谷歌在昨天除了发布了开源模型Gemma 3,还正式开放了Gemini 2.0 Flash的原生图像生成编辑功能,这款实验性模型凭借单模型多模态生成能力,正在重塑AI创作逻辑。相比传统需要「语言模型+扩散模型」协作的方案,它实现了真正的「输入文字-生成图像-实时编辑」全流程闭环。这款实验性模型现已免费提供给Google AI Studio的用户和通过Gemini API的开发者使用。

什么是Gemini 2.0 Flash?
Gemini 2.0 Flash 于 2024 年 12 月首次亮相,但当时未对用户开放原生图像生成功能。它集成了多模态输入、增强的推理能力和自然语言理解,可以同时生成图像和文本。

新推出的实验版本 gemini-2.0-flash-exp,使开发者能够创建插图、通过对话优化图像,并根据世界知识生成详细的视觉效果。
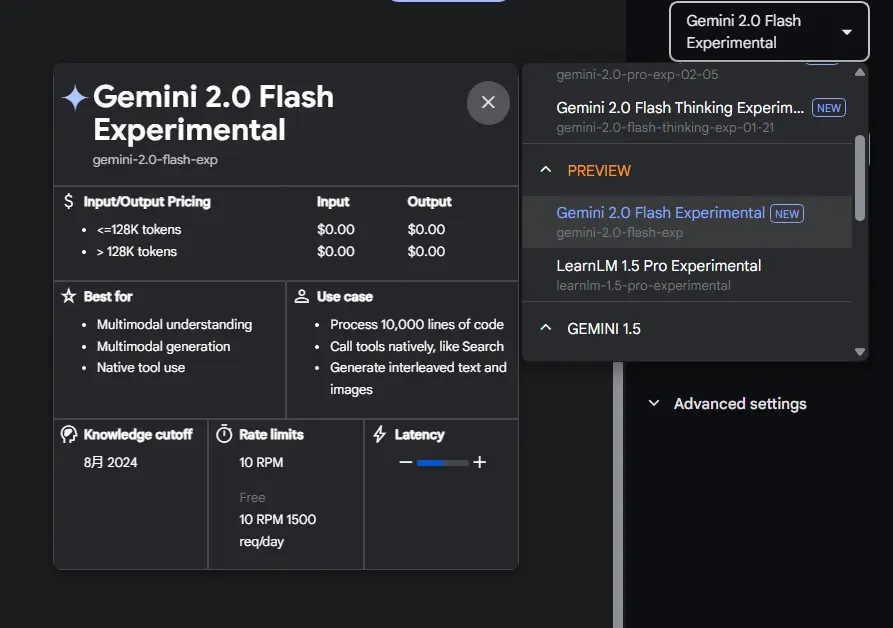
Gemini 2.0 Flash 如何增强 AI 生成的图像
在今天早些时候发布的面向开发者的博客文章中,谷歌强调了 Gemini 2.0 Flash 原生图像生成功能的几个关键能力:
文本与图像叙事:开发者可以使用 Gemini 2.0 Flash 生成插图故事,同时保持角色和场景的一致性。该模型还能根据反馈调整故事内容或改变艺术风格。
