
来自Snap、特伦托大学、加州大学默塞德分校、布鲁诺·凯斯勒基金会的研究人员推出新型视频生成模型Snap Video,此模型基于Transformer架构,目标是将文本描述转换成高质量的视频内容。
它通过改进现有的图像生成技术,特别关注视频的时空特性,以生成具有连贯动作和高视觉质量的视频。相对于U-Net,其训练速度比U-Net快3.31倍,并且在推理时也快了约4.5倍。
主要功能:
- 将文本描述转换为动态视频。
- 生成具有高分辨率和复杂动作的视频。
- 保持视频中的动作和场景的时空一致性。
主要特点:
- 采用“视频优先”的方法,专门针对视频内容的冗余性和动态特性进行优化。
- 使用了一种新的基于Transformer的架构,这种架构在训练和推理时都比传统的U-Net架构更快。
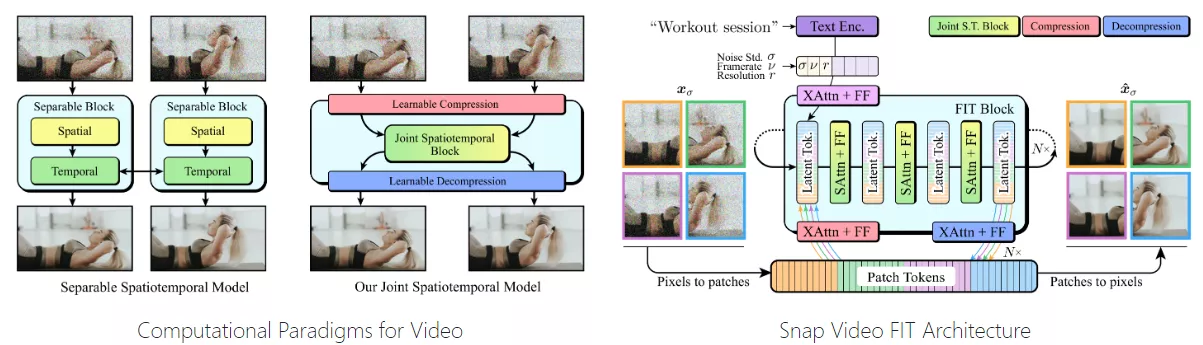
- 通过联合时空视频建模,能够在保持大规模文本到视频生成器的语义控制能力的同时,生成具有高动作复杂性的视频。
工作原理:
- 首先,Snap Video扩展了现有的EDM(能量扩散模型)框架,以考虑视频帧之间的空间和时间冗余。
- 然后,它提出了一种新的基于FIT(Far-reaching Interleaved Transformers)的架构,这种架构能够高效地处理视频数据,并且能够扩展到数十亿参数的规模。
- 在训练过程中,模型通过学习视频的压缩表示,能够在保持视频质量的同时,提高计算效率和模型的可扩展性。
- 在推理阶段,模型能够从高斯噪声中生成视频样本,并且通过用户提供的文本条件信息来指导生成过程。
Snap Video模型与其他现有的文本到视频生成模型相比,具有几个显著的优势和特点:
- 时空一致性:Snap Video通过联合时空视频建模,能够生成具有高度时空一致性的视频。这意味着视频中的动作和场景变化更加自然和连贯,避免了一些模型常见的问题,如动作不连贯或场景中的物体突然消失。
- 高分辨率输出:Snap Video能够生成高分辨率的视频内容。这得益于其采用的两阶段级联模型,第一阶段生成低分辨率视频,第二阶段进行上采样以产生高分辨率输出。这与一些其他模型相比,能够提供更清晰、更详细的视频质量。
- 训练和推理效率:Snap Video使用的基于FIT的架构在训练和推理时都比传统的U-Net架构更快。这使得模型能够处理更大规模的数据集,并且在生成视频时具有更高的效率。
- 可扩展性:Snap Video模型能够扩展到数十亿参数的规模,这在以往的文本到视频生成模型中是不常见的。这种可扩展性使得模型能够捕捉更复杂的动态和细节,从而提高生成视频的质量。
- 用户研究:在用户研究中,Snap Video在多个方面(如真实感、视频与文本对齐、动作数量和质量)都优于最新的开放源代码方法。用户更倾向于选择Snap Video生成的视频,这表明其在实际应用中的潜力。
- 处理复杂动作:Snap Video特别擅长处理包含复杂动作的视频,如快速移动的物体和大型相机运动。这与其他一些模型相比,后者可能在处理这类场景时产生闪烁或时间不一致的伪影。
- 生成质量:在定量评估中,Snap Video在多个基准测试上达到了最先进的性能,特别是在生成动作的质量方面。
Snap Video在视频生成的多个关键方面都显示出了其优越性,包括视频质量、动作建模能力、训练和推理效率,以及用户接受度。这些特点使其成为一个强大的工具,适用于需要高质量视频内容的各种应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











