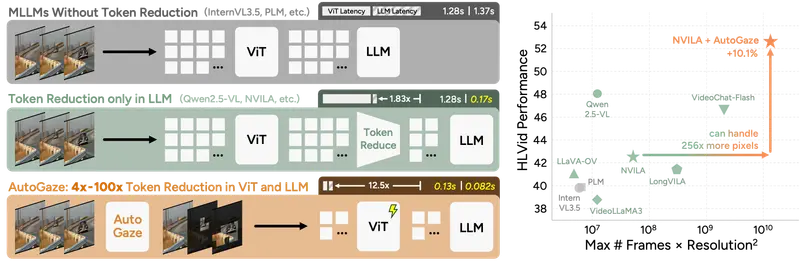
核心理念:像人眼一样“选择性关注”
当人类观察移动场景时,眼球会快速跳动(扫视),聚焦于移动物体或细节丰富区域,而自动忽略静态背景。这种机制让我们能实时处理高帧率视频流。
AutoGaze 正是这一生物机制的算法化实现:
- 前置过滤:它是一个轻量级模块(仅300万参数),部署在视频送入 ViT 或 MLLM 之前。
- 智能剔除:自回归地选择一组最小子集块,这些块足以重建视频的关键信息,同时移除大量冗余背景。
- 多尺度感知:能够根据细节需求,动态选择不同尺度的图像块(从粗略背景到精细物体)。
技术架构:自回归凝视与强化学习
AutoGaze 由一个卷积编码器和一个自回归 Transformer 解码器组成,其训练过程分为两个精妙的阶段:
1. 预训练:模仿人类凝视
通过下一词元预测(Next-Token Prediction),让模型在真实的人类凝视序列数据上进行学习,初步掌握“看哪里”的规律。
2. 后训练:强化学习优化
引入强化学习(RL),以重建奖励为目标。模型不断尝试不同的凝视策略,寻找那些能以最少块数实现最低重建损失的序列。这使得 AutoGaze 能发现超越人类习惯的、更高效的机器视觉路径。
关键特性
- 多尺度词表:解码器包含四个尺度的块,可灵活适配不同细节级别的区域。
- 自回归选择:当前帧的块选择依赖于前一帧的选择,确保时间维度上的连贯性。
- 泛化能力强:不仅能处理常规视频,还能完美适应监控录像、机器人视角、前景频繁切换甚至带有剧烈摄像机运动的复杂场景。
性能飞跃:从“不可用”到“实时4K”
实验数据表明,AutoGaze 在效率与质量之间取得了惊人的平衡:
| 指标 | 表现 | 意义 |
|---|---|---|
| 词元压缩率 | 4x - 100x | 大幅降低显存占用,使长视频处理成为可能 |
| ViT 推理加速 | 最高 19倍 | 显著缩短预处理时间 |
| MLLM 推理加速 | 最高 10倍 | 让大模型回答视频问题的速度提升一个量级 |
| 支持规格 | 1000帧 / 4K | 突破现有模型对长度和分辨率的限制 |
| 精度损失 | < 0.5% | 在0.7重建损失阈值下,性能几乎无损 |
定性结果显示:AutoGaze 能精准聚焦移动物体,在场景变化时自动增加采样密度,并在静态背景处极度稀疏化。即使在摄像机剧烈运动的情况下,其重建质量依然保持高位。
HLVid:首个高分辨率长视频基准测试
为了验证这一突破,研究团队还发布了 HLVid —— 业界首个专为高分辨率、长时长视频设计的问答基准测试。
- 规模:包含300对基于 5分钟、4K分辨率 视频的问答对。
- 难度:所有问题均经人工审核,确保必须依赖高分辨率细节和对全视频的理解才能回答,杜绝了“猜谜”可能。
测试结果:
在 HLVid 上,集成了 AutoGaze 的多模态大模型(基于 NVILA-8B 扩展)相比基线模型,性能提升了 10.1%。在与其他强大模型(如 Qwen2.5-VL)的对比中,扩展后的模型在多个视频基准测试上均取得了最优结果(SOTA)。
行业意义:视频理解的“瘦身”革命
Attend Before Attention 框架的提出,解决了视频理解领域长期存在的“算力墙”问题:
- 打破分辨率限制:让消费级显卡也能跑通4K长视频分析,推动了高清视频监控、医疗影像分析等应用的落地。
- 延长上下文窗口:使模型能“看完”整部电影而非仅片段,为长视频内容理解、剧情分析打开了大门。
- 降低部署成本:10-19倍的加速意味着云端推理成本的断崖式下降,让实时视频AI服务变得经济可行。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