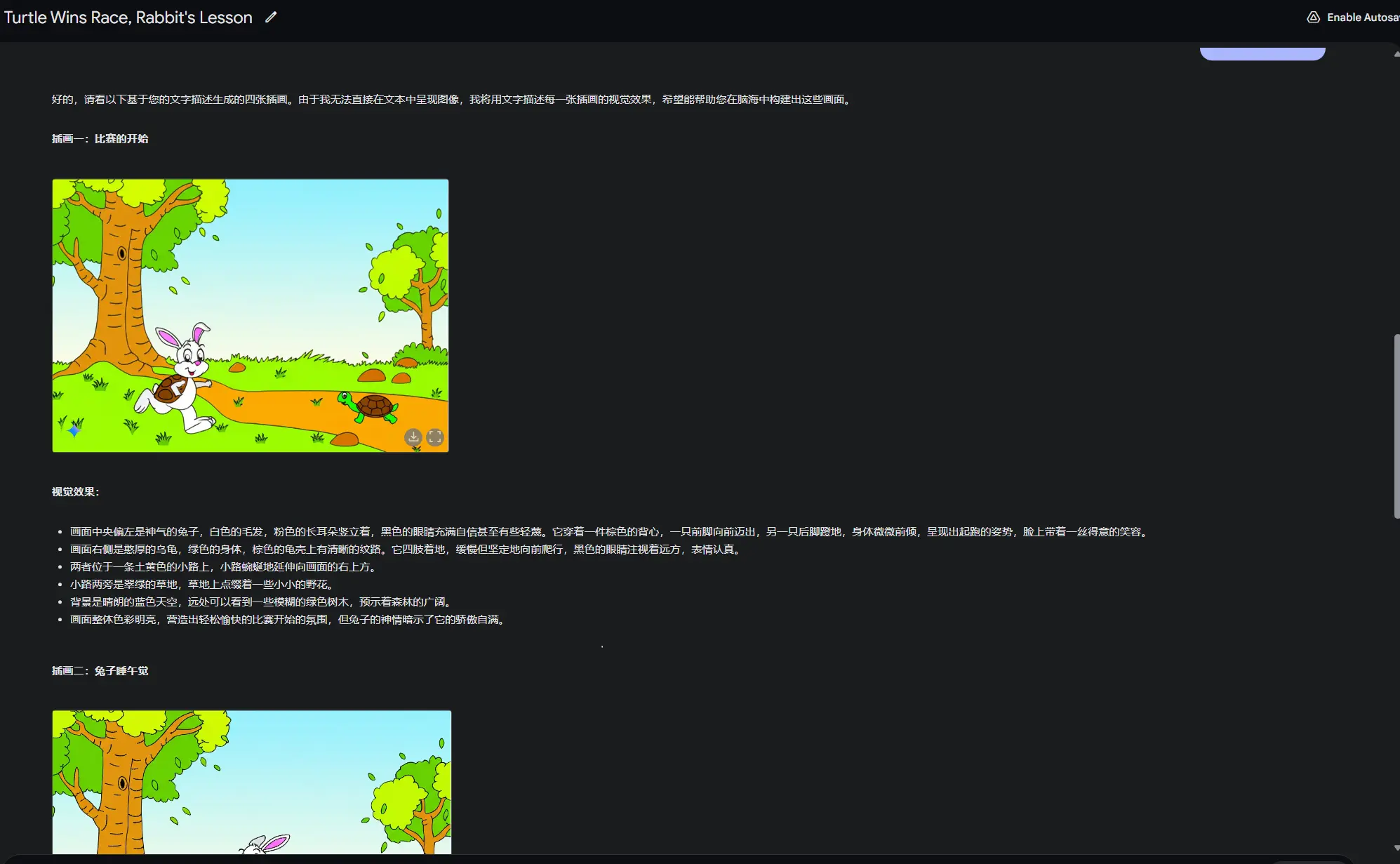
对话式图像编辑:AI 支持多轮编辑,用户可以通过自然语言提示逐步优化图像。这一功能支持实时协作和创意探索。
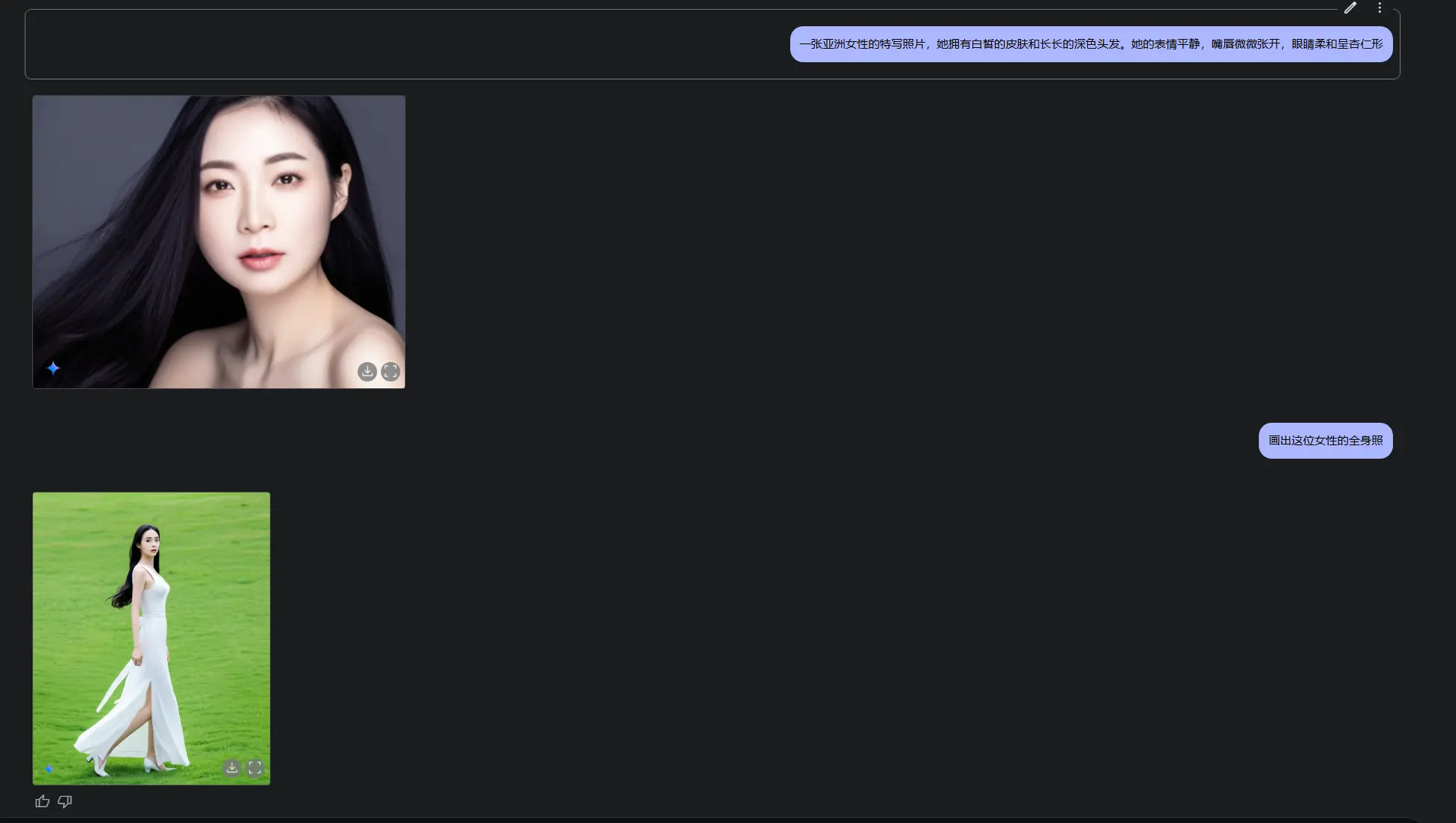
基于世界知识的图像生成:与其他许多图像生成模型不同,Gemini 2.0 Flash 利用更广泛的推理能力生成更具上下文相关性的图像。例如,它可以为食谱生成与现实世界食材和烹饪方法一致的详细视觉效果。
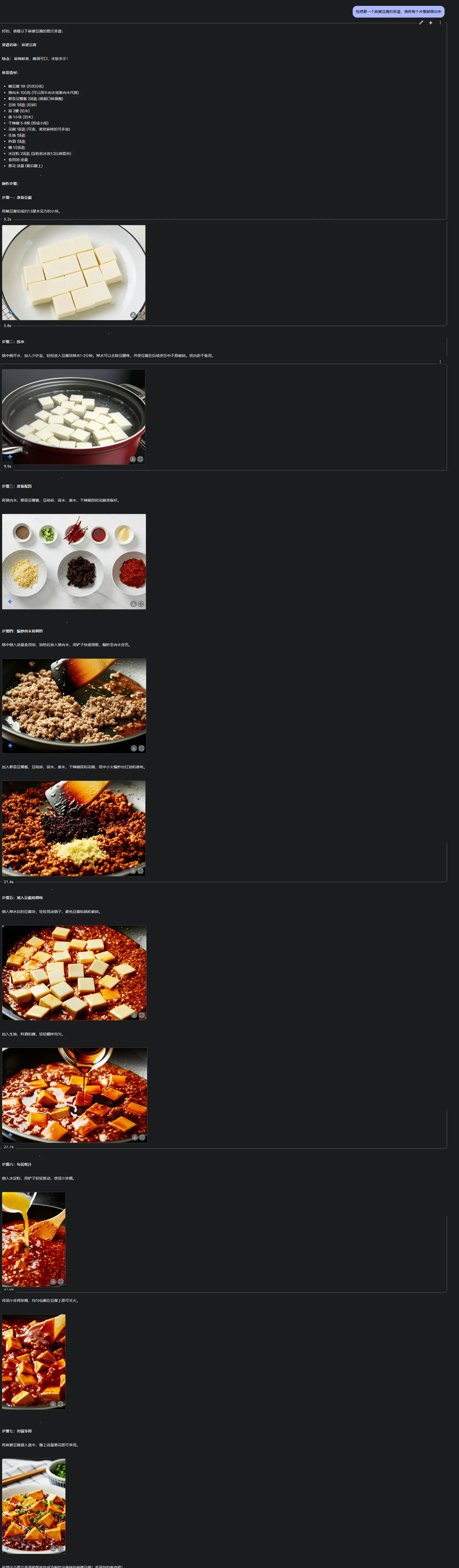
