
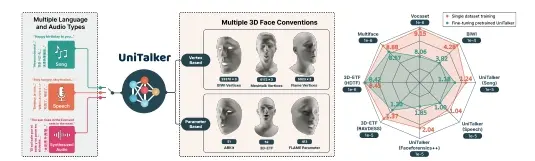
商汤科技推出UniTalker,它是一个用于3D面部动画的统一模型,能够根据输入的音频生成逼真的面部动作。这项技术在动画制作、虚拟现实、游戏开发等领域具有广泛的应用前景。UniTalker是一种统一的多头架构模型,旨在有效利用带有不同标注的数据集。为了增强训练的稳定性并确保多头输出之间的一致性,研究团队采用了三种训练策略:主成分分析(PCA)、模型预热以及枢轴身份嵌入。为了扩大训练规模和多样性,研究团队构建了A2F-Bench,该基准包含了五个公开可用的数据集和三个新编纂的数据集。这些数据集涵盖了广泛的音频领域,包括多语言语音和歌曲,从而使训练数据从通常使用的不到1小时扩展到了18.5小时。
通过单个训练好的UniTalker模型,在BIWI数据集上实现了9.2%的唇部顶点误差减少,在Vocaset数据集上实现了13.7%的减少。此外,预训练的UniTalker展现出了作为音频驱动面部动画任务的基础模型的巨大潜力。在已知数据集上对预训练的UniTalker进行微调可以进一步提升每个数据集上的性能,在A2F-Bench上平均误差减少了6.3%。更值得一提的是,在只有半量数据的未知数据集上微调UniTalker,其性能超过了在完整数据集上训练的先前最先进的模型。
例如,你正在观看一部动画片或者玩一款视频游戏,里面的人物需要根据他们的对话或者歌声来做出相应的面部表情。以前,这可能需要专业的动画师或者复杂的设备来捕捉真人的表情,然后应用到3D模型上。现在,有了UniTalker,只需要录制人物的声音,这个技术就能够自动让3D模型的面部动起来,就像真人一样自然。
主要功能:
- 音频驱动的3D面部动画:根据输入的音频(如语音或歌声)生成相应的3D面部动作。
- 多语言和多音频类型支持:能够处理不同语言的语音和不同类型的音频,包括歌曲。
- 统一模型:整合了多种数据集和注释类型,能够在一个统一的框架内进行3D面部动画生成。
主要特点:
- 多头部架构:设计有多个输出头,可以同时输出不同3D面部注释约定的动画。
- 训练稳定性:采用PCA(主成分分析)、模型预热和枢纽身份嵌入等训练策略,确保多头部输出的一致性和训练过程的稳定性。
- 大规模数据集:通过结合多个公开数据集和新策划的数据集,大幅扩展了训练数据的规模和多样性。
工作原理:
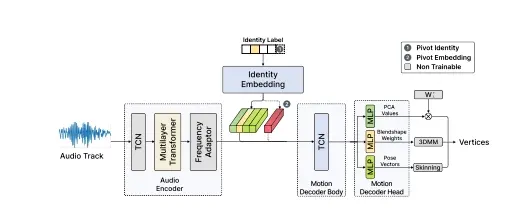
- 音频编码器:将输入的音频转换成上下文化的音频特征。
- 频率适配器:通过时间线性插值调整音频特征的频率,以匹配输出面部动作的频率。
- 非自回归运动解码器:将插值后的音频特征映射成运动隐藏状态,然后解码到每个注释约定。
- 身份嵌入:为了模拟不同个体的说话风格,面部动作生成依赖于输入的身份标签。
具体应用场景:
- 动画制作:为动画角色生成逼真的面部表情和口型同步。
- 虚拟现实:在VR环境中,根据用户的语音指令生成相应的面部动作。
- 游戏开发:为游戏中的非玩家角色(NPC)生成自然的面部表情和动作。
- 语言学习:生成特定语言的口型和表情,帮助学习者模仿发音和表情。
UniTalker通过其先进的技术,不仅提高了3D面部动画的生成质量,还加快了生成速度,使得在多种应用场景下都能够实现高效且逼真的面部动画生成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











