在文档数字化处理领域,兼顾高精度转录、轻量化部署、高效推理的OCR模型一直是行业刚需。LightOn AI推出的第二代模型 LightOnOCR-2-1B,以1B参数量实现端到端PDF文档转写能力,不仅无需依赖多阶段流水线,还能输出嵌入式图形的边界框信息,更在OlmOCR基准测试中超越9B量级的Chandra模型,成为兼具性能与效率的轻量级OCR解决方案。
- 模型:https://huggingface.co/collections/lightonai/lightonocr-2
- Demo:https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo
核心亮点:1B参数实现“性能+速度”双重突破
LightOnOCR-2-1B相较于初代模型实现全方位升级,核心优势集中体现在精度、速度和实用性三大维度:
- 精度领先,参数量更轻
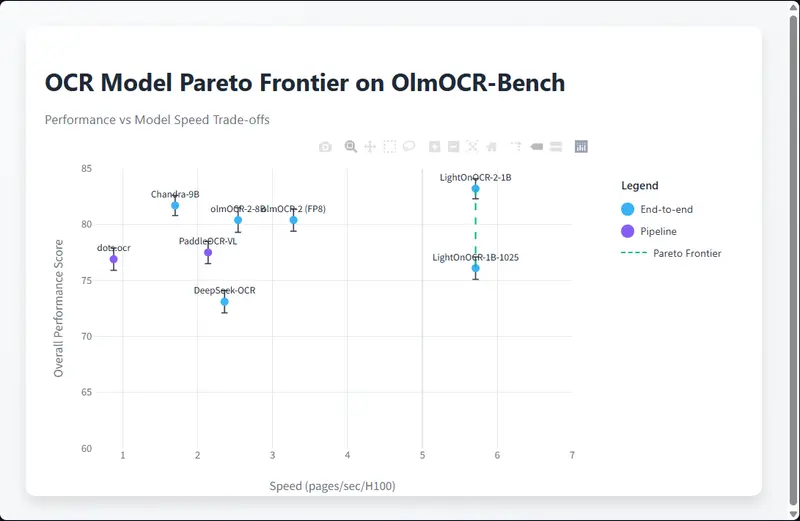
在OlmOCR基准测试中,该模型以83.2 ± 0.9的得分登顶,整体性能超过Chandra-9B模型1.5个百分点以上,而参数量仅为后者的1/9,彻底打破“大参数=高性能”的固有认知;尤其在ArXiv论文、老旧数学扫描件、表格等复杂场景下表现突出,这得益于更优质的训练数据和高分辨率训练方案。 - 推理高效,适配大规模流水线
专为生产环境设计的高效架构,让模型推理速度远超同类产品:比Chandra OCR快3.3倍、比OlmOCR快1.7倍、比dots.ocr快5倍、比PaddleOCR-VL-0.9B快2倍,可直接嵌入大规模文档处理流水线,兼顾吞吐量与准确性。 - 功能多元,覆盖多场景需求
除了高精度文本转录,还提供边界框输出能力,可定位文档中嵌入式图形/图像的位置,满足需要轻量级布局信息的工作流程;同时发布多版本模型变体,适配不同业务需求。 - 完全开源,支持灵活定制
基于Apache 2.0许可证开源,同时发布完整模型家族与训练数据集,支持社区进行微调、领域适配和布局相关应用开发。
模型家族全览:按需选择,精准匹配业务场景
LightOnOCR-2并非单一模型,而是包含多个变体的模型家族,每个版本针对性强化不同能力,避免“功能堆砌”导致的性能损耗:
| 模型变体 | 核心能力 | 适用场景 |
|---|---|---|
| LightOnOCR-2-1B(默认) | 纯OCR转录,精度最优 | 绝大多数PDF转干净文本/Markdown的场景,优先保证转录质量 |
| LightOnOCR-2-1B-bbox | OCR转录+图形边界框定位 | 需要提取文本同时定位嵌入式图像/图形的场景 |
| LightOnOCR-2-1B-bbox-soup | 平衡OCR精度与边界框性能 | 对文本转录和图形定位都有需求的折中场景 |
| LightOnOCR-2-1B-base | 基础OCR模型,无后训练优化 | 开发者基于自有数据微调、合并或研究后训练方案 |
| LightOnOCR-2-1B-bbox-base | 带边界框能力的基础模型 | 针对布局相关任务进行二次开发或RLVR训练 |