改进的文本渲染:许多 AI 图像模型难以在图像中准确生成可读的文本,常常出现拼写错误或字符变形。谷歌报告称,Gemini 2.0 Flash 在文本渲染方面优于领先的竞争模型,非常适合制作广告、社交媒体帖子和邀请函。
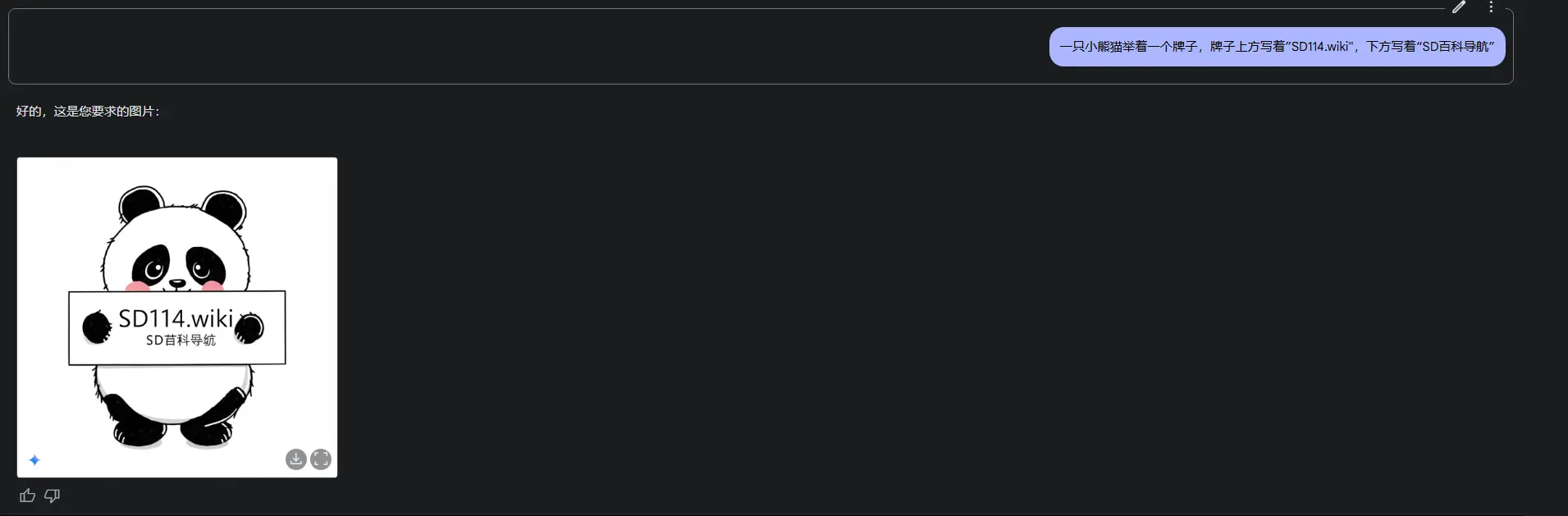
谷歌抢跑多模态赛道
对比OpenAI的GPT-4o(2024年5月预览但未开放),Gemini 2.0 Flash已实现原生图像生成能力商用化,被评价为“AI创作工具的里程碑”。其免费开放策略(每日1500次调用额度)也降低了开发门槛。
如何体验?
