
索尼推出新型音频-视觉生成模型Visual Echoes,这个模型能够根据一张图片生成与之相对应的音频,或者反过来,根据一段音频生成匹配的图片。这种技术在多模态生成领域具有很大的潜力,因为它能够将视觉和听觉信息结合起来,创造出更加丰富和互动的体验。例如,你正在制作一个关于自然景观的视频,你可以使用Visual Echoes模型根据视频的静态帧生成相应的环境声音,或者根据一段自然声音生成一系列与之匹配的景观图像。
主要功能和特点:
- 轻量级和简单性:Visual Echoes模型是一个轻量级的生成变换器,它在多模态生成任务中表现出色,尤其是在图像到音频(image2audio)的生成上。
- 无需额外训练:经过训练后,该模型可以直接应用于音频到图像(audio2image)的生成以及共同生成(co-generation),无需额外的训练或修改。
- 模态对称性:由于变换器模型在模态上是对称的,它可以很容易地部署用于双向生成任务。
- 分类器自由引导(Classifier-free Guidance, CFG):可以部署现成的分类器自由引导来提高性能,无需额外的训练。
工作原理:
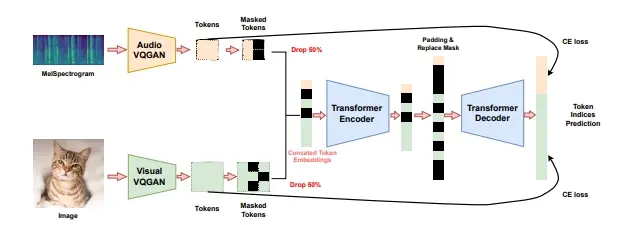
- Visual Echoes模型在离散的音频和视觉向量量化GAN(Vector-Quantized GAN, VQGAN)空间中操作,并采用掩码去噪的方式进行训练。
- 模型首先将成对的图像/音频数据编码成离散的令牌,然后通过变换器模型输入这些令牌的连接。
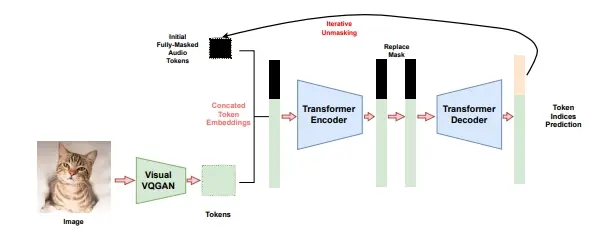
- 通过迭代推断策略,模型学会生成能力,实现图像到音频的生成,同时也支持音频到图像的生成和共同生成。
具体应用场景:
- 艺术创作:艺术家可以使用Visual Echoes根据图像创造音频,或者根据音频创造图像,以增强他们的作品。
- 多媒体内容生成:在电影、游戏和虚拟现实制作中,该模型可以根据场景生成匹配的音频或图像,提高制作效率。
- 辅助工具:对于视觉或听觉有障碍的人士,Visual Echoes可以作为辅助工具,将图像转换成音频或反之,帮助他们更好地感知世界。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