| LightOnOCR-2-1B-ocr-soup | OCR与边界框能力融合权衡 | 追求功能全面性的定制化场景 |
开源资源配套:数据集+工具链,降低开发门槛
为了方便社区使用和二次开发,LightOn AI同步发布了完善的配套资源:
- 开放高质量训练数据集
lightonai/LightOnOCR-mix-0126:包含超1600万高质量标注的文档页面,覆盖多类型文档场景;lightonai/LightOnOCR-bbox-mix-0126:包含近50万标注样本,附带图形/图像边界框信息,支持布局相关任务训练。
- 原生支持Hugging Face Transformers生态
模型已无缝集成到Transformers上游,带来三大便利:- 无需依赖vLLM,直接使用标准Transformers工具运行;
- 支持LoRA/PEFT/Trainer等主流微调方案,降低定制化开发成本;
- 支持CPU/本地运行,低配设备也能完成轻量级任务,摆脱“仅GPU可用”的限制。
关键基准表现:小模型吊打大模型的核心数据
LightOnOCR-2-1B的性能优势在量化测试中体现得淋漓尽致,核心指标对比如下:
| 测试维度 | 指标数据 | 对比优势 |
|---|---|---|
| 转录精度(OlmOCR-Bench) | 83.2 ± 0.9 | 超越Chandra-9B 1.5个百分点,位列同类模型第一 |
| 推理速度(每秒处理页面数) | 远超同类模型 | 比Chandra OCR快3.3倍,适配大规模文档流水线 |
| 参数量级 | 1B | 仅为Chandra-9B的1/9,部署成本大幅降低 |
| 复杂场景表现 | ArXiv/数学扫描件/表格转录精准 | 针对性优化训练数据,解决专业文档转录痛点 |
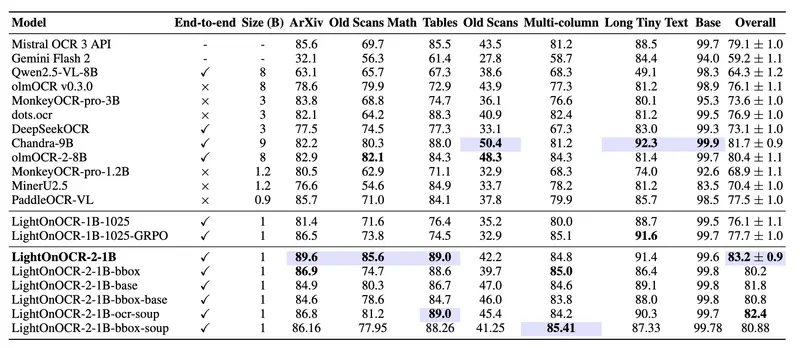
表 1:OlmOCR-Bench 结果(排除页眉/页脚类别)。每列最佳以蓝色突出显示,次佳加粗。结果取自相应已发表作品;我们额外评估了 DeepSeekOCR 和 Mistral OCR 3 API,因为它们未报告 OlmOCR-Bench 数字。
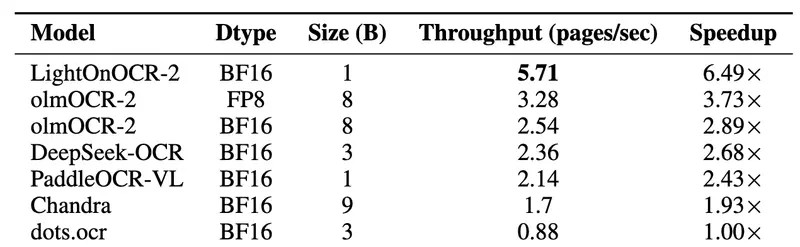
表 2:在单个英伟达H100(80GB)上的推理吞吐量。
典型应用场景:覆盖从个人到企业的全链路需求
凭借轻量级、高精度、易部署的特性,该模型可适配多样化的文档处理需求:
- 企业级文档数字化:嵌入金融、法律、政务等行业的大规模文档流水线,快速完成合同、报表、档案的文本提取,兼顾效率与准确性;
- 学术文献处理:精准识别ArXiv论文、老旧学术扫描件中的公式、表格和文本,助力学术数据库建设;
- 开发者二次开发:基础模型支持微调与合并,开发者可针对特定领域(如医疗病历、工程图纸)定制专用OCR模型;
- 个人轻量化使用:支持本地CPU运行,满足小批量文档转写需求,无需依赖云端算力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