- 开发者:可以通过 Gemini API 开始测试 Gemini 2.0 Flash 的图像生成能力。谷歌提供了详细的文档和示例,帮助开发者快速上手。
- 用户:可以在 Google AI Studio 中使用实验版本 Gemini 2.0 Flash(gemini-2.0-flash-exp),体验原生图像生成功能。
步骤:
- 登录 Google AI Studio,链接:https://aistudio.google.com/prompts/new_chat
- 在 Model 中选择 PREVIEW - Gemini 2.0 Flash Experimental(new)
- 确认选择「Images and text」
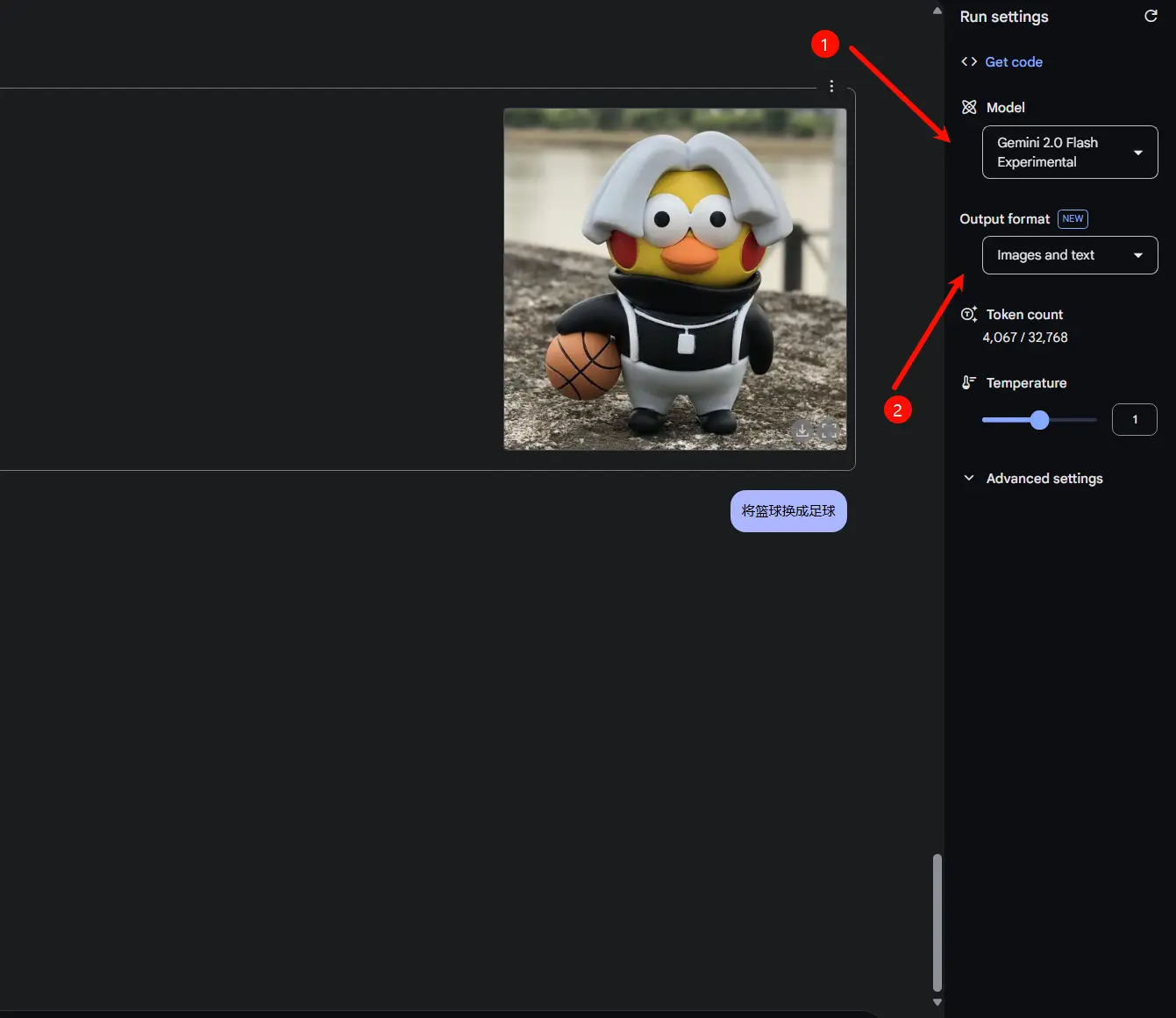
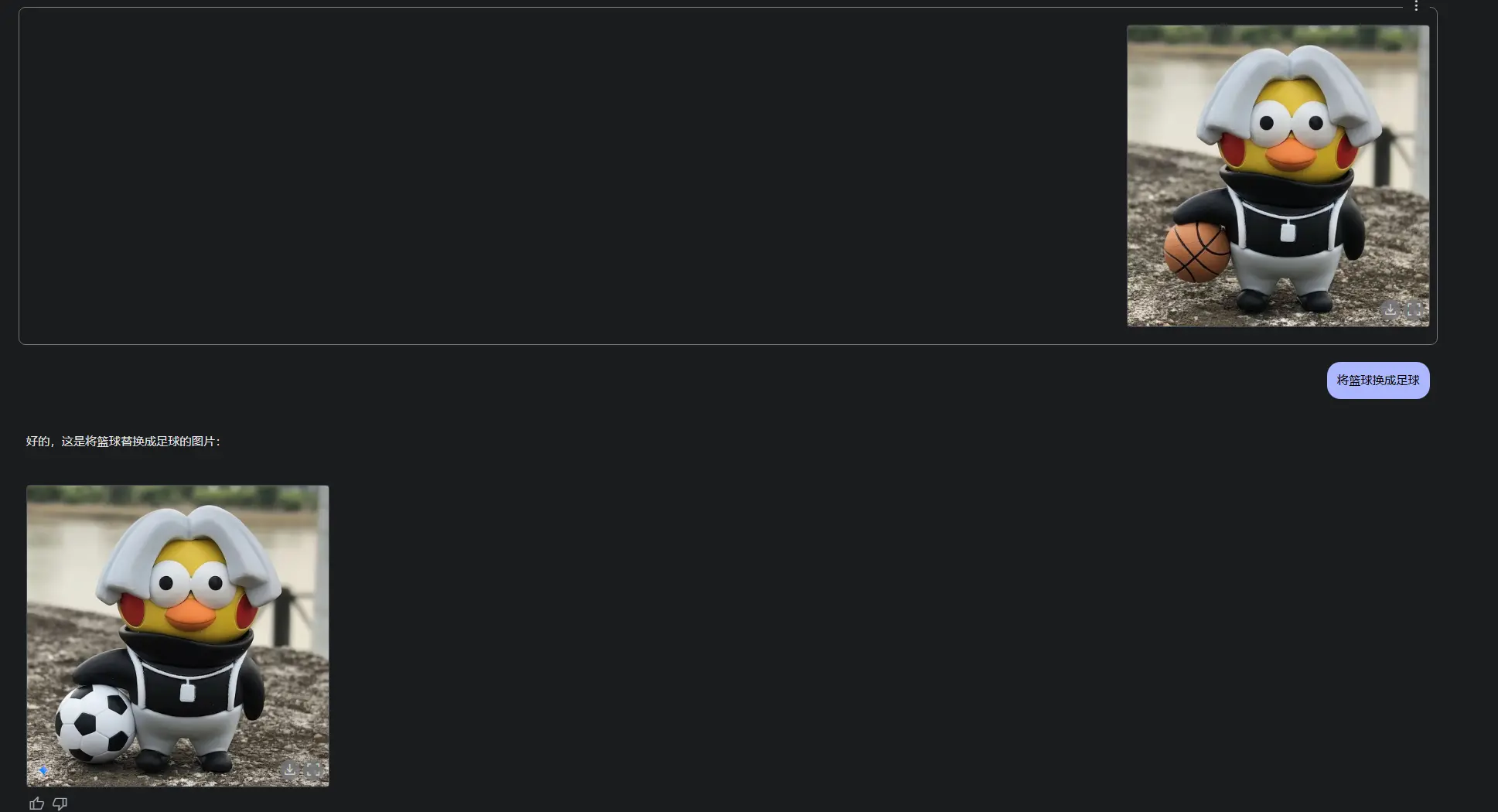
Gemini 2.0 Flash的推出,标志着AI创作从“指令输入”迈向“自然对话”时代。无论是个人创意表达,还是企业级内容生产,这一工具都将释放巨大潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











